這幾天我們都在「靜態」的情況下建構倒排索引,文集中的文件數不變、空間使用不會有太大變化,也沒有及時新增或修改。即便如此,要建構這樣的靜態索引還是可能會出現一些難題,例如:記憶體的容量有限,假如我們爬下了1TB(真實世界中的資料量往往遠超於此)的資料,不太可能同時將這些資料全部塞進記憶體中。這樣,我們該怎麼建構我們的索引呢?
分而治之法!這是演算法中一個經典的解題方式,在這裡也同樣能夠應用。我們可以將文件集根據文件數分割成多個區塊,每一個區塊建構一段自己的索引,最後在硬碟(而不是記憶體)中將所有索引結合在一起。

大家可以一睹此演算法,在第五行將文件從文集中一塊一塊取出來,第七行用輔助函式來建構這一塊文件的索引,第八行存進硬碟中。將整個文件集循過之後,第十一行將已經存在硬碟中的所有子索引合成最終索引。
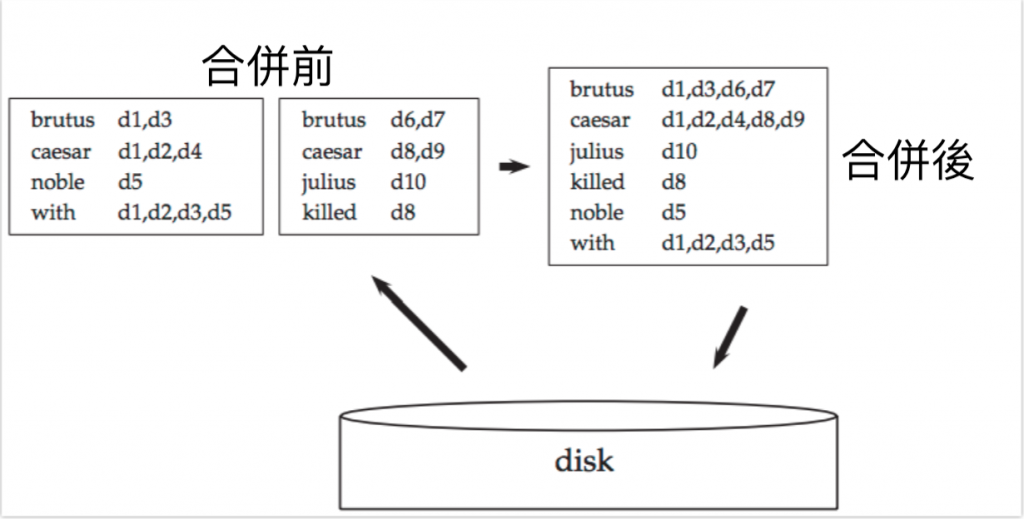
圖片中最左邊的列表是以文件1~5為區塊,中間的列表則以文件6~10為區塊,最右邊將這些列表合併後,再次存回硬碟中。
然而,正常的搜尋引擎索引不該是靜態的,該要能夠應付隨時增加的新資料。應對的方法就是將資料存成兩個索引,第一個索引是相對靜態的大索引,就是我們剛才所說,存在硬碟中的索引;第二個索引我們將它存在記憶體中,每當有新文件進來時,我們就將它存到記憶體中。當第二個索引長到太大時,我們再將他合併到硬碟的第一個大索引中。查詢階段,我們會同時查詢兩個索引,最後合併查詢結果。這就是在實務中的索引建構方式,這個影片會讓大家更有概念。


 iThome鐵人賽
iThome鐵人賽