今明兩天要來說說,我們可以如何判斷和評估一個搜尋引擎的效果。
先從三個在統計學和機器學習領域基礎而重要的評估方式說起:準確率(Accuracy)、精確率(Precision)、以及召回率(Recall)。我們用一個例子來說明,
假如在一個100人的班上發生了群聚流感,有20個人中鏢,所幸其餘80人安然無恙。老師為了掌握學生的狀況,帶著大家去快篩,結果如下:
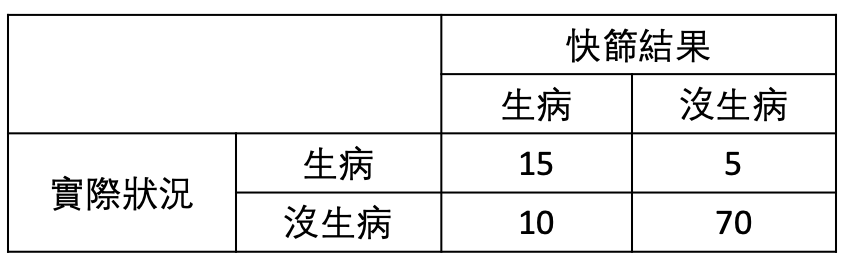
這時我們就可以計算數據:
在搜尋引擎當中,「快篩結果」就是我們回傳給使用者的文件,而「實際狀況」就是文件究竟是不是他們在尋找的東西(相關與否)。在搜尋引擎評估中,精確率通常比召回率更好計算,我們來想想看為什麼?精確率取的是「所有回傳給使用者的文件中,實際上使用者需要的文件」;另一方面,召回率則在尋找「使用者需要的所有文件中,搜尋引擎確實回傳給他們的文件。」這一來一往,我們可能就想到了為什麼計算召回率沒那麼容易:要得知「使用者需要的所有文件」幾乎是天方夜譚。
這三個基礎數據可以幫助我們了解一個搜尋引擎的好壞。明天,我們會討論基礎數據的延伸,幫助我們更進一步的評估一個搜尋引擎。

