昨天說到使用三種統計方法來評估搜尋引擎,分別是準確率、精確率以及召回率。今天我們要接著說到幾個搜尋引擎的衡量指標。
第一個方法稱為Precision@k,它衡量一個搜尋引擎在回傳Top-K個結果時的精確率。對於現代的搜尋引擎來說是個有利的衡量標準,以Google為例,一個頁面預設取得Top-10的查詢結果,那麼我們的Precision@k就可以設定在P@10,並且計算在這十個文件中有多少文件符合了使用者的資訊需求(稱作相關)。
第二個要介紹的是Average Precision (AP)。我發現這個公式不太容易用文字敘述,因此我直接放上在維基百科上的數學公式:
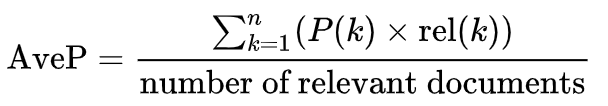
舉例來說,我們現在有一個相關文件向量,1代表相關、0代表無關:
<1, 0, 0, 0, 0, 1, 0, 1, 0, 0>
P@1 = 1/1, P@2 = 1/2, P@3 = 1/3, ..., P@6 = 2/6, P@7 = 2/7, P@8 = 3/8, ...
AP = (P@1 + P@6 + P@8) / 3 = 0.57
AP的好處就是他更看重排名了(Rank sensitive)。
我們可以進一步使用Mean Average Precision (MAP)。這個評估方法是AP的延伸,用來計算多個查詢的AP平均,用以衡量搜尋引擎整體的水準。
第三個來介紹Mean Reciprocal Rank (MRR)。首先,Reciprocal Rank (RR) = 1 / 第一個相關文件的排名
假設有兩個相關文件向量的查詢
<1, 0, 0, 0, 0>以及<0, 0, 1, 0, 1>
第一個向量的RR會是1/1,而第二個向量的RR則是1/3。
這時我們若將這兩個查詢的結果平均,(1+1/3) / 2 = 0.67,這個值也就是MRR。
除了這三個方法之外,仍有許多其他的衡量方法,例如:考慮了使用者耐心的Rank-biased precision
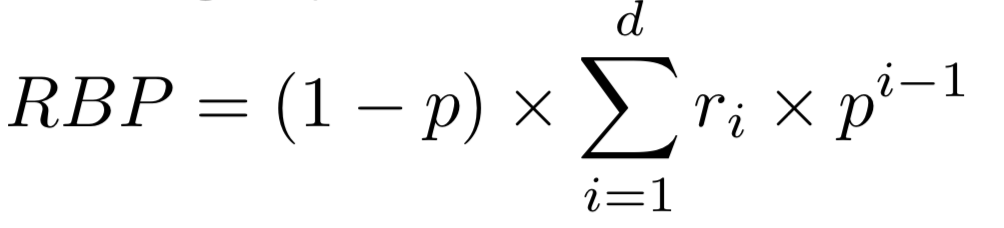
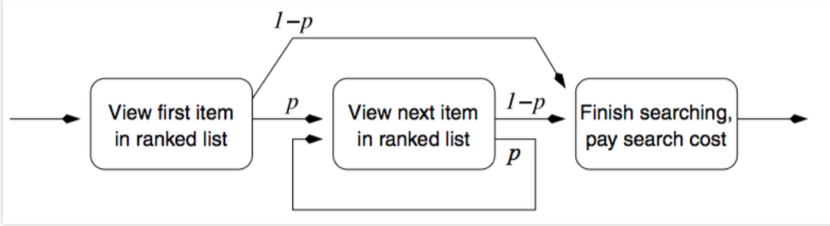
假如有耐心的使用者p=0.95,沒耐心的使用者p=0.5。每一次使用者瀏覽完一個頁面,會根據他的耐心程度來決定會不會看下一個頁面。設計比較好的搜尋引擎會獎勵有耐心的使用者,讓他的耐心有所回報(找到更多相關的文件或頁面),因此RBP也是一種可以採用的搜尋引擎衡量方法。

