面對 QA 或是 CS 反饋回來的 BUG,排查的第一步是製造環境重現它,然後就是要看日誌了 (你這不是廢話嗎)
哈哈,別小看日誌這件事,這幾年它也逐漸搞出一些大學問。
以前我們可能是這樣
$ ssh test@192.168.250.33
[test@dev33]$ cd /opt/logs
[test@dev33]$ ls -l
[test@dev33]$ vi 2019-09-20.log
也許配上 grep / sed / awk 等等 linux 指令
但是呢,當你機器一多起來就很開心了,如果是幾台還好,加一些別名幫助快速下指令。
但如果你是微服務架構甚至可以水平擴展的,那這樣搞肯定是不現實的。
今天就來小談一下這幾年寫日誌這件事的改變好了。
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
Log4j 一代的最後一版,搞不好有些人的專案還在用這個 (笑)
當年這個真的是厲害,那是個在 java.util.Logging 還沒成熟的年代,完全命中需求的一個產品。
可是後來功能日新月異,不敷使用,自然有了 Log4j2,與此同時還有 Logback 還有其他幾個。
但攻城獅們總不能換來換去吧,所以物件導向腦的大家就發明了一個共用介面,Apache Common Logging 和 Simple Logging Facade for Java。
所以你只要面向介面編程,實作的框架理論上就能切來切去。
這邊還可以講個小八卦,Log4j 作者 Ceki Gülcü 同時也是 Slf4j 和 Logback 的作者。簡直堪稱 Java Log 界的狂人
最初這套整合方案一開始只有 Elasticsearch、Logstash 和 Kibana。
在各地的日誌落地之後,由 Logstash 收集解析並送往 Elasticsearch,最後 Kibana 作為介面,你可以在那上面下語法搜尋 Elasticsearch 內的日誌。
所以在現今伺服器數量很多的情況下你就是安裝好 Logstash 這種蒐集器往你的 Elasticsearch 送就好。
好,傑出的一手,然後呢?事情怎麼可能那麼簡單。
首先是 Logstash (Java) 的效能實在不怎麼樣,所以後面很多改了 Filebeat (Go),不過也是有一派喜歡用 Fluentd。
再來就是你前面日誌的量一多的時候你總不能無止境的往 Elasticsearch 塞,所以就想到系統架構設計大絕招,流量大就檔 Queue 在中間,呵呵。
將將!Kafka 出場,基本上目前一個很齊全的全方位日誌蒐集系統大概就長這樣。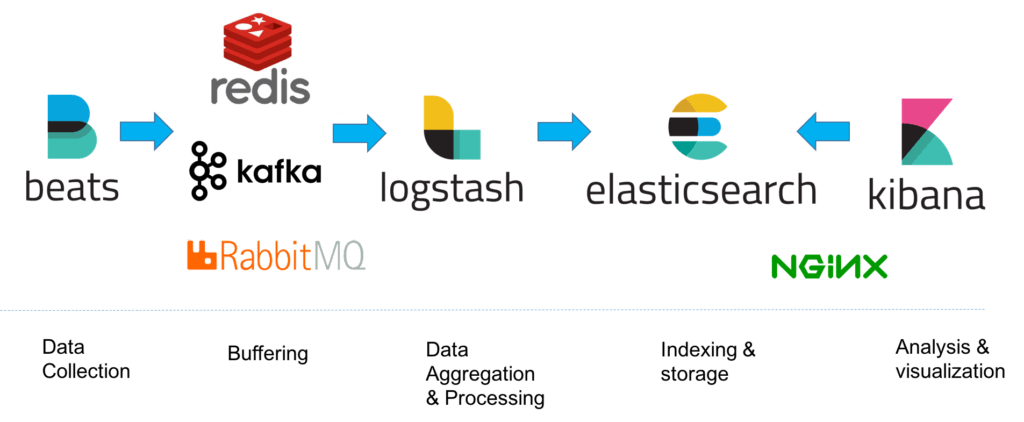
前面是不是有說到寫到 console 的方式,現在就要來講他。
由於在雲端服務中你的各種實例都是他開給你的,所以其實他掌管著所有 VM,自然一個 console log 他也是拿的到的。
在 GCP 的 Stackdriver 裡頭,他可以取得所有 GCP 服務的 console log,所以其實我們只要把 log 單純印出來就好。
搜尋的介面自然也是由他提供,等於是 E、L 和 K 他都做完了呢。
另外如果是 AWS 也有 CloudWatch,Azure 我沒玩過就不敢妄言了。
有機會的話大家也趕快去玩吧!
About Me
Jian-Min Huang
wide range skill set backend engineer
Research, Architecture, Coding, DB, Ops, Infra.
mainly write Java but also ❤️ Scala, Kotlin and Go

