Postgresql 的字元資料型態的一些特殊功能
關於字元資料的查詢處理,一般常見使用 like 子句.
Postgresql 另外提供了 ilike 子句, 是大小寫不敏感的,方便使用.
另外還有正規表示式的方法,這些在此就不贅述.
來看一下 Postgresql 一個 fuzzystrmatch 的 extension
create extension fuzzystrmatch;
commit;
安裝以後會提供
soundex(text) returns text
difference(text, text) returns int
還有 levenshtein, metaphone, dmetaphone 等一系列函數.
select soundex('Joseph'), soundex('Josef')
, difference('Joseph', 'Josef');
+---------+---------+------------+
| soundex | soundex | difference |
+---------+---------+------------+
| J210 | J210 | 4 |
+---------+---------+------------+
SELECT soundex('Anne'), soundex('Ann')
, difference('Anne', 'Ann');
+---------+---------+------------+
| soundex | soundex | difference |
+---------+---------+------------+
| A500 | A500 | 4 |
+---------+---------+------------+
SELECT soundex('Anne'), soundex('Andrew')
, difference('Anne', 'Andrew');
+---------+---------+------------+
| soundex | soundex | difference |
+---------+---------+------------+
| A500 | A536 | 2 |
+---------+---------+------------+
SELECT soundex('Anne'), soundex('Margaret')
, difference('Anne', 'Margaret');
+---------+---------+------------+
| soundex | soundex | difference |
+---------+---------+------------+
| A500 | M626 | 0 |
+---------+---------+------------+
select dmetaphone_alt('Elle Cahon') = dmetaphone_alt('El Cajon city');
+----------+
| ?column? |
+----------+
| t |
+----------+
dmetaphone_alt() 用來模糊匹配一些國外的地名人名時,還蠻好用.
一些國家的文字有重音符號,或是大小寫轉換時,字母變多或變少,要處理時會帶來許多不便,例如這個案例:
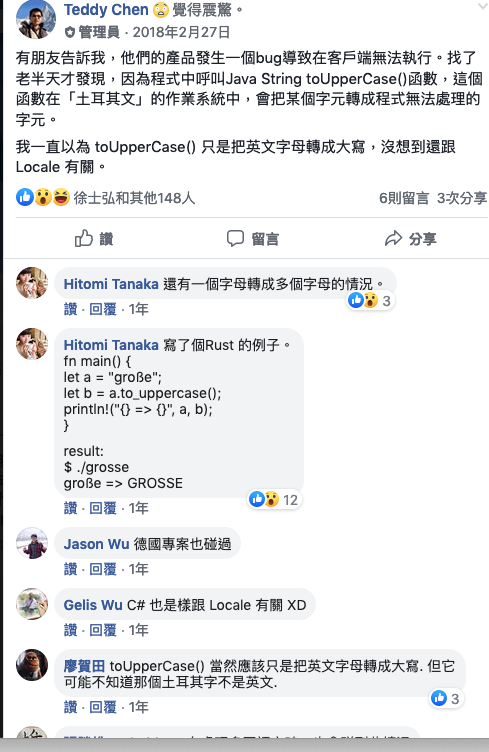
那段Rust程式,是我一時手癢就順手寫了.
幸好 Postgresql 提供了 unaccent 這個 extension.
create extension unaccent;
趕快測試看看
select 'ß' as "Txt", unaccent('ß') as "Unaccent";
+-----+----------+
| Txt | Unaccent |
+-----+----------+
| ß | ss |
+-----+----------+
select upper(unaccent('große'));
+--------+
| upper |
+--------+
| GROSSE |
+--------+
輸入更多測試資料
create table ithelp190924a (
id int generated always as identity primary key
, txt text not null
);
insert into ithelp190924a (txt) values
('ß'), ('spam & ıçüş'), ('Héllø, Wørld!'), ('你好'),
('foo ıç bar');
select txt, unaccent(txt)
from ithelp190924a;
---------------+---------------+
| txt | unaccent |
+---------------+---------------+
| ß | ss |
| spam & ıçüş | spam & icus |
| Héllø, Wørld! | Hello, World! |
| 你好 | 你好 |
| foo ıç bar | foo ic bar |
+---------------+---------------+
(5 rows)
之前在站上有關於資料庫字元型態搜尋的討論
https://ithelp.ithome.com.tw/articles/10198552
https://ithelp.ithome.com.tw/questions/10189710
裡面我有提到 Postgresql citext 這個大小寫不敏感的 extension.
今天介紹了 fuzzystrmatch, unaccent, citext 這個 extension,
都是屬於模糊比對的.搭配使用,可以提供靈活彈性的處理方法.


