
機器學習的好壞評估方式有很多種,如果是評估分類表現,可由混淆矩陣(Confusion Matrix)的參數或其延伸的參數計算而來。
首先我們要有兩個概念,真實的情況、推估的情況兩種
真實的情況就是Label,用最可靠或誤差最小手段獲得的數值或者利用人工判斷,如Fisher[1]的文章(鳶尾花資料集的作者),就有明確表明量測的方式(雖然目前還沒看到如何判斷鳶尾花品種的,可能這是很好判斷吧!!)
而推估情況就是只有給Sample讓模型Predict出來的成果,跟真實情況越接近,模型的表現越好。
使用昨天提供的Code出來的數值做整理的表格示範: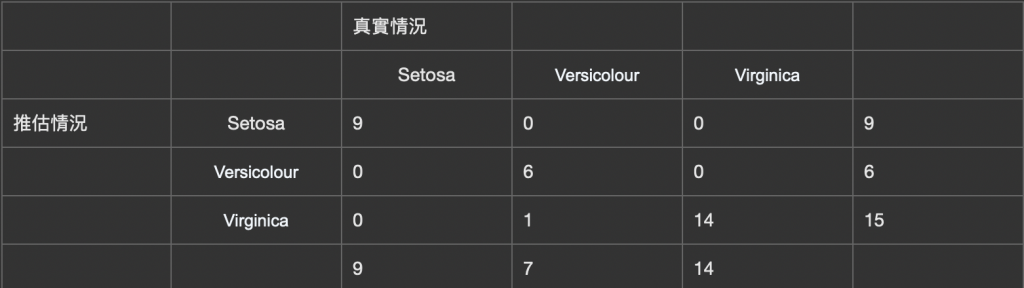
接下來有兩個重要的指標:
(1) Overall acurracy:推估正確/總樣本數 = 29/30 = 0.967
(2) Kappa:(pa-pe) / (1-pe)
其中pa = overall acrracy = 0.967
pe = (9 * 9 + 7 * 6 + 14 * 15) / 30 / 30 = 0.507
所以kappa為:(pa-pe)/(1-pe) :(0.967-0.507) / (1-0.507) = 0.460 / 0.493 = 0.933
根據以下分類
0.0~0.20:slight
0.21~0.40:fair
0.41~0.60:moderate
0.61~0.80:substantial
0.81~1.00:almost perfect
Kappa屬於0.933,算是很OK的!
參考來源:
[1] Fisher, Ronald A. "The use of multiple measurements in taxonomic problems." Annals of eugenics 7.2 (1936): 179-188.
[2] Kappa:https://www.mediecogroup.com/method_topic_article_detail/146/
[3] Kappa:https://zhidao.baidu.com/question/243348345490991204.html?qbl=relate_question_1
