
K-means是一個很古早的演算法,在1950年代左右被很多不同領域的學者提出,比較其他的分類法,如knn不用給定訓練樣本,也就是l有Sample就能預測分類成果,被分成一類的Sample有一個特性就是他們在樣本分布空間非常的近,但是缺點是因為沒有給定樣本本的Label所以需要用其他方式來決定分類的類別。但是常常用於協助人工選取樣本選定或自動化分類。
圖片來自K-Means Clustering in Machine Learning, Simplified
首先,要了解這個K-means分類時候有哪些參數?分類的程序如何?
以及要了解PHP-ML的k-means分類器的參數。
$kmeans = new KMeans(4, KMeans::INIT_RANDOM);
第一個參數數類別數量(ex:4),第二個參數是分類的中心點初始化位置,有兩種方式DASV和隨機兩種,DASV方法可以筆隨機方法找到更好的初始化中心點。
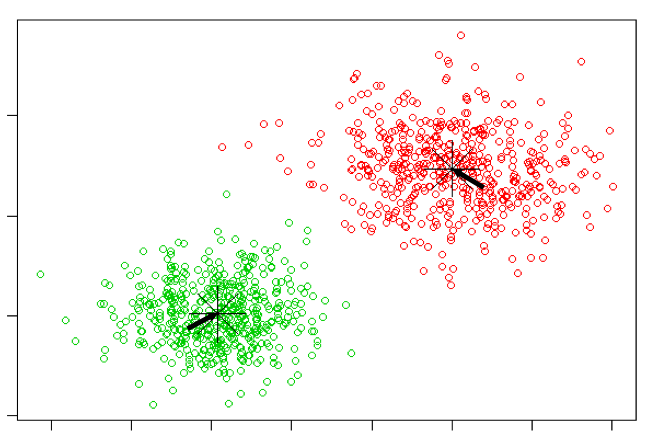
那什麼是初始化中心呢?在K-means中,每一個類別都有一個位置,這個位置是這個類別的中心點,每個屬於這個類別的點,將對其他中心點來說距離最短。
說到距離,跟KNN一樣,有不同距離的計算方式,其中K-means最常使用直線距離來計算。
哪如何算出中心點位置呢?首先確定每一當本相對中心點的距離,每個樣本歸類於最短距離的中心點,之後計算所有樣本的質心作為中心點,然後重複迭帶到次數限制或移動距離小於某一數值。
