什麼是K-means分類法呢?簡單來說即是將資料點自動分成一群一群的分類法,優點為只要設定好參數,不用給定訓練的樣本即可分類,可以省下人工選定樣本的時間與人工選定樣本的主觀性。
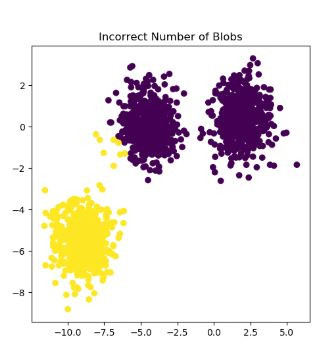
圖片引用自Sklearn
在2維空間散布圖中:
(1) 隨機給定N個分類中心位置(分類數量)
(2) 計算每個點與分類中心位置的距離
(3) 將點歸類為最短距離之類別
(4) 計算每個類別點的質心位置作為新的分類中心位置
(5) 計算新舊中心點距離,若小於某個數值,則終止
(6) 計算迭疊代數,若大於或等於最大疊代次數,則終止
(7) 回到(2)
這樣我們就可以獲得上面的散布圖了。
明天會利用Sklearn實做K-means,開始要再次突破極限啦!!!

