在機器學習中,更在意FP和FN
什麼是混淆矩陣(confusion matrix)?他長的像下面這樣
|\|實際為真|實際為假|
|---|---|---|
|預測為真|TP(True Positive)|TP(False Positive)|
|預測為假|FP(False Negative)|TP(True Negative)|
我老師也曾經說過:
混淆矩陣叫做confusion matrix
看圖就知道很容易讓人混搖,讓人confused
OK, 記住TP、FP、TN、FM,以及各自的意思就好,至於在矩陣中的哪個位置不重要
混淆矩陣是用來評估模型好壞常見的方法。
他還可以用來加以計算Accuracy, Precision, Recell, F值等衡量指標。在不同情況可能會對不同指標感興趣。
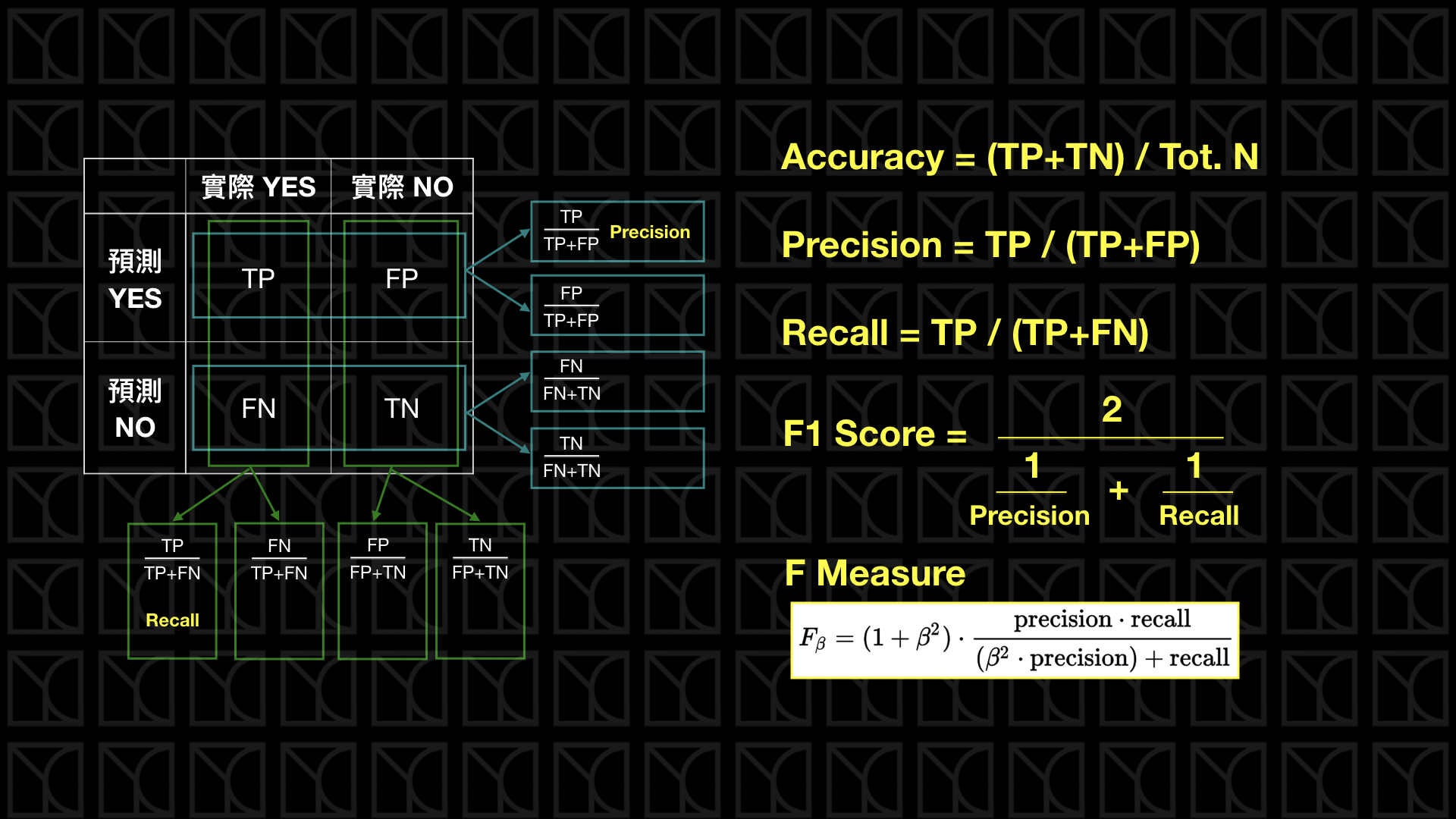
在過去,TP與TN可能比較是被關注的點。因為如果模型有很好的TP, TN值,就表示模型預測的正確行很高(Accurarcy)。不過讓我意外的是,課程中說:
在機器學習中,更在意FP和FN
這個原因是專注於錯誤,有助於調整模型。
FP和FN又被稱為一型錯誤(ɑ錯誤)和二型錯誤(β錯誤)。一型錯誤指的是感興趣的目標未被發現;二型反過來,是被發現的目標壓根不是需要被關注的對象。



 iThome鐵人賽
iThome鐵人賽