
這邊先以一個簡單Demo帶讀者了解Dapper Multi Mapping 概念
public static class MutipleMappingDemo
{
public static IEnumerable<TReturn> Query<T1, T2, TReturn>(this IDbConnection connection, string sql, Func<T1, T2, TReturn> map)
where T1 : Order, new()
where T2 : User, new() //這兩段where單純為了Demo方便
{
//1. 按照泛型類別參數數量建立對應數量的Mapping Func集合
var deserializers = new List<Func<IDataReader, object>>();
{
//2. Mapping Func建立邏輯跟Query Emit IL一樣
deserializers.Add((reader) =>
{
var newObj = new T1();
var value = default(object);
value = reader[0];
newObj.ID = value is DBNull ? 0 : (int)value;
value = reader[1];
newObj.OrderNo = value is DBNull ? null : (string)value;
return newObj;
});
deserializers.Add((reader) =>
{
var newObj = new T2();
var value = default(object);
value = reader[2];
newObj.ID = value is DBNull ? 0 : (int)value;
value = reader[4];
newObj.Name = value is DBNull ? null : (string)value;
return newObj;
});
}
using (var command = connection.CreateCommand())
{
command.CommandText = sql;
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
//3. 呼叫使用者的Custom Mapping Func,其中參數由前面動態生成的Mapping Func而來
yield return map(deserializers[0](reader) as T1, deserializers[1](reader) as T2);
}
}
}
}
}
以上概念就是此方法的主要邏輯,接著講其他細節部分
Dapper為了強型別多類別Mapping使用多組泛型參數方法方式,這方式有個小缺點就是沒辦法動態調整,需要以寫死方式來處理。
舉例,可以看到圖片GenerateMapper方法,依照泛型參數數量,寫死強轉型邏輯,這也是為何Multiple Query有最大組數限制,只能支持最多6組的原因。

泛型類別來強型別保存多類別的資料
override的GetType方法,來客製泛型比較邏輯,避免造成跟Non Multi Query緩存衝突。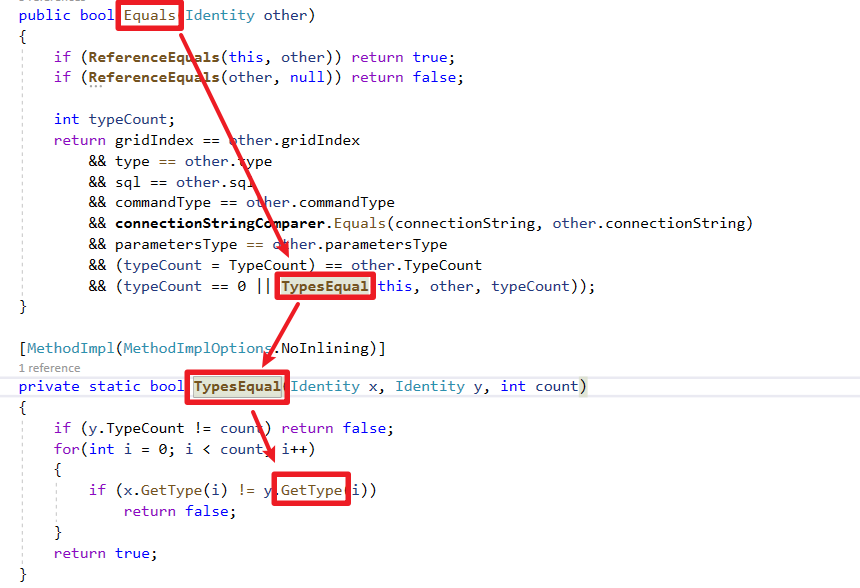
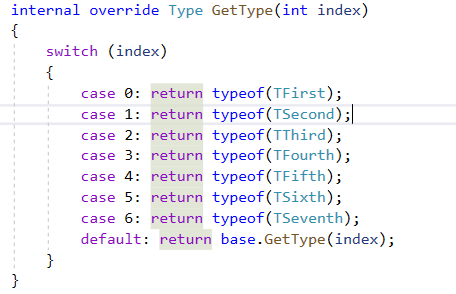
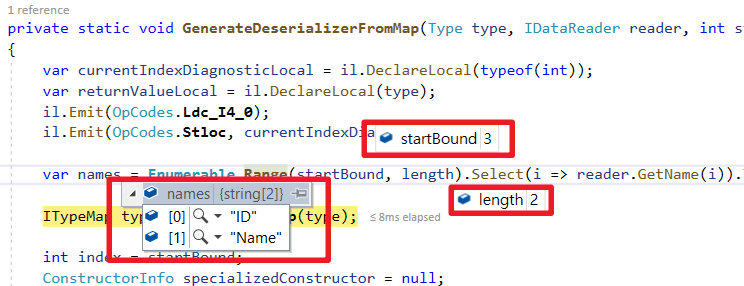
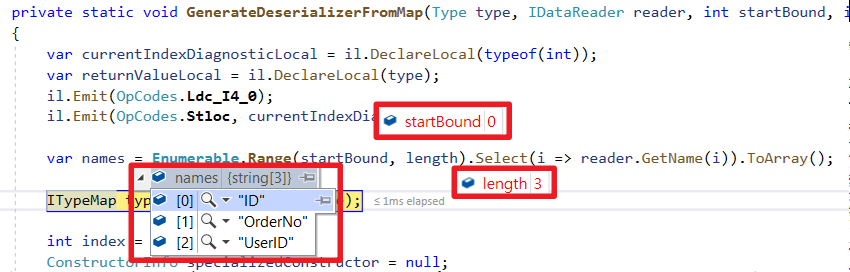
因為SplitOn分組基礎依賴於Select的順序,所以順序一錯就有可能屬性值錯亂情況。
舉例 : 假如上面例子的SQL改成以下,會發生User的ID變成Order的ID;Order的ID會變成User的ID。
select T2.[ID],T1.[OrderNo],T1.[UserID],T1.[ID],T2.[Name] from [order] T1
left join [User] T2 on T1.UserId = T2.ID
原因可以追究到Dapper的切割算法
倒序方式處理欄位分組(GetNextSplit方法可以看到從DataReader Index大到小查詢)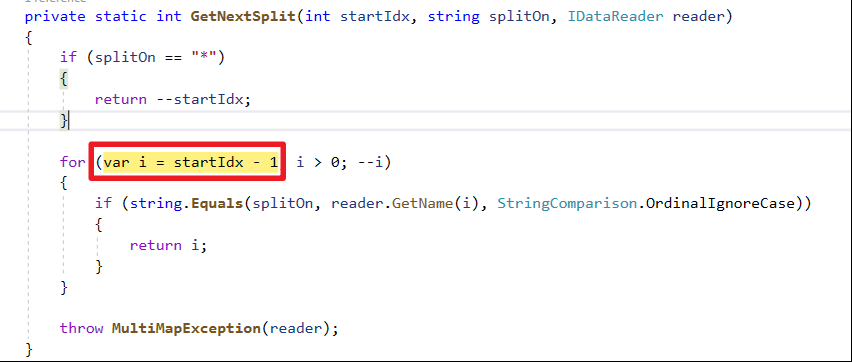
倒序方式處理類別的Mapping Emit IL Func正序,方便後面Call Func對應泛型使用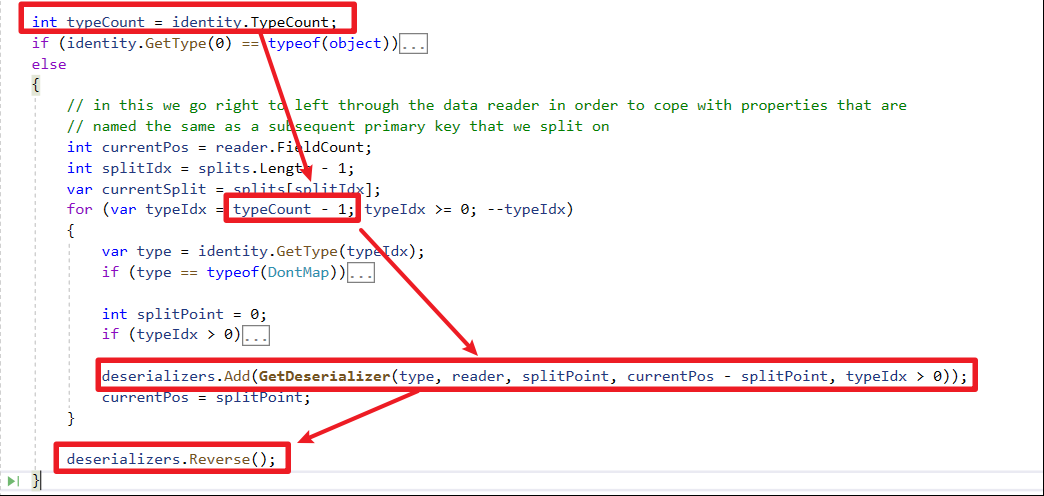

 iThome鐵人賽
iThome鐵人賽