
在進行ML時,會遇到一個問題叫做認知障礙(Human Bias),那什麼是認知障礙呢?其實就是一種為進去的資料不夠全面,導致訓練出來的模型只能依照過往認識的資料來判斷一個未知的內容。舉例來說,假設你想訓練一個ML模型來判斷物理學家的長相,但你的做法是把歷史上有名的物理學家加上The Big Bang Theory的兩位主角作為訓練資料,最後這個模型所訓練出的結果可能會變成把男人的臉當做判斷物理學家的依據。除了這個例子以外,很多時候我們再為資料的時候,會不經意地把自己的喜好,或是自己偏好取得資料的來源獲取資料,並作為訓練資料來訓練出模型,但這樣就會造成上述的狀況發生,因為你的資料本來就不夠全面,訓練出來的模型單然也就只能解決片面的問題,或是產出的答案會與預期的有所落差。
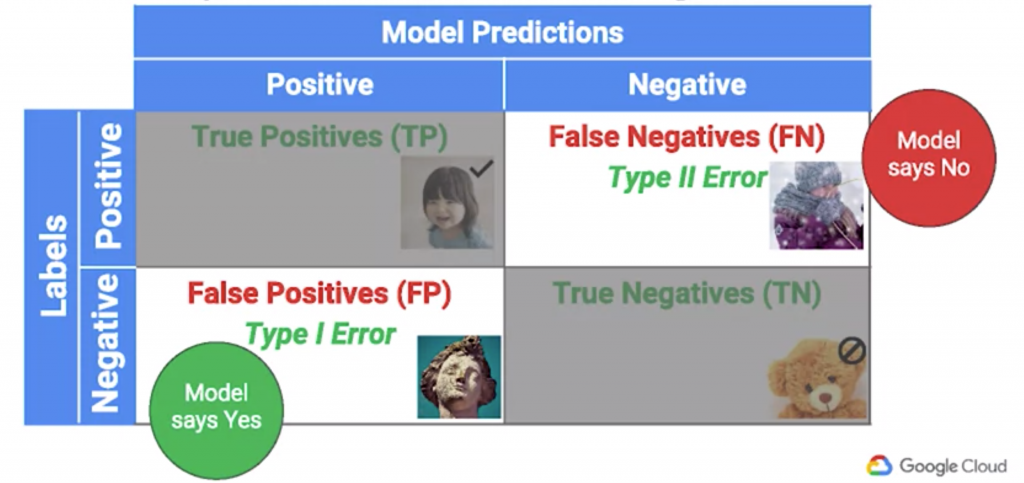
要解決這種問題,必須先把訓練資料分成子群(Subgroups),以人臉辨識來說,子群可能是男人、女人、大人、小孩、有頭髮的人、禿子等,並透過觀察模型對於不同子群的辨識結果,進而改善模型不足的地方。而針對每個子群辨識的結果,可以使用混淆矩陣(Confusion Matrix),將ML所得出的答案與標籤進行比對,並把比對結果分成以下四項,以圖片人臉辨識的模型為例:
True Positive: ML說圖片有人臉,標籤也說圖片有人臉
True Negative: ML說圖片沒有人臉,標籤也說圖片沒有人臉
False Positive (又稱Type I Errors,型一錯誤): ML說圖片有人臉,標籤卻說圖片沒有人臉
False Negative (又稱Type II Errors,型二錯誤): ML說圖片沒有人臉,標籤卻說圖片有人臉
其中False Positive 及False Negative 都是模型預測錯誤的結果,因此造成這兩種錯誤的資料就是我們必須特邊觀察的目標,並進而調整模型,以達到改善模型的目的。

 iThome鐵人賽
iThome鐵人賽