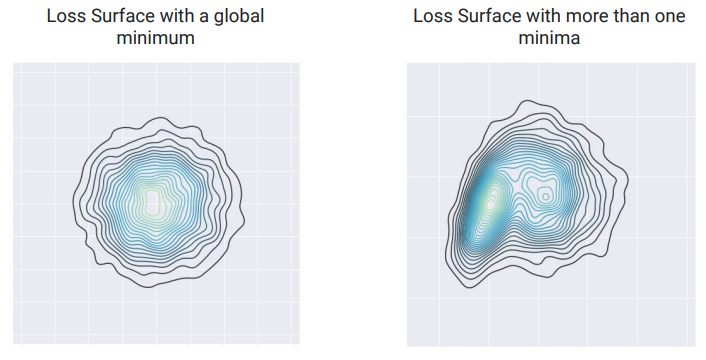
通常大家常遇到的狀況是,期待每次重跑模型待馬都能得到一樣的輸出,但結果常常不是這樣。工程師在編寫代碼時常常預期相同的代碼能傳回相同的結果,但在ML的世界裡似乎完全不是這麼一回事。明明自己都設定一模一樣的數據集、一模一樣的超參數,甚至一模一樣的設備,但卻傳回不同的結果。是我們的梯度下降失效了嗎?還是執行有問題?可能都不是。事實上我們在訓練模型時常常不是左圖的結果而是右圖。兩者區別在哪呢?左邊的圖可以看到只有一個最低點,而右邊的圖則有許多相對低點,也就是有許多局部最優解。我們可以肯定的是,
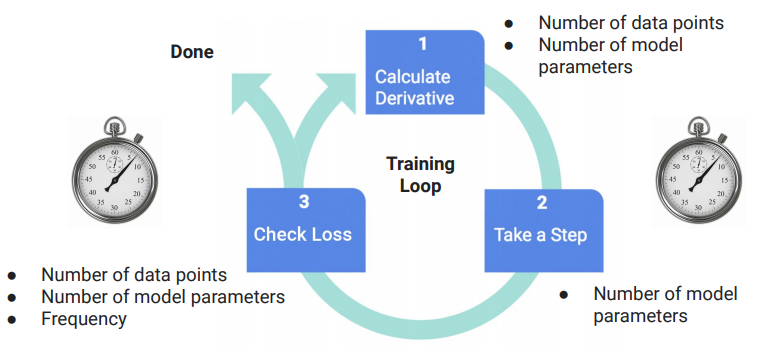
while loss is > Epsilon
derivative = computeDerivative()
for i in range(weights.size):
weights[i] = weights[i] - learning_rate * derivative[i]
if readyToSampleLoss():
loss = sampleLoss()


 iThome鐵人賽
iThome鐵人賽