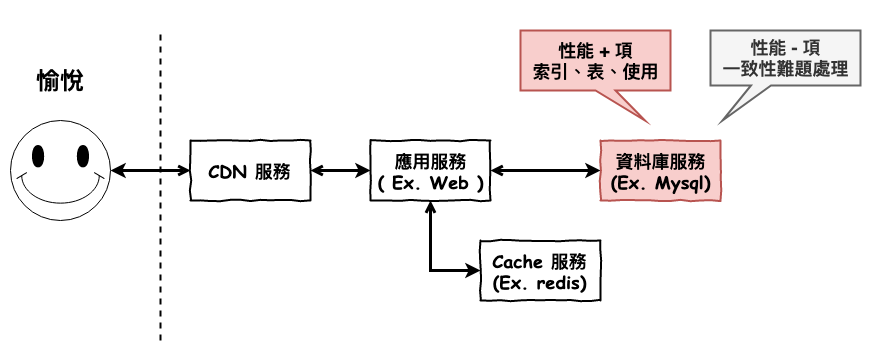
本篇文章中咱們將要從『 表 』的角度來儘可能的優化性能。
這個章節會給一些建立表時的小建議,雖然這裡優化的點不多,但是每一個地方都做到好,才是專業。
基本上在 mysql 中有一下文字類型的選擇,適當的選擇類型,可以省下不少資源 :
char 的特點 :
varchar 特色 :
varchar (255+) 轉成 tinytext
varchar (500+) 轉成 text
varchar (20000+) 轉成 mediumtext
下表為 char 與 varchar 的實際存儲空間比較。
| 值 | char(4) | 花費空間 | varchar(4) | 花費空間 |
|---|---|---|---|---|
| '' | "白白" | 4 bytes | '' | 1 bytes |
| 'ab' | 'ab白白' | 4 bytes | 'ab' | 3 bytes |
| 'abcd' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
| 'abcdefgh' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
表格來源: MySQL 5.6 Reference Manual
注意一下,上面中的白代表為空白的意思,因為 markdown table 在轉換時,有些轉換器會將空白移除,所以上表以白替代。
那什麼時後選 char 什麼時後選 varchar 呢 ?
比較簡單的選擇基準為 :
char 適合常更新的原因在於它比較沒有碎片化的問題,因為它長度是固定的。
這兩個基本上都是用來儲大量文字的東西,但是看了不少篇的文章,它們都建議儘可能的不要使用它,不過我覺得比較準備一點的說法在於,不要在表內,存太長的字串 ( 包含 varchar ),真的要的話建另一張表來儲。
原因在於,它可能會多使用一些空間與 i/o 來處理,在前幾篇文章中,咱們知道一張表會使用 pk 來建立 b+ 樹,然後最下面的節點才能儲放每一行的資料,但是 text 的內容是例外,它不會儲在那一行,而會另外開空間來儲。
在 mysql 中所提供的整數數字類型如下 :
而它所提供的浮點數字型(也就是有小數點)如下 :
數字的選擇基本就是以下兩個準則 :
簡單說以下 unsigned。假設我們在 tinyint (-128 ~ 128) 設 unsigned,就代表此欄位變成可以儲 (0 ~ 256) 多了一倍的空間。像編號這種就很適合。
日期基本上有以下三種選擇 :
基本上第一個還是先看你的需求,如果是有跨時間儲資料庫情況,那 datetime 可以移掉了,因為它是直接儲你 local 的時間。
在假設沒時區的問題下,要選那個呢 ?
目前我是比較建議用 unsigned int,但這真的沒有什麼標準答案。我會選擇的原因如下 :
在選擇時,我還會考慮公司的規範,因為假設公司內一個資料庫儲 datetime、一個儲 timestamp,那你想想應用層的程式會長什麼樣子 ?
~ 備註參考用 ~
基本上有對 mysql 進行深入研究的,大概都有讀過這個書高性能 MySQL,它裡面是建議別用 int 來儲放日期,它說沒什麼好處。但是它沒說理由,所以我就先不理它。
在索引那篇文章中,咱們有提到在 innodb 中,每一張表都會建立 clustered Index b+ 樹,而它是根據以下準則來決定這顆樹的索引值。
它的選擇如下 :
沒有必要的話,請直接使用 auto increment 的 id 編號當 pk,儘可能不要用一些 guid 或啥長長的東東來當 pk。
主要的原因在於,這真的會影響性能。
前面幾篇文章說過,在 innodb 裡,它會使用 pk 來建立一個 b+ 樹的索引結構,如下圖,除了最小面的節點有實際上存行資料外,其它的都是放 pk 索引值 :
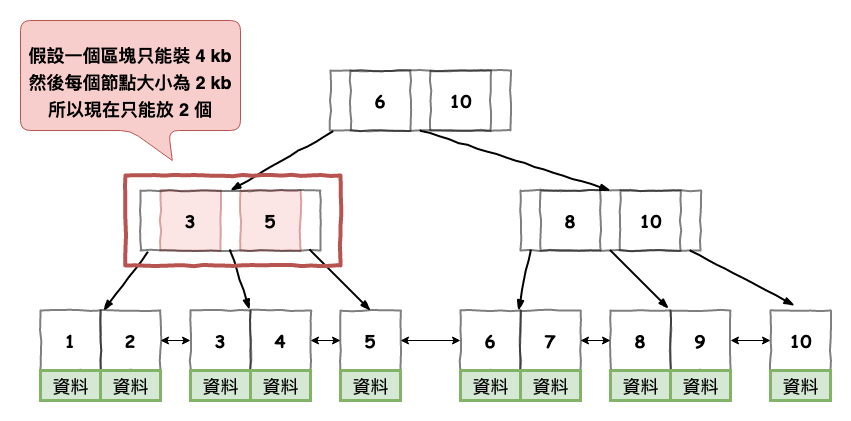
圖 1 : clustered Index b+
問題就出在其它儲 pk 索引值的那些節點,如下圖紅色區塊,一個紅色區塊裡面會包含索引用的節點,假設我們一個區塊限定為 4 kb,下圖咱們每個索引節點大小為 2 kb,所以可以儲兩個,但是如果索引節點大小變為 4 kb 的話,你覺得會如何 ?
它會變成只能儲一個,這也代表區塊變多,也代表 i/o 要更多次。
這也是為什麼不建議用太長值當 pk,因為太長值代表它需要多花點空間來儲,這導致它會增加區塊的數量,最後導致 i/o 次數更多。
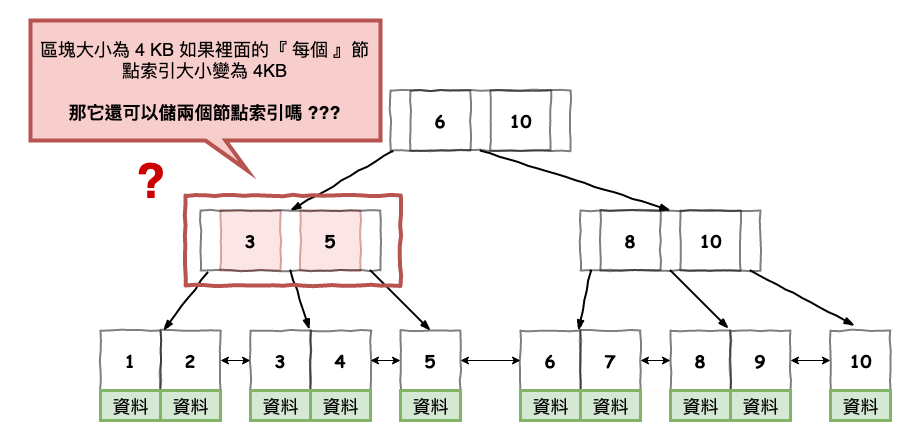
圖 2 : 索引值太大問題
在某些重要的表上,可以新增一個欄位來代表它是否被『 移除 』,但這裡不是只真的移除,只是給它下個 tag,這種好處在於預防萬一。目前應該有不少公司是這樣搞的。
而這個就是會在每個表新增『建立』與『修改』的時間欄位,雖然會耗用一些資源,但是這樣真的有助於於 debug 用。像當你發現某一行改了,然後你有了修改時間,那這時你就可以用這時間去查查應用層一些 log 它到底做了什麼事情,真的好用真心不騙。
有時後多儲點東西減少點性能,增加維護性事實上未來也可以省不少錢錢。
基本上有兩個問題 :
索引欄位 {name}
假設資料為:
{'mark',18}
{ null, 17}
SELECT count(*) FROM user; => 2 筆
SELECT count(name) FROM user; => 1 筆
最後簡單說一下,null 事實上不太會影響到索引查詢,你只要在索引欄位下的是 is null 這種語法,那都會打中索引,不會變全掃。而如果你會變全掃,基本上不是 null 的關係,而是你下的 sql 關係。
當你看到資料表裡面一堆欄位的註解是空的時,你會哭的,尤其是在看不懂欄位名的情況且你主管叫你去應用層看程式碼來推時,你真會哭到想拿起刀。咱真有看過。
正規與反正規是兩種資料儲放的型式,比較簡單且白話文的分法為 :
咱們簡單的來看一下範例。
假設咱們要儲放部門人員資訊。
交易單 table
| trade_id | user_id | volume |
|---|---|---|
| 1 | 001 | 10 |
| 2 | 002 | 20 |
| 3 | 003 | 30 |
交易人 table
| id | name | age |
|---|---|---|
| 001 | mark | 20 |
| 002 | jiro | 35 |
| 003 | ian | 55 |
而反正化則只會建立一張票,如下,交易人的資料會放在同一張裡面。
| id | volume | user_id | user_name | user_age |
|---|---|---|---|---|
| 1 | 10 | 001 | mark | 20 |
| 2 | 20 | 002 | jiro | 35 |
| 3 | 30 | 003 | ian | 55 |
正規化的特點如下 :
反正規化:
先說一下兩種模式的主軸 :
基本上可以的話請選正規化,原因在於穩定,除非你很有自信,系統現在至未來都會很少更新需求,並且你也知道更新時可能會有那些雷,不然的話,還是請選正規化。
基本上就是所謂的『 第 n 正規化型式 』,基本上咱覺得到第三層就夠了。
然後這裡詳細的正規化型式可以去看筆者以前寫的文章應該就夠了,雖然是 3 年前寫的,但是回過頭看還是覺得寫的算清楚。
本篇文章我稍微簡單的整理一些,咱們平常開發時,要建立一個表時的需要注意事項,並且也順到的探談了一下正規化與反正化規化的問題。
不過這些準則上,不全然是為了性能的準則,有一些是會為了維護性而增加的一些東西,這 30 天的文章主題是『 從 0 至 1 儘可能的建立好的系統 ( 性能 ) 』,然後主題是性能,但別忘了我們的目的是好的系統。
一個好的性統的要點是『 平衡 』喔

