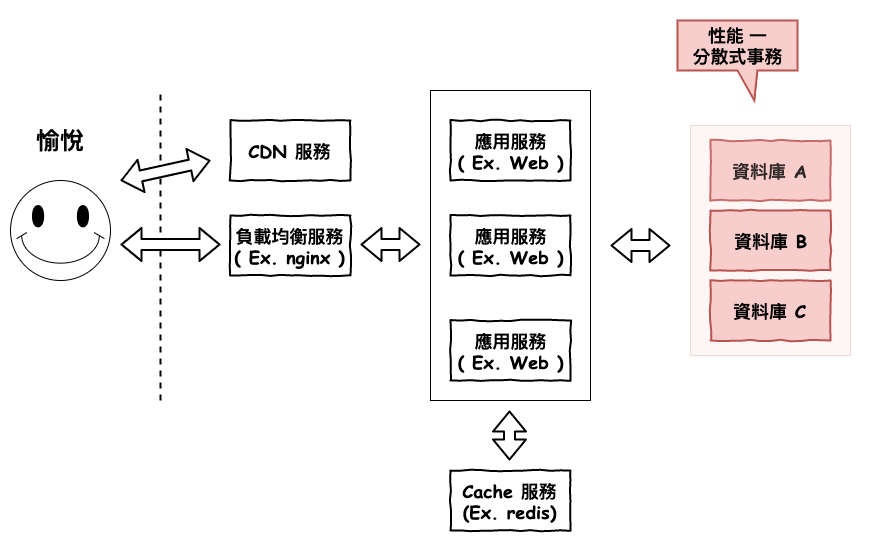
本篇文章中,咱們要來說說分散式系統中,最麻煩的部份『 分散式事務 』這一塊,接下來咱們來認真的理一下這個鬼。
本篇分為以下幾個章節 :
首先咱們都知道資料庫有所謂的『 事務 』機制,比較準備的說是事務這個『 單位 』,它當初建立出來是為了解決所謂的 :
確保『 同一組資料庫業務操作 』可以有正確的結果
它們不會因為某項業務的其中一項操作錯誤了,導致整個資料庫的資料不正確 ( A )。
它們不會因為系統固障而導致原本成功修改的資料消失 ( D )。
它們不會因為並行操作,導致資料產生產生無法預期的結果 ( I )。
總而言之,事務在固障與並行的情況下,不會產生所謂的『 資料不一致性 』 ( C )
如果事務可以確保上述事情,那就可以說 :
這個事務有 ACID 的特性
然後咱們在以下三篇文章中,咱們有談到,在 mysql 單機事務的情況下,它們用了以下的機制來確保這些機制 :
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
30-17 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 2 )
但是注意 ! 上述都是單機 acid 的解法。
那如果換到『 分散式 』的情況怎麼辦呢 ?
這就是咱們接下來要說的東西『 mysql xa 協議 』。
不過先說一下,mysql xa 協議嚴格來說,它只能解決所謂的 :
原子性 A、隔離性 I
持久性這個我還不確定,而一致性這鬼,這東西在分散式的概念又與單機的概念不太相同了,詳細的原因請看看 cap 理論與 base 理論,這裡我不能給準確的答案。
但在開始 xa 協議之前,咱們要先來看看一個東西 2 pc。
記好 2 pc 它是儘可能讓咱們在分散式的環境下,可以實現『 事務原子性 』,而不是所有的 acid 特性。
2 PC 是為了實現分散式事務的原子性特性
然後比較白話文的說法為 :
2 PC 是為了讓『 分散式事務 』可以達成,要麻全完成,要麻全部未完成
它的基本原理如下 :
接下來咱們第一階段的流程如下圖 1 所示。
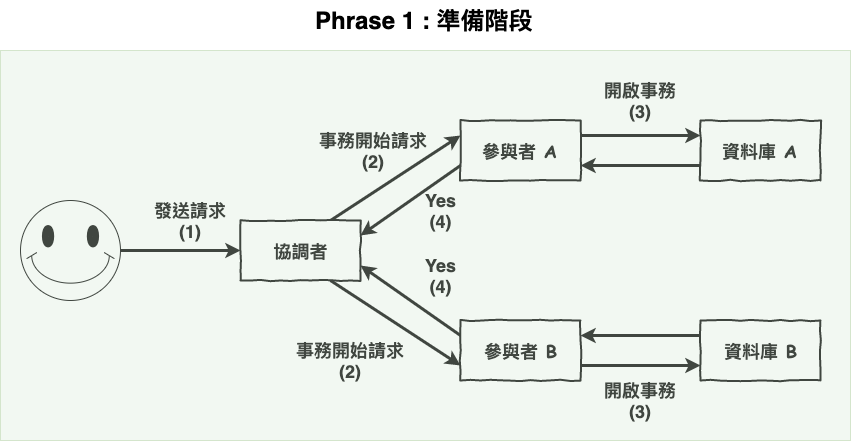
圖 1 : 成功的第一階段
上面的第一階段,協調者已經從各參與者收到 :
我們都可以『 準備 commit 』了喔
接下來操作流程如下圖 2 所示。
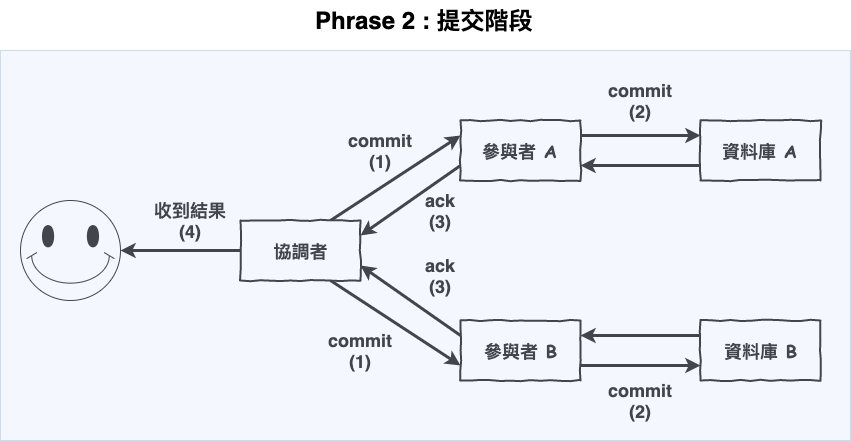
圖 2 : 成功的第二階段
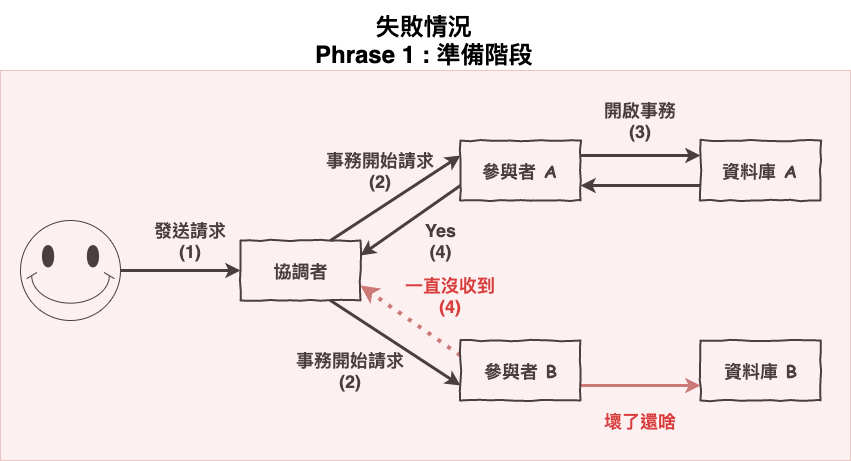
圖 3 : 失敗的第一階段
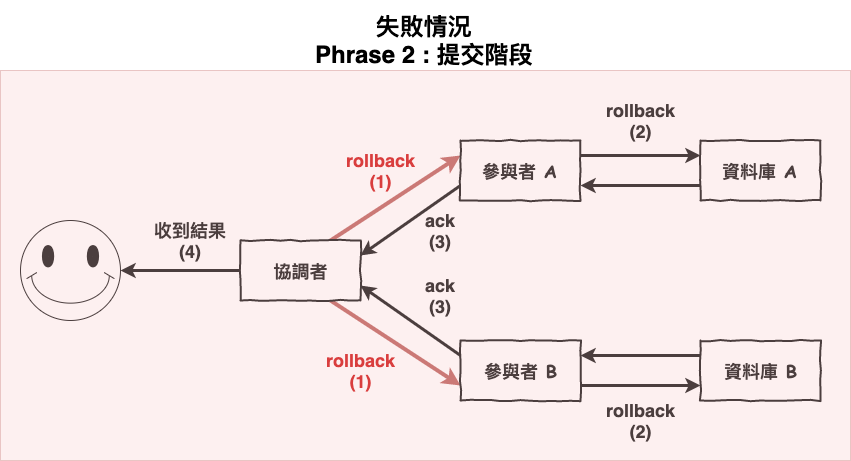
圖 4 : 失敗的第二階段
上述章節就是最基本的 2 pc 流程,而咱們也知道這個流程可以確保咱們的 :
分散式事務 ACID 特性的原子性 A
接下來咱們要來說說 mysql 有支援的 :
XA 協議
而如果是用 mysql 的 xa 協議可以確保 :
分散式事務 ACID 特性的隔離性 I
在這章章開始前先問一下。
xa 協議與 2 pc 是有什麼關係呢 ?
上面的 2 pc 是一種概念與方法,然後 xa 協議是定義出來 2 pc 中『 協調者 』與『 參與者 』各自實際上要做的事情,就像是通訊協議一樣, http 協議定義好,接受方與放送方都要可以解析 http 封包。
首先 mysql 它有支援所謂的『 xa 協議 』,但是它有分為兩種 :
其中咱們的重點是『 外 xa 協議 』,mysql 在這裡的支援為『 xa 協議的參與者 』,所以當有個協調者以 xa 協議發送請求到 mysql 上,它就會進行 2 pc 的處理,就如果 5 所示。
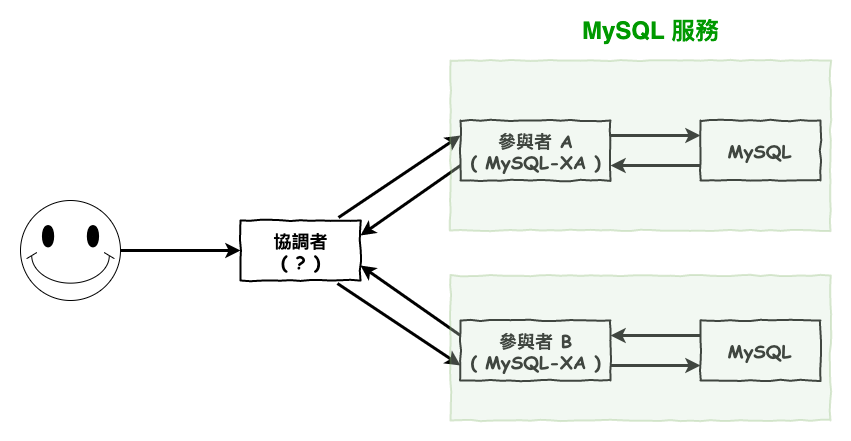
圖 5 : mysql 2 pc xa 協議圖
這裡為什麼協調者那要打個問號呢 ? mysql 沒支援嗎 ?
嗯對沒有。
協調者要自已寫程式碼,又或是使用一些資料庫中間件,這些中間件有些會有支援 xa 協調者的功能,下一篇文章會簡單的說明一下。
~ 小知識補充 ~
淺淡一下,為什麼要有『 內 xa 協議 』呢 ?
binlog 在 mysql 中是用來記錄 sql 操作log ,而 redo log 是 innodb 用來記錄修改過的頁 log,反正兩個都是記錄修改資料的 log。這兩個東東詳細的介紹可以看以下兩篇文章。
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
上面有提到,它倆『 嚴格來說 』都是『 記錄修改資料的 log 』,只是以不同的觀點來記錄,一個是 sql 修改,一個是那個硬碟頁修改。
那這時要如何的保證一致性呢 ? 也就是不會發生一個有 log 而另一個沒 log 的問題。它的解法就是
『 內 xa 協議 』也就是說它也是透過 2 pc 來達成這件事情。
下面為咱們實際使用 mysql xa 的概念碼,其中下述程式為上圖 5 中的協調者的程式碼。其中注意一下,雖然是用 js 寫的,都這裡全部假設都是同步的就好,反正只是概念碼。
基本上下述程式碼分為幾個階段 :
// 協調者所執行的概念碼
const connA = mysql.createConnection({
database : 'DB_A'
});
const connB = mysql.createConnection({
database : 'DB_B'
});
try {
// (1) 兩個資料庫指定同一個『 分散式事務編號 xid1 』
connA.query('XA START xid1');
connB.query('XA START xid1');
// (2) 兩個資料庫的操作
connA.query('Update user SET name = Mark WHERE id = 1');
connB.query('Update user SET name = Ian WHERE id = 2');
// (3) DB_A 的 2PC Phrase 1 準備階段確認
connA.query('XA END xid1');
connA.query('XA PREPARE xid1');
// (4) DB_B 的 2PC Phrase 1 準備階段確認
connB.query('XA END xid1');
connB.query('XA PREPARE xid1');
// (5) 2PC Phrase 2 提交階段
connA.query('XA COMMIT xid1');
connB.query('XA COMMIT xid1');
} catch {
// (6) 2PC 錯誤時兩個資料庫都 rollback
connA.query('XA ROLLBACK xid1');
connB.query('XA ROLLBACK xid1');
}
奇怪這裡還沒提到 xa 協議如何實現 ACID 的隔離性啊 ? 別急等等有
mysql 根據 2 pc 所實現 xa 協議有個很嚴重的問題那就是 :
性能很毛
使用 mysql xa 性能會非常的差,主要有以下兩個原因 :
如果下圖 6 所示,如果每個協調者是同步操作的情況下,那有幾個參與者就要等幾次,而如果是非同步的協調者,那還是要等一個最久的參與者回應,才能往下走,你想想,如果其中一個網路有問題或啥的,等了 5 秒,那就代表這整個分散式事務要 5 秒才能處理完。
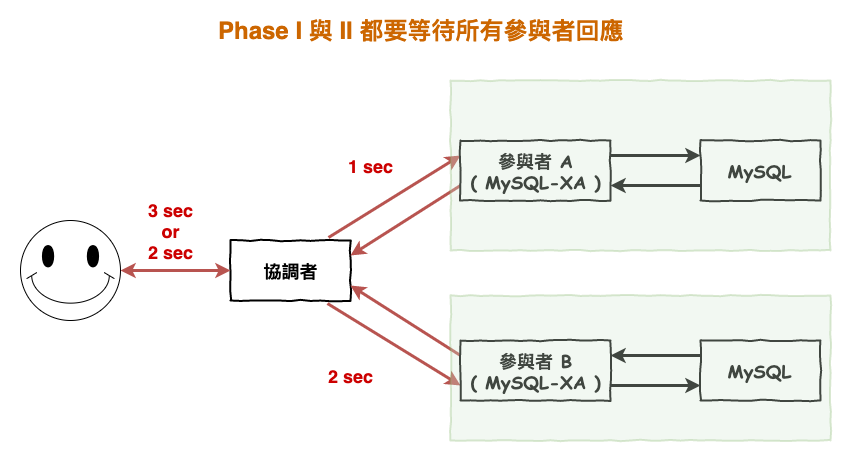
圖 6 : xa 協議性能差原因 1
mysql 官網要求如果要使用分散式事務 xa 那就要將隔離級別改為 serializable
However, for a distributed transaction, you must use the SERIALIZABLE isolation level to achieve ACID properties. It is enough to use REPEATABLE READ for a nondistributed transaction, but not for a distributed transaction
而這裡就是實現隔離性的原因 :
mysql xa 協議要求的 serializable 隔離級別,可以確保分散式事務的 ACID 特性中的隔離性
為什麼要改成 serializable 隔離級別呢 ?
先簡單複習一下,咱們 mysql 資料庫預設的 RR 隔離級別的特性如下 :
然後問題就出在下述圖 7 的這種情況。這個情況是這樣的。
預設欄位值 :
X 資料庫 count = 0
Y 資料庫 price = 10
分散式事務 A 裡面包含兩個不同資料庫 X,Y 的更新操作
X 資料庫操作 => 將欄位 count 更新為 100
Y 資料庫操作 => 將欄位 price 更為為 20
然後咱們還有另一個分散式事務 B 進行以下的操作
分取式事務 B 裡面包含兩個不同資料庫 X,Y 的讀取操作
X 資料庫操作 => 讀取 count 欄位
Y 資料庫操作 => 讀取 price 欄位
最後將結果相乘得出值 = count * price
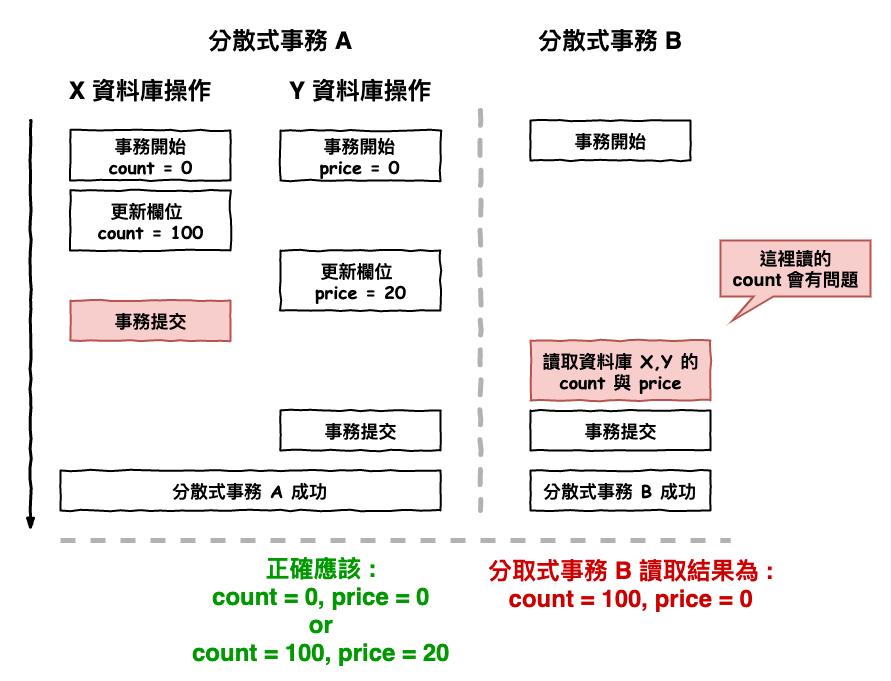
圖 7 : xa 協議如果是 rr 級別的問題
這裡先說一下,為啥圖 7 的正確讀取的結果,會有兩種,這種道理可以想成串行執行,如果兩個事務執行是一個前,一個後,那結果就會有兩種,因為看誰先執行,而這兩種結果是可以接受的,因為它符合 acid 的『 隔離性 』,一個事務的操作,不會影響到另一個事務。
好那先拉回來,問題出在那呢 ?
問題就出在圖 7 紅色框框那的讀取,它會讀到 x 資料庫單機事務已提交的值 count = 100。
這有啥毛病呢 ? 事務不是提交了嗎 ? 嗯『 單機事務 』已經提交了沒錯,但是別忘了『 分散式事務 』還沒提交。
咱們在說一致性問題時,有提到一個難題那就是『 髒讀 』。
髒讀代表某個事務會讀取到其它事務『 未提交 』的值
而這也代表它沒有符合 :
acid 的隔離性,因為 a 分散式事務的操作影響到 b 分散式事務的讀取
以分散式事務角度來看,它已經發生髒讀的情況,因為分散式事務 b 讀取到分散式事務 a 的『 未提交 』值。
就是因為這種情況,所以 mysql 要使用 xa 協議就一定要將它隔離級別 serializable。當級別改成它後,操作特性就變成如下 :
所以如果是 serializable 的隔離級別,結果變的圖下圖 8 所示,這樣就會讀取到正確的結果。這就是為什麼使用 xa 一定要 serializable 級別的原因。
xa 一定要使用 serializable 級別的原因在於,rr 級別在分取式事務情況,會發生髒讀的問題
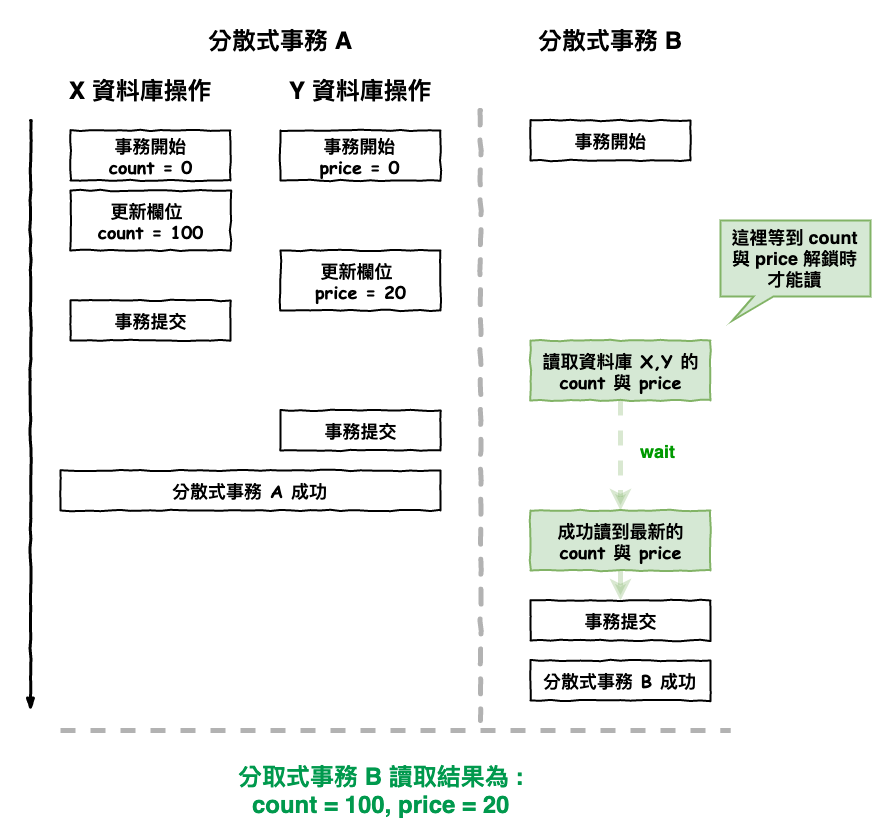
圖 8 : xa 協議如果是 serializable 級別的結果
而由於這個 serializable 級別要求,使得分散式事務變成串行處理,也相對確保了 ACID 的隔離性
~ 小備註 ~
如果不熟悉資料庫隔離級別的友人,可以參考以下兩篇文章。
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
30-17 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 2 )
本篇文章中咱們提到了某些方面我覺得算是分散式系統中的大難題 :
如果讓分散式事務執行 acid 的特性
而這裡咱們將了一個最基本的方式 :
2 PC + MySQL XA 協議
不過記好這個方案性能很毛。還有個重點,嚴格來說這個 2 pc 是只完成了 acid 中的 a 與 i 這個兩個特性,而致於其它兩個特性在分散式環境要如何解呢 ? 不好意思可能要下一次鐵人賽才知道了……
最後這裡淺淡一下實務上的使用,首先,我在實務上到現在沒有看到太多真的有在使用 mysql xa 協議來處理分散式事務的這東西,最主要的原因在於性能這個問題。只要用了 mysql xa 所有資料庫都要調整成 serializable 級別,那資料庫的性能幾乎可以說是差了 10 倍左右,這影響非常的巨大。
那現在大部份公司如何的處理分散式事務這一塊呢 ? 我知道有幾個名詞例如消息隊列處理或 tcc 等這些方法,但在實務上台灣有沒有公司用我就不知道呢。
說實話,就算是在咱公司也都沒有處理這塊 ( 我所知道的部份 ),雖然咱們有分庫,但是那是為了『 業務或維護 』而分,不是為了性能,咱們在使用時大部份 95 % 的時間還是單庫操作,真有多庫操作也都是讀的情況。
不過這裡也只是我自已看到的東西,假設有看到有台灣公司有處理這塊的,真想跪請他們分享一下是如何處理這塊鬼問題的。
順到說一下這也讓我有點好奇,微服務這一塊,它這裡是如何處理的呢 ? 這或需是未來另一個可以深入探討的方向呢。
Phrase 1 : 準備階段,其中一個參與者失敗了,第二階段進行 rollback
在 Phrase 2 : 回滾階段,如果還是失敗了,沒收到 ack
那該怎麼辦呢?
如果在第二階段有兩台資料庫 A 與 B 要收到 rollback 發生以下情況時,會這樣。
A 收到 rollback => 正常執行 rollback (沒啥毛病)。
B 沒收到 rollback => 分散式事務失敗,用戶就收到失敗訊息,而 B 資料庫的單機事務,會因為資料庫連線有異常 terminated (因為收不到 rollback 指令有可能是因為網路或資料庫掛了),而自動進行 rollback。(不過聽說不同應用與資料庫好像有不同處理,參考看看這篇stackoverflow,我也不確定是與否)
順到說一下,這裡還有很多 2pc 的異常問題可以說,而這也牽扯出為什麼會有 3pc 或之後的一些分散式事務解,然後又可以牽扯出為啥 mysql xa 之支援 2pc 的問題。隨便想一下大概可以寫個 5 篇…… 希望下次有空時可以寫寫。

