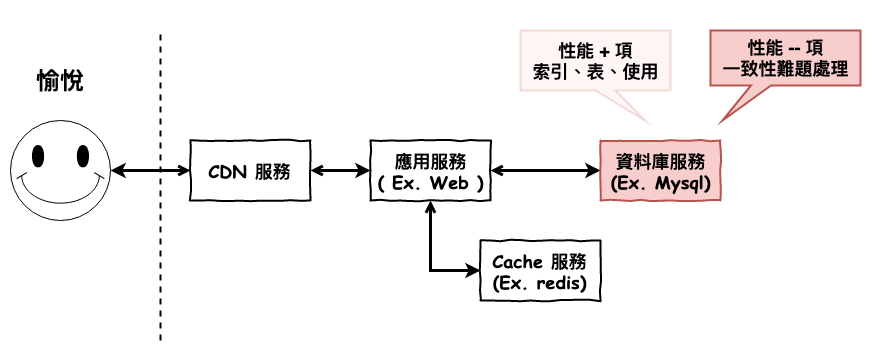
前面幾篇文章中,咱們理解完了 mysql 的索引概念與原理,並且理解了在 mysql 中一個查詢的速度與否取決於索引與表的設計。接下來咱們要來理解一些會拖性能後腿的東西。
這個會性能後腿的東西就是 :
一致性難題
在追求高性能的路上,通常一定會面臨到資料一致性問題,而產生的原因通常可簡單的分為以下來個來源 :
接下來本篇文章,咱們來看看 mysql 它是如何處理『 故障 』所引發的一致性問題。
假設咱們要將 a 帳戶的 1000 元轉到 b 帳戶去,但這時如果在處理 b 帳戶加錢時出錯了,那整個結果就錯誤了,如下圖 1 所示。
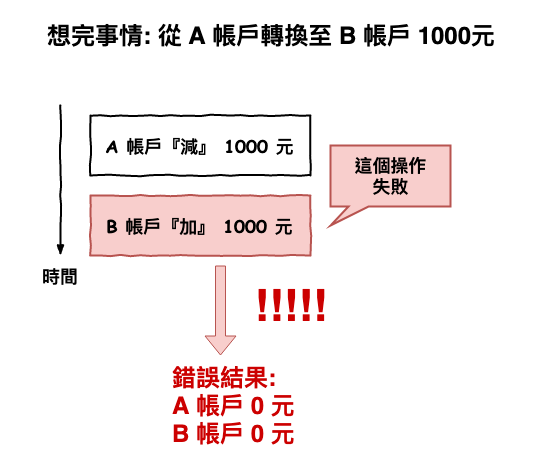
圖 1 : 故障導致資料不一致性
在圖 1 中正確的 b 帳戶應該是 1000 元,但是因為加錢失敗了,所以 b 帳戶變成 0 元,這就是產生了『 資料不一致性 』。
第二個產生的原因要先來理解一下,所謂的『 通常 』寫入硬碟的原理。
假設咱們有一個 insert 的指令,要將資料寫入到資料庫中,然後資料庫要將它寫到硬碟中,那它的運行過程如下。
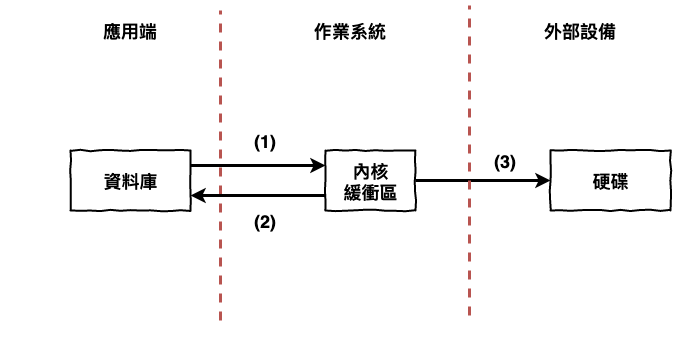
圖 2 : 作業系統寫入硬碟原理。
明眼人應該有看出問題在那,那就是假如在寫到硬碟前,機器掛掉了,那由記憶體開的內核緩衝區中的資料不是就消失了 ? 如下圖 3 所示,那剛剛那筆寫入的指令,不就事實上是失敗的了 ?
假設這情境在銀行,當用戶存了一百萬進去,然後銀行說成功,但是當去看看帳戶領錢時,卻發現沒有那筆錢時,用你的小腦袋想想,用戶有沒有可能拿刀出來呢 ? 當然不會大家都是文明人,頂多拿個球棒。
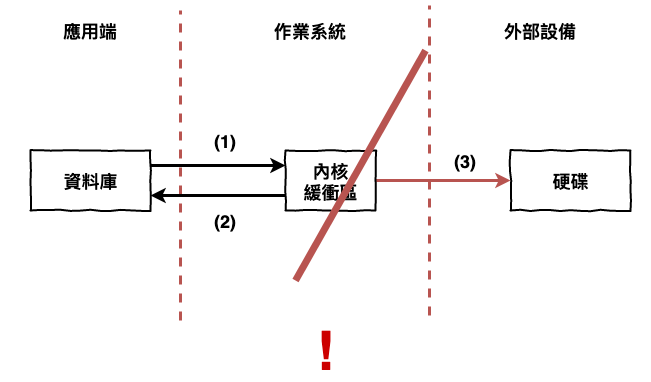
圖 3 : 機器故障導致內核緩衝區資料遺失
~ 小知識 ~
基本上應該是有人會問,為什麼不是寫到硬碟在回 ok 呢 ? 嗯作業系統的確有提供 fsync 這方法,它可以直接寫入到硬碟,但是如果每一次操作都是需要修改硬碟,那會耗費非常多的時間,所以通常很多情況下是只有寫入到內核緩衝區中,等待一段時間後在一起寫入到硬碟。
首先它定義了一個叫『 事務 transaction 』的操作單位。
假設某件事情需要以下兩個指令才能完成 :
那資料庫會將這兩個操作包裝成一個『 事務 』。
而這個事務只有兩種結果。
delete(10) // 帳戶減少 10 元
add(10) // 帳戶增加 10 元
包裝成事務
begin transaction
delete(10) // 帳戶減少 10 元
add(10) // 帳戶增加 10 元
transaction commit
它主要的實現是使用 undo log。
就是當你 insert 一條資料時,就會在 undo log 中,新增一條 delete 指令,而當你 update 一條資訊時,就會在 undo log 中,新增一條 update 回原資料指令。
當事務失敗時後,就可以利用 undo log,來將資料回復到原本的模樣,如下圖 4 所示,當在紅色區塊要將 b 帳戶加錢時,但是機器故障或是啥的失敗,導致這個事務沒有進行 commit,那這時就會使用 undo log 來將未 commit 的 undo log 給回復。
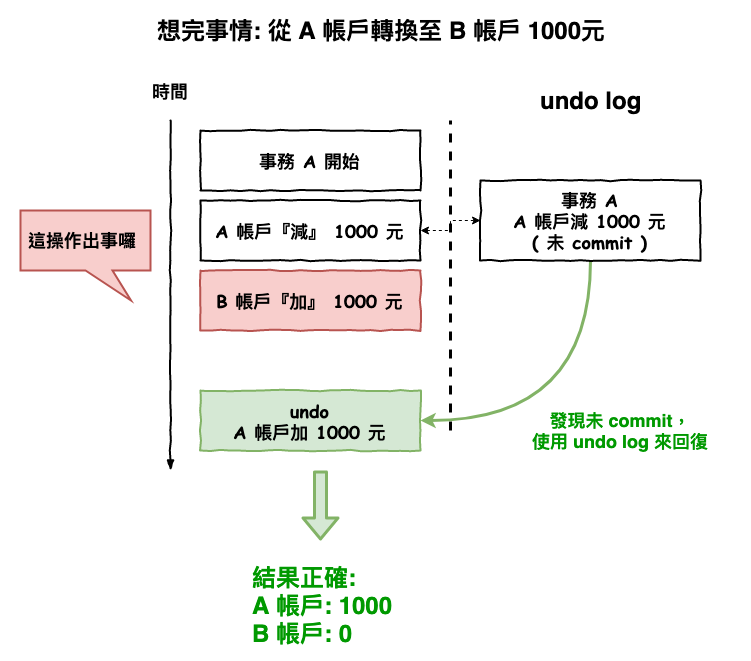
圖 4 : 事務失敗回滾
而正常運行圖如下,當一個事務有正確的進行 commit 已後,就會將該 undo log 下一個已經 commit 的 tag,然後就算系統重啟,它發現這個 undo log 已經 commited 了,它也就不會回滾它了。
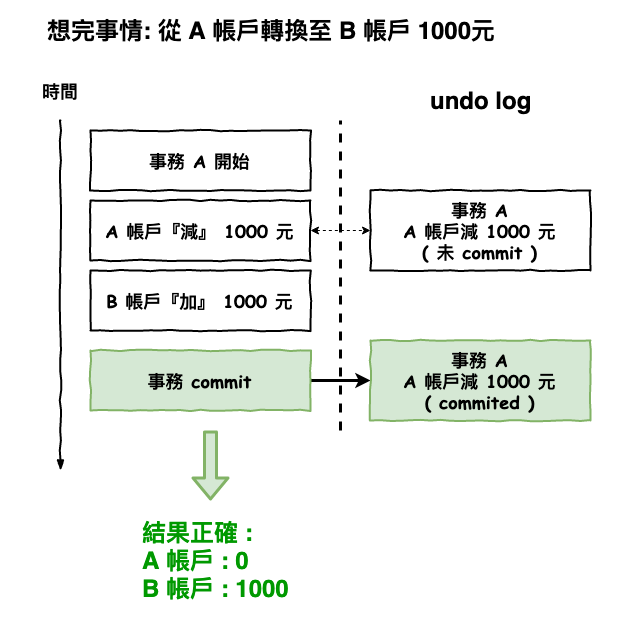
圖 5 : 事務正常處理
~ 小備註 ~
這裡只是淺淡一下 undo log,它事實上還有很多東西可以說,包含 undo log 的管理等,有興趣的友人可以查查。
這裡簡單的拿個程式碼小範例來給一些初學者看看,應該會比較有感覺。
下面為 php 範例,從 laravel 官網直接拿來的小範例,簡單一個 transaction 就是一個操作單位,這個單位裡面的指令,要嘛全部完成,要嘛全部不做,不二價。
DB::beginTransaction();
DB::table('users')->update(['votes' => 1]);
DB::table('posts')->delete();
DB::commit();
redo log 機制
基本上有人一定會問說,為什麼它是寫到內核緩存後,就直接回傳 ok 的回應呢 ? 不能直接改成寫完硬碟後在回 ok 嗎 ?
對 ! 答案是可以,但是有問題。
那就是會太慢
假設我們每一個指令,都要進行所謂的 fsync ( 就是直接寫到硬碟的方法 ),那會效能會非常的差。
因此 mysql innodb 使用 redo log 來建立一套,可以保證寫入,且性能又不會影響到太多的機制。
假設咱們有一段的事務流程如下。
A = 1000, B = 0
1. 開始事務 T
2. Update A account = 0 (A 帳戶修改為 0 元)
3. Update B account = 1000 (B 帳戶修改為 1000 元)
4. 事務 commit
接下來看看在運行這一段事務時,它會如何的儲放 redo log 與使用它。如下面流程,基本上每一個操作都是會寫入到 redo log 緩存中,而不是實際上將修改的資料,寫入到硬碟中。
Redo log 角度 ( 編號對應於上方操作 )
1. 記錄事務 T 開始到 redo log 緩存。
2. 記錄要修改 A 的 page 到 redo log 緩存。
3. 記錄要修改 B 的 page 到 redo log 緩存。
4. 將 redo log 緩存使用 fsync 寫入到硬碟。
~ 小知識 1 ~
redo log 是儲你修改了那一個 page,而 undo log 是你對那一個資料表的欄位進行了什麼修改。通常會稱 redo log 為物理日誌,而 undo log 為邏輯日誌。
~ 小知識 2 ~
page 是 innodb 的硬碟操作的最小單位,它的預設大小為 16 kb。而這個 page 會在 mysql 的緩衝區暫存住。
上面是針對事務所產生的 redo log 流程,然後咱們來看一下完整的將資料寫到硬碟的流程如下:
下圖為完整的將資料寫到硬碟的流程。
所以從上述的流程知道,用戶收到 ok 只是 redo log 已經寫到硬碟,而不是實際將修改的資料寫到硬碟。
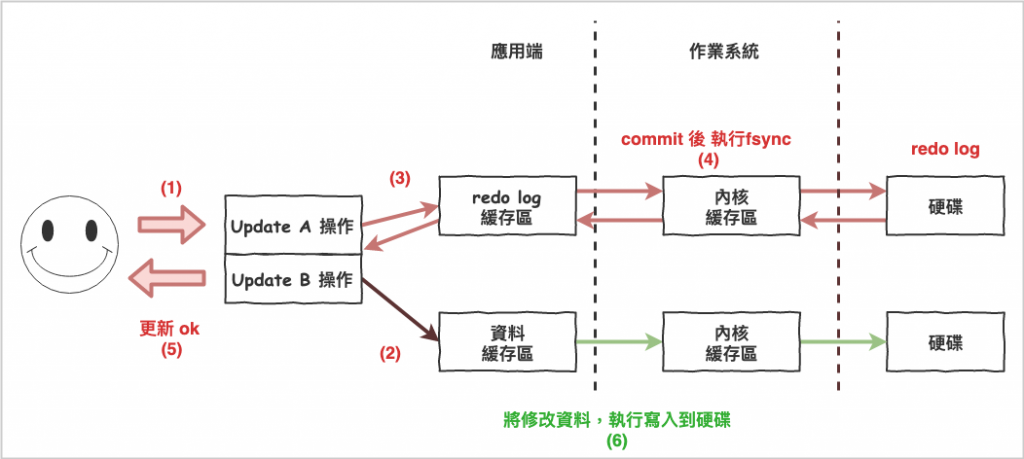
圖 6 : 將資料完整寫到硬碟的流程
~ 小知識 ~
注意,在 innodb 中,一切都是以 log 為主,也就是說你實際上 insert 資料,不是直接去修改硬碟的 b+ 樹,而是先將這個操作寫入到 log 中,在由一個叫 master thread 來將緩衝區資料丟到硬碟中。
可是這時有人會問,那如果有人在 master thread 修改前,來讀取資料,那不是也會讀到舊的 ?
不,不會,因此所有的操作都會到 mysql innodb 的緩衝區先進行處理,也就是 insert 會寫到緩衝區,而讀取時也會先直接到緩存區拿。
為什麼不能改成下圖 7 的流程呢,直接在 commit 時在 fsync 就好,為什麼一定要寫到 redo 後,在處理呢 ? 我當初也有這個鬼疑問。
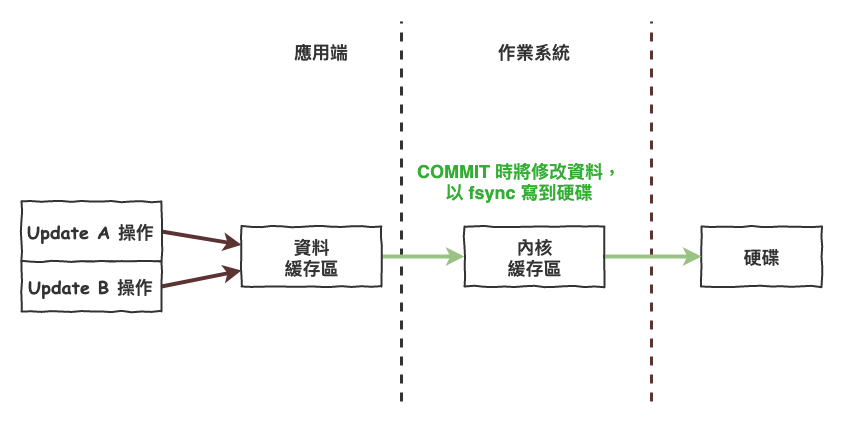
圖 7 : 馬克疑問圖
因為慢。
慢在兩個地方 :
而由於 redo log 只是往個檔案進行追加操作,它屬於順序 i/o 與隨機 i/o 相比之下,順序 i/o 較快,所以才會使用 redo log 寫完硬碟來當回應。然後在偷偷的來處理實際資料寫入。
莫慌 ! 不影響。
因為對一個事務來說,預設是要將 redo log 檔寫到硬碟後才回傳 ok,如上圖 5 的流程 5 所示,所以如果 redo log 寫入時失敗了,那就代表這個事務失敗,客戶端就會知道它是失敗的。而不會發生,明明說回應正常,但是下一次去領錢卻發現沒錢的問題。
莫慌 ! 別忘了有 redo log,它記錄好了那個 page 要修改,用它就可以復活。
基本上熟悉資料庫的人都會知道,我上述的兩個問題,就事務的特性 ACID 中的其中兩個 :
就是事務的運行只有兩個結果 :
而在 mysql innodb 的實現就是使用 undo log。
這個特性主要是說 :
當事務執行 commit 時,對系統的影響是永久的
就如上述原因 2 一樣,如果是用正常的 write ( 寫到緩衝區後就回應 ok ),那就不能滿足持久性。
而 mysql innodb 的實現基於兩個重點在於『 redo log 』加『 fsync 』。
而不單獨使用 fsync 是因為性能考量。
在 mysql innodb 事實上有提供一個設定,可以讓我們犧牲持久性,來大量的提供效能,但是要不要使用請自已判斷。
innodb_flush_log_at_trx_commit
它有三個參數設定。
在 mysql 技術內幕 innodb 這本書中,作者有測試過以上三這的效能差異,如下。
| innodb_flush_log_at_trx_commit | 插入 50 萬行資料花費時間 |
|---|---|
| 0 | 13.90 sec |
| 1(預設) | 1 m 52.11 sec |
| 2 | 23.73 sec |
從上面結果可知,只要調整成 0 或 2 時,執行花費時間效能提升非常的多,因為這兩個參數不會一直寫到硬碟中。但是調整後就是不包證 ACID 的一致性,這就是開發者要自行權衡的地方。
~ 小知識 ~
注意一下你看這個參數為 innodb_flush_log_at_trx_commit,然後有些人可能會想到 linux 所提供的方法 fflush,這個和上述說的 fsync 不太一樣喔。
本篇文章中咱們說說單機故障時,可能會碰到的數據不一致性問題,並且咱們理解了 mysql 它是如何解決這兩個事情。
當初在研究這個主題的時後,看了不少文章發現,它們都是先介紹事務,然後在介紹 ACID,然後才開始說明什麼是 undo 或 redo,但是我覺得這樣不太好讓人理解。
主要的原因在於 :
一定是先有問題,才有解決工具
如果不先理解問題是什麼,而真接去看解決工具,你確定你找到的是正確的工具嗎,又或是你可以正確理解它的解法嗎 ?
不過這只是咱自已的想法,沒啥對與錯。

