在前三天的內容中,我們已經把文章和回應都存到資料庫中了,但如果都是用新增的方式,每次執行時如果抓到同一篇文章都會在資料庫中多出一筆,很容易造成後續分析時的誤差。今天會試著判斷文章和回應是否重複,如果重複就改成更新資料。
對於文章或者回應,我們都需要找出可以用來「識別」的標的用來判斷。
以 iT 邦幫忙的文章來說,每次編輯時都可以修改「標題」、「內容」和「標籤」,所以這三個欄位不適合拿來識別。而「作者」和「發文時間」雖然不會變,但一個作者可能會有多篇文章,發文時間則可能有多個使用者同時發文,所以這兩個欄位也不適合拿來做識別。用刪去法扣一扣,就剩下「網址」可以用來識別了。其實大部分的內容型網站中,網址通常是適合作為識別的資料。
在原本的程式中,只要稍微調整新增的語法就可以達成檢查重複並更新的目的了。
原本的語法:
cursor.execute('''
INSERT INTO public.ithome_article(title, url, author, publish_time, tags, content, view_count)
VALUES (%(title)s,%(url)s,%(author)s,%(publish_time)s,%(tags)s,%(content)s,%(view_count)s)
RETURNING id;
''',
article)
改成:
cursor.execute('''
INSERT INTO public.ithome_article(title, url, author, publish_time, tags, content, view_count)
VALUES (%(title)s,%(url)s,%(author)s,%(publish_time)s,%(tags)s,%(content)s,%(view_count)s)
ON CONFLICT(url) DO UPDATE
SET title=%(title)s,
tags=%(tags)s,
content=%(content)s,
update_time=current_timestamp
RETURNING id;
''',
article)
並在 ithome_article 資料表中加上一組 unique constraint。
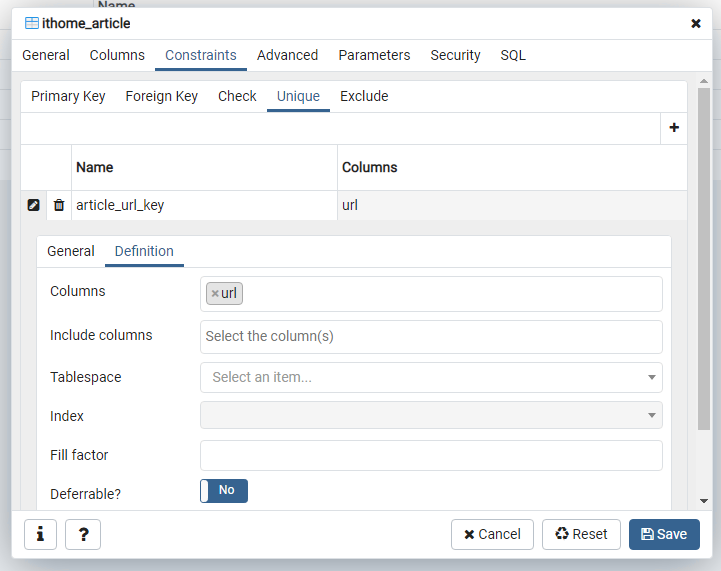
這是利用 PostgreSQL 的 ON CONFLICT 語法來完成的,不同資料庫可能會有不同的實作方式。
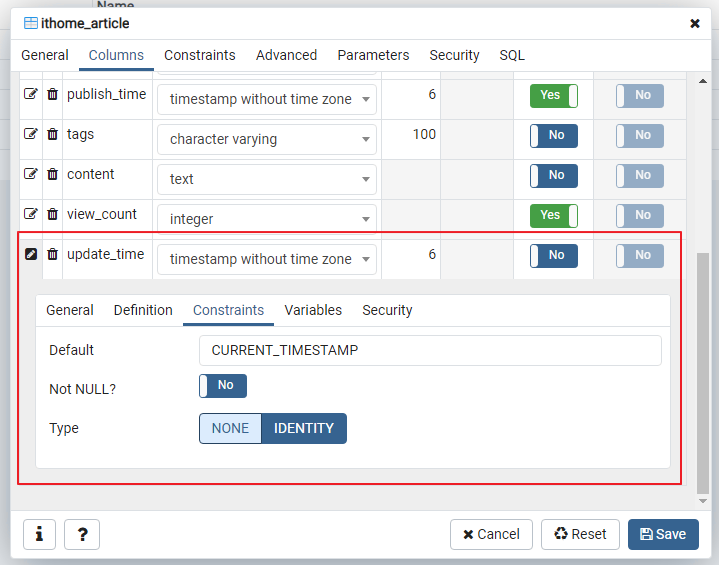
為了觀察資料是否有更新,也加入一個 update_time 欄位,新增或修改時都會設定為當下時間。
執行時發現非鐵人賽文章的 class 定義不太一樣,所以有修改抓取文章的部分程式碼
回應就不像文章可以用網址來判斷是否重複了,最好做的有兩種方式:
那要怎麼做比較好呢?再觀察一下 HTML 原始碼,在回應的區塊中發現了一個神祕的元素:
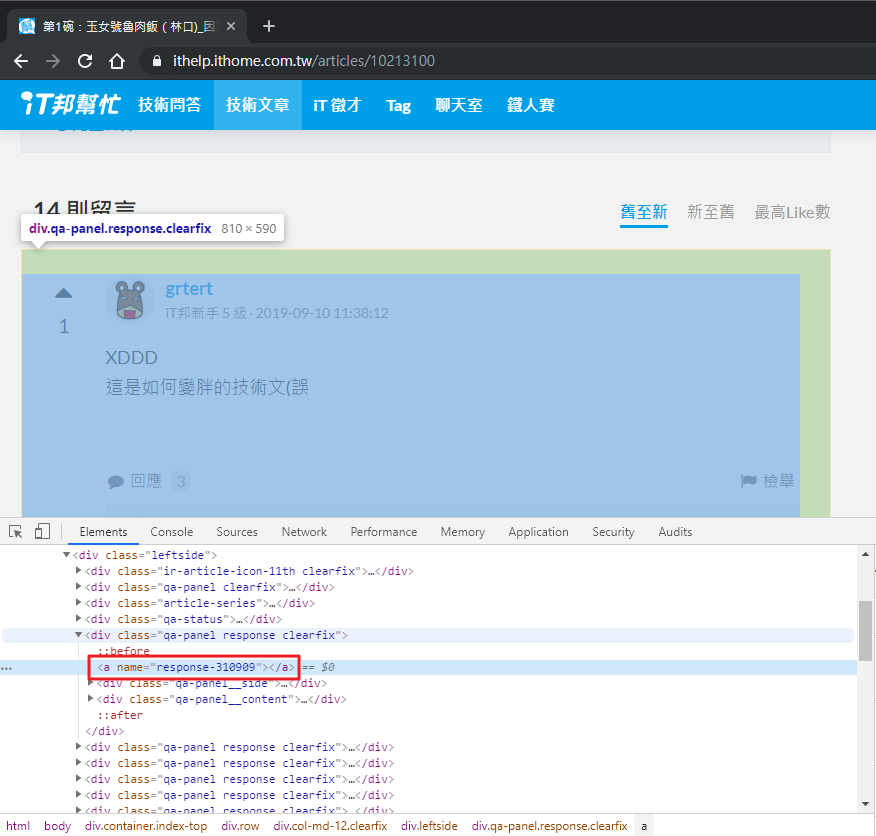
咦????看起來好像有點像回應的 ID,多看了同一篇的幾個回應和其他文章的回應後,好像真的是耶?那就拿來用吧!
不要問我為什麼知道,就剛好看到XD
在抓回應的邏輯中加上一段:
# 回應 ID
result['id'] = int(response.find('a')['name'].replace('response-', ''))
修改新增的語法:
cursor.execute('''
INSERT INTO public.ithome_response(id, article_id, author, publish_time, content)
VALUES (%(id)s, %(article_id)s,%(author)s,%(publish_time)s,%(content)s)
ON CONFLICT(id) DO UPDATE
SET content=%(content)s;
''',
response)
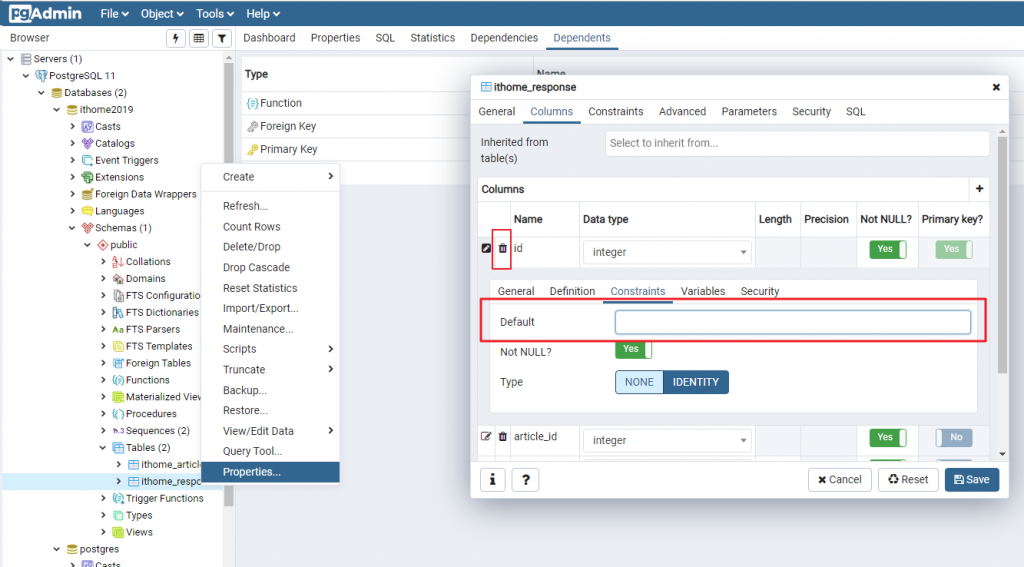
因為原本的 id 欄位是 sequence 類型,要改成一般的 integer。在資料表上點選「右鍵 > Properties」,修改 id 欄位,把 Constraints 的 Default 值拿掉(原本可能是 nextval('ithome_response_id_seq'::regclass)):
今天一樣把完整程式碼放到 gist 上了。明天繼續來試著把資料放到 MongoDB 中吧!


 iThome鐵人賽
iThome鐵人賽