在 Day 22 的文章中有提到 Scrapy Engine 和 Downloader 間的資料傳遞會經過一系列的 Downloader Middlewares,也就是下圖紅框中的區塊。
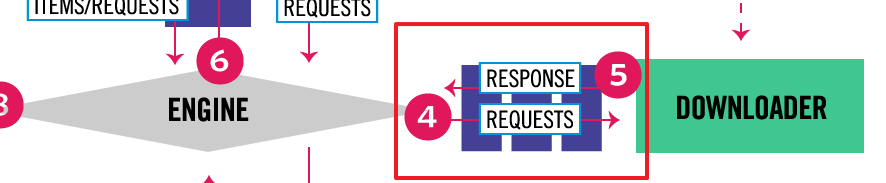
記得 Day 20 和 Day 21 介紹的反爬蟲機制嗎?只要是可以在發送請求前動手腳的應對方式(例如 User-Agent、puppeteer),都很適合在 Downloader Middlewares 中實作,今天就來介紹怎麼使用 Downloader Middlewares。
每一個 Middleware 元件都是一個 Python 類別,不需要繼承其他類別,只要視需求實作部分的下列方法即可:
Downloader 之前執行Scrapy Engine 之前執行。Downloader 或 process_request() 拋出異常時執行。專案建立時,目錄中有一個 middlewares.py 檔案,其中有 Scrapy 根據專案名稱自動建立的 IthomeCrawlersDownloaderMiddleware 類別,就可以看出每個元件可以實作的方法和每個方法應該回傳的類型。
class IthomeCrawlersDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
之前有介紹利用 fake-useragent 套件來隨機產生 UA,這種每個請求都要處理的邏輯就很適合放在 Downloader Middlewares 中處理。
記得要先安裝 fake-useragent 套件:
pipenv install fake-useragent
在 middlewares.py 檔案中加入以下程式碼
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
def __init__(self, ua_type):
self.ua = UserAgent()
self.ua_type = ua_type
@classmethod
def from_crawler(cls, crawler):
return cls(
ua_type=crawler.settings.get('RANDOM_UA_TYPE', 'random')
)
def process_request(self, request, spider):
def get_ua():
# 根據設定中 RANDOM_UA_TYPE 的值來隨機產生 UA
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua())
def process_response(self, request, response, spider):
'''測試用,確認有隨機產生 UA
實際使用時可以拿掉
'''
spider.logger.info(f'User-Agent of [{request.url}] is [{request.headers["User-Agent"]}]')
return response
跟 Item Pipelines 一樣,Downloader Middlewares 元件也需要加入到執行序列中。在 settings.py 檔案中有一個 dict 型態的 DOWNLOADER_MIDDLEWARES 變數,key 是元件的完整名稱,value 是 0~1000 的整數,請求會由數字小到大依序執行,回應則會由數字大到小依序執行。
Scrapy 已經有預設啟用一些 Download Middlewares 元件了,加入自訂的元件時需要額外注意執行順序。其中預設有啟用 UserAgentMiddleware,如果要改用剛剛建立的元件,建議把這個停用。
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ithome_crawlers.middlewares.RandomUserAgentMiddleware': 500,
}
啟動爬蟲時可以看到元件已被加入 Middlewares 序列中。

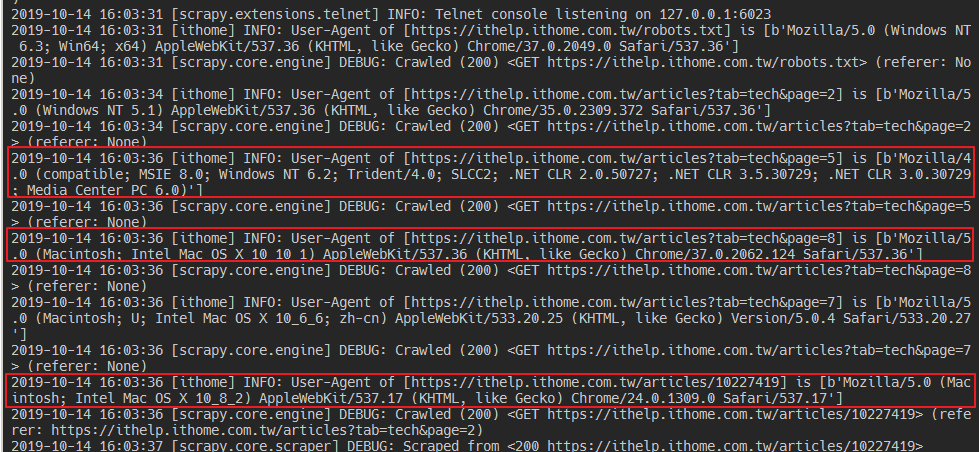
同時在 log 中也可以看到確實有隨機產生 UA。
默默的過了 30 天,好像前面爬蟲基礎寫了太多 ,絕對不是拖稿,Scrapy 還有很多東西沒講......
接下來還是會繼續更新,把預期要寫的東西寫完! 但更新頻率可以會變成兩天一篇之類的

