
我們今天將昨天的成果近一步的優化並且訓練,看看訓練成果會不會更好。
其實資料處理方式有分很多種,我們可以參考以下的文章(對,有是一堆文章),並且這些中文、英文名稱常常會混用,建議使用看公式去記(強烈建議),看過以下文件你就會知道了(越看越吐血)。
機器學習中之規範化,中心化,標準化,歸一化,正則化,正規化
轉:數據標準化/歸一化normalization
標準化和歸一化什麼區別?
【資料科學】 - 資料的正規化與標準化
我們所使用的標準化公式是: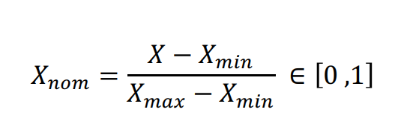
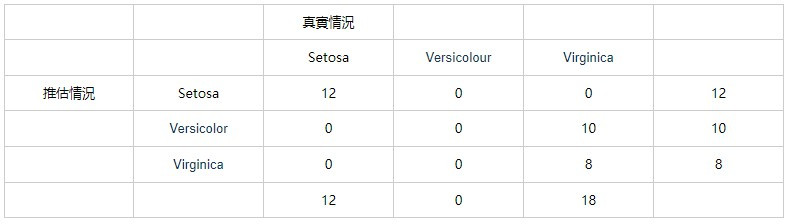
(1) Overall acurracy:推估正確/總樣本數 = 20/30 = 66.66%
(2) Kappa:(pa-pe) / (1-pe)
其中pa = overall acrracy = 66.66%
pe = (12 * 12 + 0 * 10 + 18 * 8) / 30 / 30 = 0.32
因此kappa為:(pa-pe)/(1-pe) :(0.667-0.320) / (1-0.320) = 0.510
所以我們可以看的出來資料的準確度又提升了,然而跟KNN比起來還是比較低,可能是Sample太少,MLP的參數太多,所以訓練的成果比較差。
MLP就告一段落了,之後就是迴歸,我們會從最經典的最小二乘法(Least Squares)開始
<?php
require_once __DIR__ . '/vendor/autoload.php';
use Phpml\Dataset\CsvDataset;
use Phpml\Classification\MLPClassifier;
use Phpml\NeuralNetwork\ActivationFunction\PReLU;
use Phpml\NeuralNetwork\ActivationFunction\Sigmoid;
//讀取Excel
$dataset = new CsvDataset('iris.csv',4);
//取得相關數值
$getSample = $dataset->getSamples();
$getTargets = $dataset->getTargets();
//取出分類
$targetsSingle = Array();
for($i=0; $i<count($getTargets); $i++){
if(!in_array($getTargets[$i], $targetsSingle)){
$targetsSingle[] = $getTargets[$i];
}
}
//陣列內容字串轉float
//因在訓練MLP提供的樣本內容值需要為float
$getSampleFloat= Array();
for($i=0; $i<count($getSample); $i++){
for($t=0; $t<count($getSample[$i]); $t++){
$getSampleFloat[$i][$t] = (float)$getSample[$i][$t];
}
}
//------標準化&20% 80% Start------
// max(最大化)
$sepalLength_max = 0;
$sepalWidth_max = 0;
$petalLength_max = 0;
$petalWidth_max = 0;
// min(最小化)
$sepalLength_min = 0;
$sepalWidth_min = 0;
$petalLength_min = 0;
$petalWidth_min = 0;
// array(標準化數值)
$sepalLength_array = [];
$sepalWidth_array = [];
$petalLength_array = [];
$petalWidth_array = [];
for($i=0; $i<count($getSampleFloat); $i++){
if($i==0){
// max(最大化參數賦予初始值)
$sepalLength_max = $getSampleFloat[$i][0];
$sepalWidth_max = $getSampleFloat[$i][1];
$petalLength_max = $getSampleFloat[$i][2];
$petalWidth_max = $getSampleFloat[$i][3];
// min(最小化參數賦予初始值)
$sepalLength_min = $getSampleFloat[$i][0];
$sepalWidth_min = $getSampleFloat[$i][1];
$petalLength_min = $getSampleFloat[$i][2];
$petalWidth_min = $getSampleFloat[$i][3];
}
// max(比較最大化)
if($getSampleFloat[$i][0] > $sepalLength_max){
$sepalLength_max = $getSampleFloat[$i][0];
}
if($getSampleFloat[$i][1] > $sepalWidth_max){
$sepalWidth_max = $getSampleFloat[$i][1];
}
if($getSampleFloat[$i][2] > $petalLength_max){
$petalLength_max = $getSampleFloat[$i][2];
}
if($getSampleFloat[$i][3] > $petalWidth_max){
$petalWidth_max = $getSampleFloat[$i][3];
}
// mix(比較最小化)
if($getSampleFloat[$i][0] < $sepalLength_min){
$sepalLength_min = $getSampleFloat[$i][0];
}
if($getSampleFloat[$i][1] < $sepalWidth_min){
$sepalWidth_min = $getSampleFloat[$i][1];
}
if($getSampleFloat[$i][2] < $petalLength_min){
$petalLength_min = $getSampleFloat[$i][2];
}
if($getSampleFloat[$i][3] < $petalWidth_min){
$petalWidth_min = $getSampleFloat[$i][3];
}
}
// x'= (x-min)/(max - min) 標準化數值(有效值取到小數第三位)
for($i=0; $i<count($getSampleFloat); $i++){
$sepalLength_array[] = round(($getSampleFloat[$i][0]-$sepalLength_min)/($sepalLength_max-$sepalLength_min), 3);
$sepalWidth_array[] = round(($getSampleFloat[$i][1]-$sepalWidth_min)/($sepalWidth_max-$sepalWidth_min), 3);
$petalLength_array[] = round(($getSampleFloat[$i][2]-$petalLength_min)/($petalLength_max-$petalLength_min), 3);
$petalWidth_array[] = round(($getSampleFloat[$i][3]-$petalWidth_min)/($petalWidth_max-$petalWidth_min), 3);
}
$count_total = count($getSampleFloat);
$count_20percent = round($count_total * 0.2);
$count_80percent = $count_total - $count_20percent;
$total_sample = Array();
for($i=0; $i<count($sepalLength_array); $i++){
$tempArrayValue = array(
$sepalLength_array[$i],
$sepalWidth_array[$i],
$petalLength_array[$i],
$petalWidth_array[$i],
);
$total_sample[] = $tempArrayValue;
}
$samples_20percent = Array(); //宣告20% samples 為Array
$labels_20percent = Array(); //宣告20% labels 為Array
$samples_80percent = Array(); //宣告80% samples 為Array
$labels_80percent = Array(); //宣告80% labels 為Array
/**
* 取得20%數量的亂數
*/
$randValue = Array(); //定義為陣列
$count = $count_20percent; //產生指定數量
for ($i=1; $i<=$count; $i++) {
$randValueTemp = mt_rand(0,count($getSampleFloat)-1); //產生0~(總數量-1)的亂數
if (in_array($randValueTemp, $randValue)) { //如果已產生過迴圈重跑
$i--;
}else{
$randValue[] = $randValueTemp; //若無重復則將亂數塞入陣列
}
}
asort($randValue); //排序
foreach($randValue as $value){
//把陣列內的亂數讀出,就將要的20% samples跟labels寫入到指定變數內
$samples_20percent[] = $total_sample[$value];
$labels_20percent[] = $getTargets[$value];
//刪除已取出資料的陣列元素
unset($total_sample[$value]);
unset($getTargets[$value]);
}
//20%擷取完畢資料,剩下的資料為80%的部分,array_values()方法函式會返回所指定陣列中所有的值並將其建立新索引(由0開始)。
$samples_80percent = array_values($total_sample);
$labels_80percent = array_values($getTargets);
//------標準化&20% 80% End------
//$mlp = new MLPClassifier(Sample的數量, [[第一個隱藏層(兩個神經元), new 激活函數, [第二個隱藏層(兩個神經元), new 激活函數]], [分類的三種類別]);
$mlp = new MLPClassifier(4, [[2, new PReLU], [2, new Sigmoid]], $targetsSingle);
//訓練MLP僅提供樣本和標籤
$mlp->train(
$samples = $samples_80percent,
$targets = $labels_80percent
);
echo("<pre>");
var_dump($mlp->predict($samples_20percent));
var_dump($labels_20percent);
echo("</pre>");
exit();
?>
