在前幾天的爬蟲中,我們都是以 Python dict 的結構在儲存爬取結果,隨著爬蟲數量增加,會在越來越多的程式中使用到相同的結構來儲存資料,但同時也容易在不同爬蟲中打錯欄位名稱(例如 title 打成 titl)或者回傳結構不同的項目。好在 Scrapy 有提供一個 Item 類別,讓我們能先定義好爬取結果的欄位。
建立好專案後,專案目錄中會有一個 items.py 檔案,其中有 Scrapy 根據專案名稱自動建立的 IthomeCrawlersItem 類別,通常我會把自訂的項目類別也放在這個檔案中。每個自訂的項目都要繼承 scrapy.Item 類別,欄位則以 scrapy.Field() 來定義。
import scrapy
class IthomeCrawlersItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
接下來在 item.py 檔案中加入代表文章資料的類別 IthomeArticleItem,並分別定義好每個欄位:
class IthomeArticleItem(scrapy.Item):
url = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publish_time = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
view_count = scrapy.Field()
定義好 Item 後就可以在程式中使用這個類別了,使用的方式跟 dict 幾乎一樣:
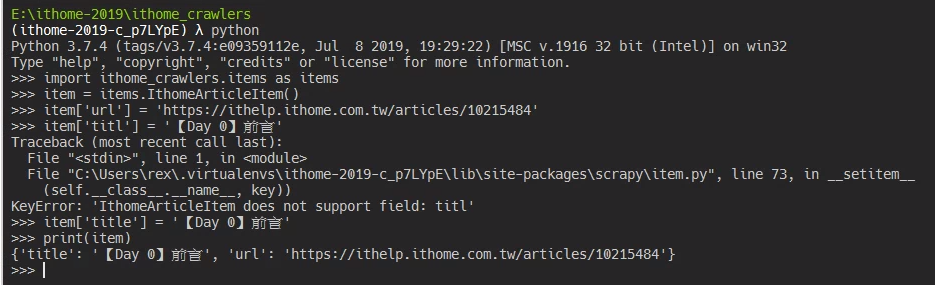
import ithome_crawlers.items as items
# 初始化實例
item = item.IthomeArticleItem()
item['url'] = 'https://ithelp.ithome.com.tw/articles/10215484'
# 打錯欄位名稱會報錯:KeyError: 'IthomeArticleItem does not support field: titl'
item['titl'] = '【Day 0】前言'
item['title'] = '【Day 0】前言'
print(item)
再來把昨天的爬蟲修改為使用剛剛定義的 IthomeArticleItem 類別,完整程式碼可以到 gist 查看。
其實就是把原本的:
article = {
'url': response.url,
'title': title,
'author': author,
'publish_time': published_time,
'tags': ','.join(tags),
'content': content,
'view_count': view_count
}
改成:
article = items.IthomeArticleItem()
article['url'] = response.url
article['title'] = title
article['author'] = author
article['publish_time'] = published_time
article['tags'] = ''.join(tags)
article['content'] = content
article['view_count'] = view_count


 iThome鐵人賽
iThome鐵人賽