決策樹學習完畢,
就要來複雜化決策樹,
進行另一個樹模型「隨機森林」。
以下參考文章:
基本概念就是先 build 多棵 Decision Tree,
然後集合這些 Tree 的力量為一個 Forest, 再來做預測
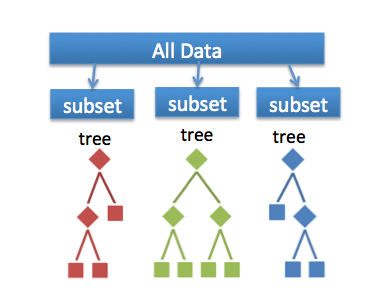
在 training data 中, 從中取出一些 feature & 部份 data 產生出 Tree (通常是CART)
並且重複這步驟多次, 會產生出多棵 Tree 來
最後利用 Ensemble (Majority Vote) 的方法, 結合所有 Tree, 就完成了 Random Forest

從樣本中有放回的抽样。
如果樣本集中有n個樣本,要自助法選出n個樣本,那麼一個樣本被選出的概率是0.632。
Bagging一種採樣方式, 假設全體 training data 有N筆, 你要採集部分資料,
但是又不想要採集到全體的資料 (那就不叫採集了), 要如何做?
一般常見的方式為: 從 N 筆 data 挑資料, 一次挑一筆, 挑出的會再放回去,
最後計算的時候重複的會不算(with replacement),
假設最後為y, N > y, 那 y 就是一次標準的 bagging sampling 樣本數
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(
n_estimators=10, #決策樹的數量
criterion="gini",
max_features="auto", #如何選取 features
max_depth=10,
min_samples_split=2,
min_samples_leaf=1)
隨機森林主要引用sklearn.ensemble集合模型,
決策樹的數量設定越多越不容易overfit,
但時間也會比較長。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽