除了分類和迴歸模型外,
還有樹狀模型可以供選擇,
先來認識一下簡單的決策樹。
參考文章第3.5講 : 決策樹(Decision Tree)以及隨機森林(Random Forest)介紹,

在訓練過程中決策樹會問出一系列的問題像是溫度是否>125,濕度是否<5%之類的是非問題。
首先會從最後上方的樹根開始將資料的特徵將資料分割到不同邊(比方說依據溫度將資料切成三份),
分割的原則是:這樣的分割要能得到最大的資訊增益(Information gain, 簡稱IG)。
由於我們希望獲得的資訊量要最大,因此經由分割後的資訊量要越小越好。
常見的資訊量有兩種:熵(Entropy) 以及 Gini不純度(Gini Impurity)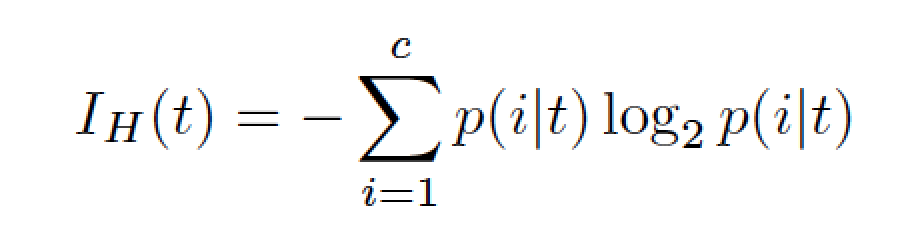
熵資訊量函式

Gini Impurity資訊量函式
以下參考文章HOW DECISION TREE ALGORITHM WORKS,
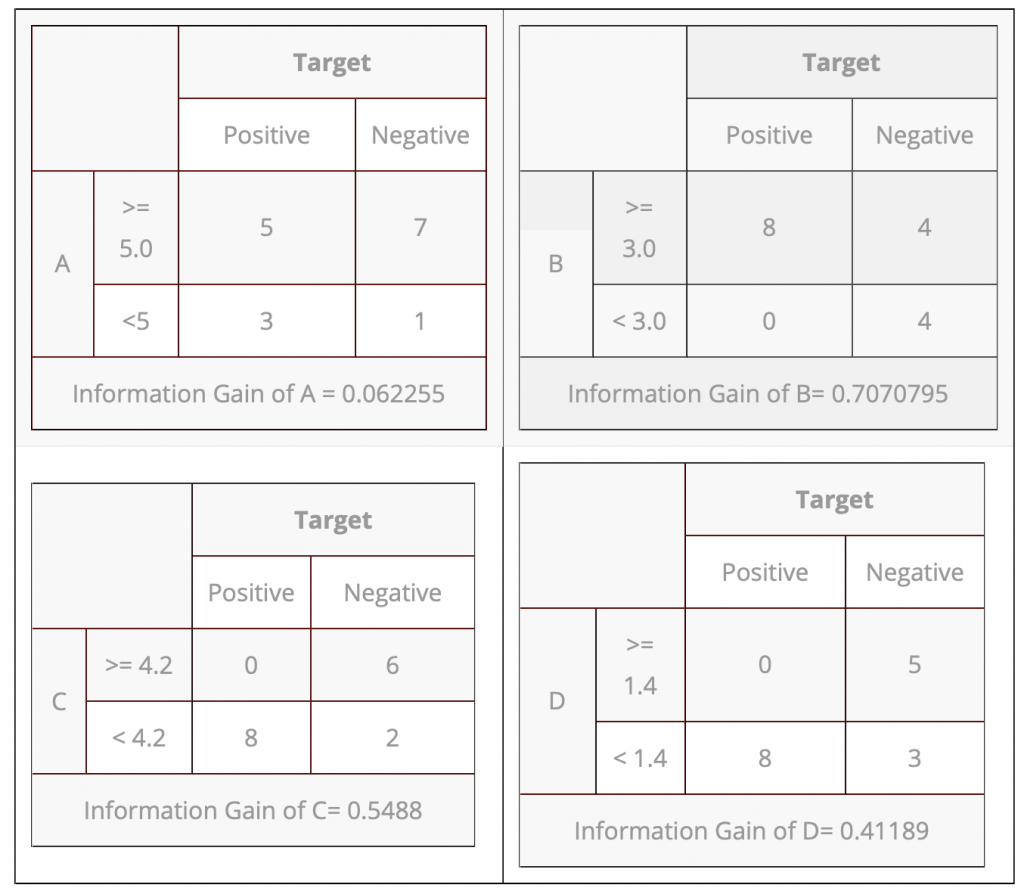
Information Gain of B= 0.7070795為最高,所以由此開始往下分,
接著對Information Gain of C= 0.5488第二高往下分,
最後對Information Gain of D= 0.41189分完,
A的數值太小差距太大,就不分了。

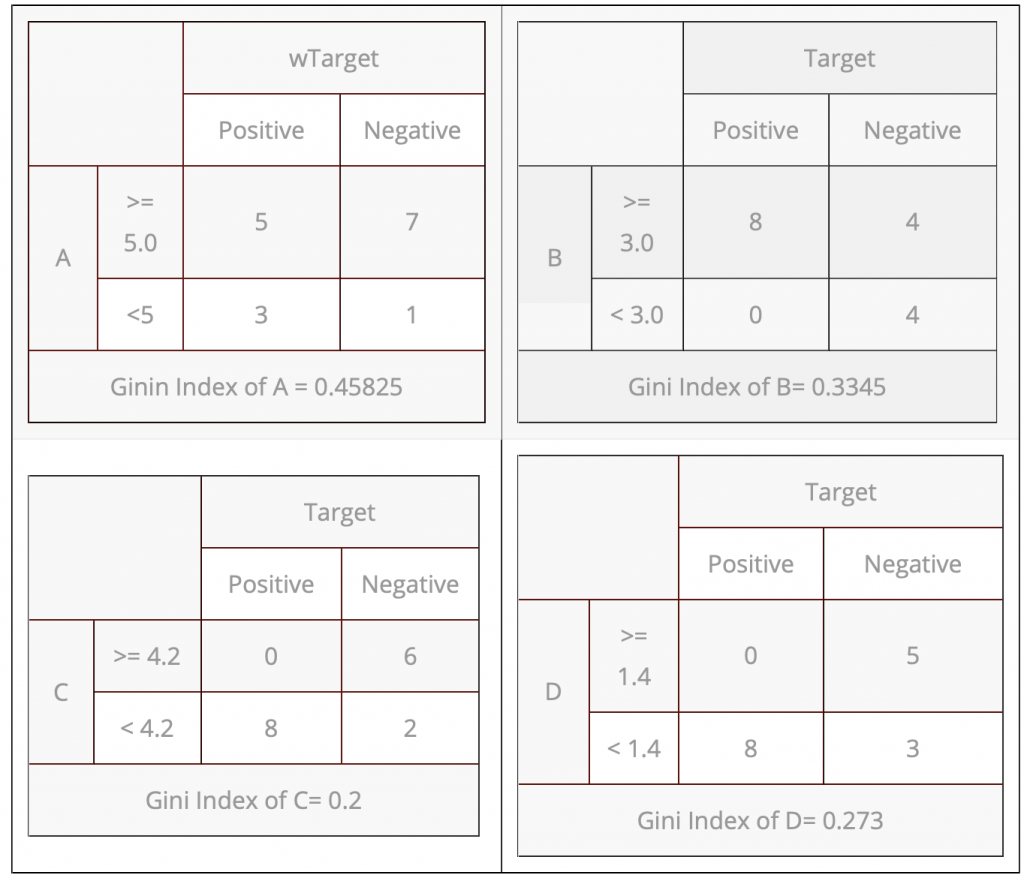
由最小的Gini Index of C= 0.2開始往下分,
再找第二小的Gini Index of D= 0.273往下分,
最後再分Gini Index of B= 0.3345。

from sklearn.tree_model import DecisionTreeRegressor
from sklearn.tree_model import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='gini',max_depth=None,min_samples_split=2,min_samples_leaf=1)
可針對迴歸或分類問題選取function,
並且使用criterion指定決策樹方法,
記得要設定其他參數,來避免overfit。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽