下麵的答案告訴你數據科學(“大數據”)究竟是不是華而不實,以及它和傳統統計學分析方法的具體區別在哪里。
提綱如下:
- “大數據”分析是數據科學特有的麼?
- 用傳統統計學無法處理大數據是因為編程技術不足麼?
- 是不是只有學了“大數據”專業才能在大公司找到工作?
- “大數據“現在的真實情況是什麼呢?
- 大數據“的本質應該是什麼樣的?
答案的內容參考自:Donoho, David. 2017, “50 years of Data Science.” Journal of Computational and Graphical Statistics
事實上並非如此,從歷史上來說,現代統計學的起源是南丁格爾用大量的統計數據和方法製作出了後世有名的“南丁格爾玫瑰圖”從而奠定了現代護理學的基礎,救助了許多戰場士兵的生命。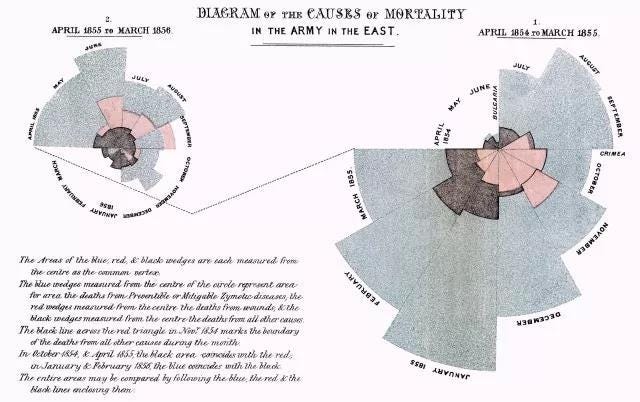
從此以後許多國家(尤其是美國和法國)都開始致力於大量收集各種居民數據,這種數據的搜集稱之為“人口普查”。人口普查可以看作是現在“大數據”的原型,統計學家事實上200年前就開始做這樣的事情了。所以“大數據”並不是2010年中以後的事情,這是許多不了解統計學的人的偏見。
從學科發展的角度來說,統計科學家幾十年前也開始注重研究如何處理“大數據”的問題,比如說當我們有大量的觀測量,同時又有大量的解釋變數的時候應該如何做?所以說覺得“大數據”問題是近幾年才出現,並且缺少學術上的關注的想法也是完全錯誤的。傳統統計學者比誰都更關心“大數據”所導致的問題。別的不說,我們熟知的“抽樣”統計的方法,最初就是為了解決數據量太過龐大,然而計算能力並無法允許我們直接採用全樣本進行估計而設計的。
2010年之後,大多數人覺得“分佈式”計算是未來處理大數據的主要方向,分佈式計算主要的想法是: “組件之間彼此進行交互以實現一個共同的目標。把需要進行大量計算的工程數據分割成小塊,由多臺電腦分別計算,再上傳運算結果後,將結果統一合併得出數據結論的科學。”
然而人們由於過度迷信這種分佈式運算帶來的“便利之處”,早就忘了很久以前,我們可能就已經存在解決問題之道,並且可能甚至比分布式運算來得更好。統計學者們在50年前就開始研究如何利用數據的抽象原理來快速求解及其複雜的整體最優問題,並且早早地在抽象數學和具象的計算遠離之間構架起了橋樑。
分佈式處理技術事實上很多時候與之前發現的技術相比並不具備太大優勢,其最主要的優勢在於:“使用世界各地上千萬志願者電腦的閒置計算能力,通過互聯網進行數據傳輸(志願計算)。”**這樣簡單粗暴的計算方式讓我們不再去思考如何優雅地解決問題,而是把注意力更多地放在如何“更快地得到答案”以及“更實用”這兩點上。
**
**在這種思維模式下,人們越來越少真正去思考數據背後的意義,以及如何策略性地選擇和分析數據的問題。**很可惜,現在市場上的聲音只剩下了“大數據”狂熱者們的搖旗呐喊:“統計有什麼用?只要演算法足夠精妙,電腦足夠強大就行了”。
許多“大數據”愛好者都覺得只有學了大數據專業才有可能會被穀歌或者亞馬遜這樣的大公司錄取。
當然這樣的想法也不是空穴來風,在巨大的市場需求驅動下,現在的確是”大數據“的黃金年代,美國僅僅2014年就有440萬與大數據相關的工作被提供,而大多數的這類職位的需求都是:“你需要懂得電腦編程,以及處理數據”。這就使得許多傳統統計方向畢業的學生直接被拒之門外,只能望洋興嘆。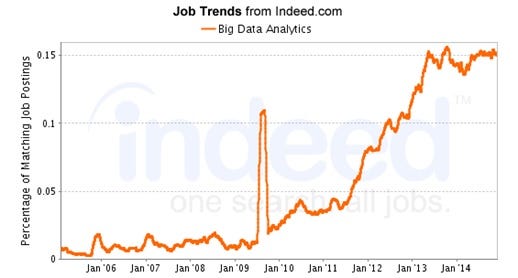
另一方面在大量的市場需求下,許多人有了濫竽充數魚目混珠的機會,這優秀的數據工作者和“普通的”數據工作者往往很難在第一時間被市場分辨出來。這就導致了市場上有太多數據工作者,但是極少數的人能夠夠格稱得上“數據科學家”。大多數時候,一個“數據科學家”的職位往往意味著你需要有很多的工作經驗,或者是名校的統計或者電腦系的博士文憑。真****正的好公司也不傻,大家只願意支付高額薪水給那些真正可以“讀懂”數據的人。而讀懂二字背後意味著不是只是會跑跑程序畫畫統計圖就夠了的。
事實上當下媒體對於“大數據”的許許多多的描述和吹噓,完全經不起任何的推敲。事實上這也可以理解,大多數媒體人和寫手實際上對於統計和電腦科學背後的實際原理可謂是一竅不通,隨便給他們看點東西他們就會震驚到無以復加說不出話。
另一方面的確人類的文明發展也正因為互聯網的關係邁入了一個新的紀元,比如說在2010年之前你去印度旅遊便會發現,當時的印度可以說是100多年來毫無變化和發展。但是2015年開始你再去印度旅遊便會發現事實上許多人都開始使用手機,這背後的意義意味著新添加了八億的線民。八億人每天都在向全世界提供著他們的一舉一動,告訴世界他們的愛好,這些數據被記錄,並且具有著不可估量的潛在商業價值。
如何處理這些數據,並且實現其價值,毫無疑問將會是未來十幾年的商界主要發展方向所在。
無論如何,一門科學並不是應該為了處理每天產生的海量數據,實現商業價值而存在。也不能因為某些政府官員希望借助“大數據”的春風實現個人政績而存在。
真正的科學的意義在於:使用嚴謹的科學方法和技巧來攻克宇宙中永恆存在的重大問題。
過去的五十年來傳統統計學者們已經做了許多學科建設方面的基礎工作。這也意味著數據科學於當今人類而言,並不應該是它被大家“吹噓”成的那個樣子。作為一門嚴肅學科來說,它未來的發展應該是在商業化和智能化之間做一個平衡。未來人們在談及數據科學,談及“大數據”的時候應該多用用腦子,而不是屁股想問題。
“大數據“的真正意義應該是回答:我們究竟從數據中能夠“學習到”什麼?
單憑這一點來說,數據科學可能就是未來五十年裏面所有學科共同關注的發展方向。比如說我們來看一個最簡單的例子:科學的發表本身也可以看成是數據,數據科學家可以從這些數據裏面學習並且分析其他科學工作者的科學工作,並且尋找出方法來使得我們現有的科學工作變得更加精確化從而提高確信度。
閱讀原文:大數據“華而不實”嗎?大數據的本質到底是什麼?
更多數據分析、數據視覺化、大數據知識,歡迎關注數據分析那些事臉書粉絲團
 groots
groots

 iThome鐵人賽
iThome鐵人賽