Bloom filter是一個data structure用來提升速度及記憶體使用的效率。
這個data structure是probabilistic data structure,它可以判斷某個元素(element)是否在某個set內。
雖然存在誤差率,有可能把不屬於這個set的元素誤認為屬於這個set (False Positive),
但不會把屬於這個set的元素誤認為不屬於這個set (False Negative)。
Bloom filter的運作原理就是利用hash function對資料進行hash,然後將得的值透過mod再獲到最終在資料中的位置(它的bit值會轉為1)。當中可變的因素包括hash function的數目、資料的長度及資料的值。
相信大家都可能有些疑問,但不要緊,
大家可以到以下網站(英文版)即時測試一下。
https://llimllib.github.io/bloomfilter-tutorial/
網站有一個例子供大家測試:
1, 預設有一個Bloom filter,有15個index,都是empty的。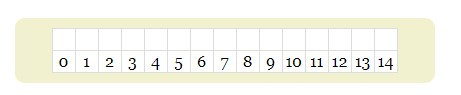
2, 可隨意輸入string,之後會由2個hash function執行hash,由於有2個hash function,所以最後會有2個位置的bit值會被更新為1。同時也可以看到自己的輸入紀錄。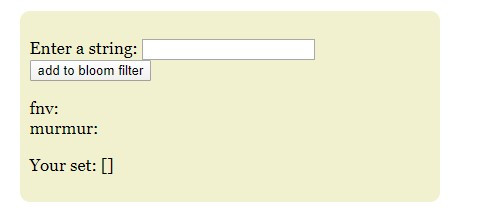
3, 可以透過輸入不同的string來測試一下能否輸入的String是否在剛才的Set中。但值得留意的是會有誤差率,即是你輸入的String顯示是存在剛才的Set中也不一定是真的。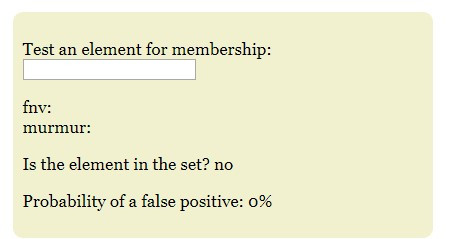
既然有誤差率,那又有什麼作用呢?
1, Tinder內的建議選擇(一般交友APP會看到)
會根據你身處的地方及個人要求作出配對,為了避免重複出現同一選擇(已和你配對或已被你拒絕的對象),系統會將已經出現的選擇加入Bloom filter。這樣用家就不用又再次見到相同的對象。
2, Aadhaar (Unique ID系統)
任何一個Unique ID系統都會為新的註冊用戶產生獨一無二的號碼。假如在短時間有大量用家來註冊成為用戶,就會為數據庫帶來負擔。為了減輕數據庫負擔,可以利用Bloom filter來檢查某個註冊號碼是否已經存在。
3, Cache優化
大家平時上網都會用到搜尋器,搜尋愈多資料就累積了愈多cache。但很多時候大部門的網頁不是我們想用、想看的。進去一次就發現那些網頁不合適,再不想再進去。
不過系統不管你喜不喜歡,由於cache的LRU policy的原因都會把你看過的網頁資料(就算只進去一次)放進cache。時間久了,就會累積大量cache。
為了解決這個問題,可以利用Bloom filter加以優化,使cache只會儲存有多於一次瀏覽紀錄的網頁資料。不會把只有一次瀏覽紀錄的網頁加入cache。
其實Bloom filter的用途可以委廣泛,如果大家想再深入了解及探討,歡迎留言或私下找我研究。
 martinyeung
martinyeung

 iThome鐵人賽
iThome鐵人賽