各位大大
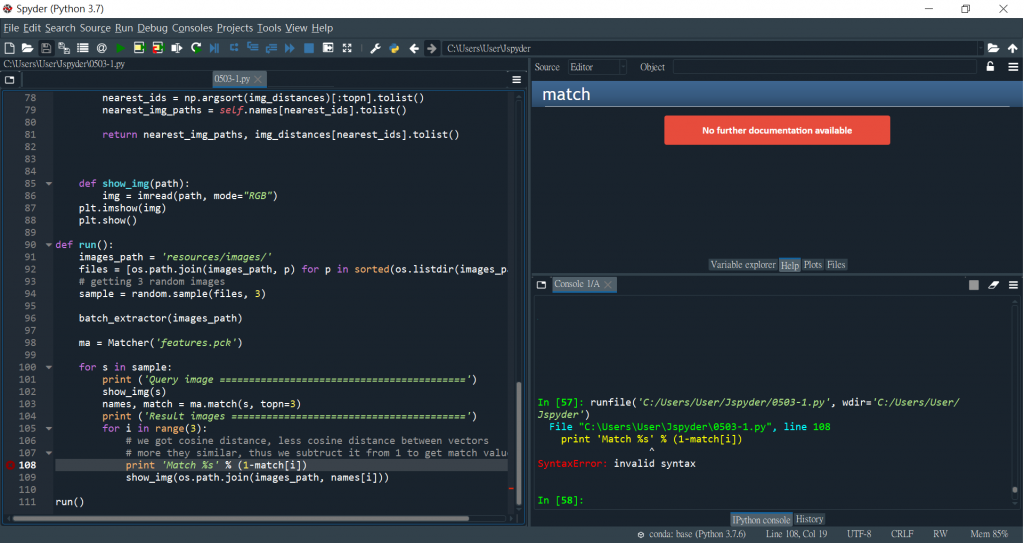
近期在執行以下程式碼出現->SyntaxError: invalid syntax
小弟近日利用網路資源還找不出原因
大概能理解是語法上的問題,不確定括弧應存在的位置
附上程式碼,是否有人能解救T^T
感激!!
import cv2
import numpy as np
import scipy
from scipy.misc import imread
import _pickle as cPickle
import random
import os
import matplotlib.pyplot as plt
def extract_features(image_path, vector_size=32):
image = imread(image_path, mode="RGB")
try:
# Using KAZE, cause SIFT, ORB and other was moved to additional module
# which is adding addtional pain during install
alg = cv2.KAZE_create()
# Dinding image keypoints
kps = alg.detect(image)
# Getting first 32 of them.
# Number of keypoints is varies depend on image size and color pallet
# Sorting them based on keypoint response value(bigger is better)
kps = sorted(kps, key=lambda x: -x.response)[:vector_size]
# computing descriptors vector
kps, dsc = alg.compute(image, kps)
# Flatten all of them in one big vector - our feature vector
dsc = dsc.flatten()
# Making descriptor of same size
# Descriptor vector size is 64
needed_size = (vector_size * 64)
if dsc.size < needed_size:
# if we have less the 32 descriptors then just adding zeros at the
# end of our feature vector
dsc = np.concatenate([dsc, np.zeros(needed_size - dsc.size)])
except cv2.error as e:
print ('Error: '), e
return None
return dsc
def batch_extractor(images_path, pickled_db_path="features.pck"):
files = [os.path.join(images_path, p) for p in sorted(os.listdir(images_path))]
result = {}
for f in files:
print ('Extracting features from image %s') % f
name = f.split('/')[-1].lower()
result[name] = extract_features(f)
# saving all our feature vectors in pickled file
with open(pickled_db_path, 'w') as fp:
cPickle.dump(result, fp)
class Matcher(object):
def __init__(self, pickled_db_path="features.pck"):
with open(pickled_db_path) as fp:
self.data = cPickle.load(fp)
self.names = []
self.matrix = []
for k, v in self.data.iteritems():
self.names.append(k)
self.matrix.append(v)
self.matrix = np.array(self.matrix)
self.names = np.array(self.names)
def cos_cdist(self, vector):
# getting cosine distance between search image and images database
v = vector.reshape(1, -1)
return scipy.spatial.distance.cdist(self.matrix, v, 'cosine').reshape(-1)
def match(self, image_path, topn=5):
features = extract_features(image_path)
img_distances = self.cos_cdist(features)
# getting top 5 records
nearest_ids = np.argsort(img_distances)[:topn].tolist()
nearest_img_paths = self.names[nearest_ids].tolist()
return nearest_img_paths, img_distances[nearest_ids].tolist()
def show_img(path):
img = imread(path, mode="RGB")
plt.imshow(img)
plt.show()
def run():
images_path = 'resources/images/'
files = [os.path.join(images_path, p) for p in sorted(os.listdir(images_path))]
# getting 3 random images
sample = random.sample(files, 3)
batch_extractor(images_path)
ma = Matcher('features.pck')
for s in sample:
print ('Query image ==========================================')
show_img(s)
names, match = ma.match(s, topn=3)
print ('Result images ========================================')
for i in range(3):
print 'Match %s' % (1-match[i])
show_img(os.path.join(images_path, names[i]))
run()
猜測是 Python 2, Python 3, print, print() 方式的關係.
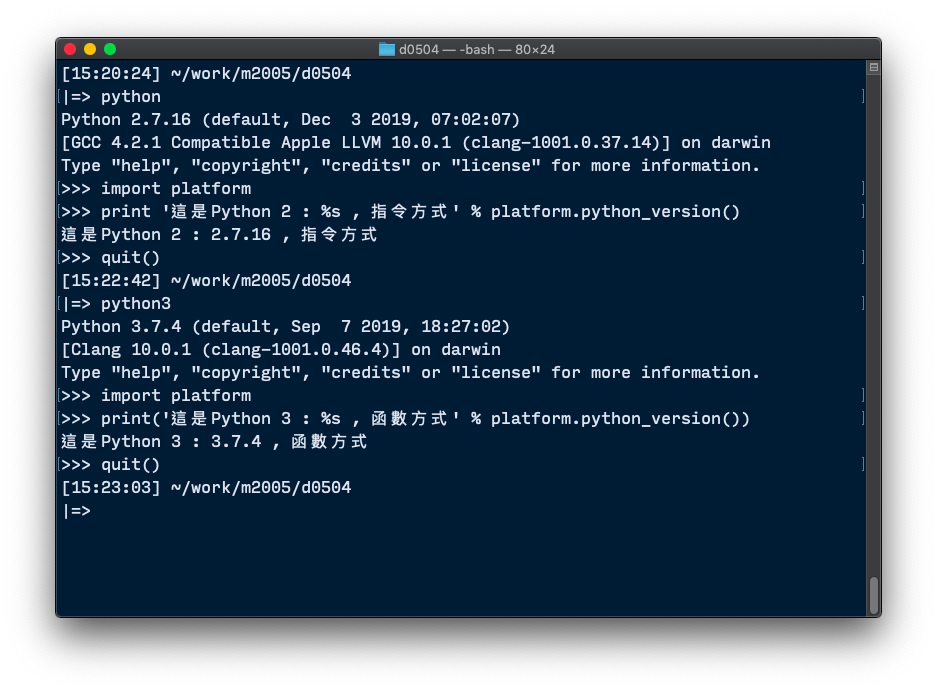
非常感謝!!
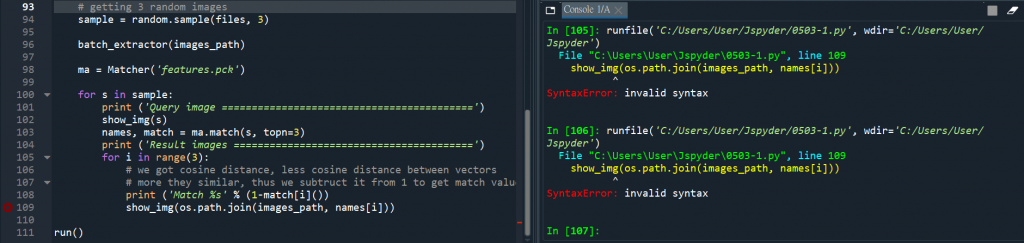
目前已排解前段問題,但來到這又卡住了...
109行
print ('Match %s' % (1-match[i]())
show_img(os.path.join(images_path, names[i]))
run()
另外的問題,另外問.這樣問題才能分類清楚.
問程式,你把程式碼用貼圖的,這裡的問答區,貼圖放大後,字還是非常小,
我根本無法看清.還有你是要別人自己再打一遍? 圖不是不能貼,而是用來補助.
好的,非常感謝提醒!!
 njsu642
njsu642
