ESN是RNN的一個變種,優點在於訓練速度比一般RNN快幾百倍(用回歸求解矩陣)。主要參考下面幾篇文獻,如果沒有接觸過這個網路的朋友請務必先看[1]和[2]。以前碩班有摸過一下,現在因為工作所需又重新複習了下,這邊作個筆記然後有空在畫成圖上傳到這篇。下面會有兩個代碼實現,但請注意這兩個代碼所實現的ESN結構略有不同,所以請務必看一下文獻提到的Paper。
總共看了兩個代碼(ESN鼻祖的學生[6]、Medium網友[7]),後者算是變種版。下面會提供自己修改後的版本,其運行結果與原代碼相同,只是稍微修改一下架構和補上自己的註釋:
# -*- coding: utf-8 -*-
"""
原代碼, Mantas Lukoševičius(開山祖師Jaeger的學生), http://mantas.info
數據集可以到Lukoševičius那邊下載
"""
import matplotlib.pyplot as plt
import scipy
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, ElasticNetCV, Lasso, LassoCV
from sklearn.metrics import mean_squared_error
np.random.seed(42)
"""
Step 1. 讀取數據(MackeyGlass_t17),尺寸為(10000, 1)
"""
data = pd.read_table('MackeyGlass_t17.txt', header=None)
"""
Step 2. 定義訓練集長度len_train、測試集長度len_test、暫態長度len_transient、誤差計算長度len_error
"""
len_train = 2000
len_test = 2000
len_transient = min(int(len_train / 10), 100)
len_error = 500
"""
Step 3. 畫出數據前1000筆的曲線
"""
plt.figure('A sample of data').clear()
plt.plot(data[0:1000])
plt.title('A sample of data')
"""
Step 4. 定義ESN架構
輸入層神經元數inSize:
- 等於輸入資料的特徵數
輸出層神經元數outSize:
- 等於目標資料的特徵數
隱藏層神經元數resSize:
- 建議最少100顆,且每次增幅單位為50顆
- 沒看過超過1000的
洩漏率a:
- 加強短期記憶能力,範圍在[0, 1]
- 若a=1則ESN;a<1則Leaky ESN(P7)
輸入層的縮放因子input_scaling
- 範圍在[0, 1]
稀疏程度sparsity:
- 建議在0.01(1%)~0.05(5%),也有人建議0.05(5%)~0.2(20%)
指定譜半徑rho:
- 範圍在[0, 1)
"""
inSize = 1
outSize = 1
resSize = 100
a = 0.3
input_scaling = 1.0
sparsity = 1.00
rho = 1.25
"""
Step 5. 初始化輸入層權重Win、隱藏層權重W
輸入層權重Win:
- 如果有偏權值,則尺寸為(隱藏層神經元數, 1+輸入層神經元數)
- 否則(隱藏層神經元數, 輸入層神經元數)
- 常見範圍在[-1, 1]或者[-0.5, 0.5]
- 建議用常態分布
初始隱藏層權重W_0:
- 尺寸為(隱藏層神經元數, 隱藏層神經元數)
- 常見的初始範圍在[-1, 1]或者[-0.5, 0.5]
- 這邊提供另一種寫法,借鑑於Madalina Ciortan,這個方法才真正達到稀疏效果
- W_0 = scipy.sparse.rand(resSize, resSize, density=sparsity).todense() - 0.5
- scipy.sparse.rand(列數, 行數, density=稀疏程度).todense()
- 假設density=0.1(10%)、列數=10、行數=10,則10x10的矩陣中只有總計10個元素不為零,而且是不規則零散分布在矩陣中
初始隱藏層權重的譜半徑rhoW:
- max( abs( W ))
- rhoW<1,隱藏層才具有ECHO特性
隱藏層權重W:
- W = W_0 * rho/rhoW
"""
Win = (np.random.rand(resSize, 1+inSize)-0.5) * input_scaling
W_0 = np.random.rand(resSize,resSize)-0.5
# W_0 = scipy.sparse.rand(resSize, resSize, density=sparsity).todense()
# W_0[np.where(W_0 > 0)] = W_0[np.where(W_0 > 0)] - 0.5
rhoW = np.max(np.abs(np.linalg.eig(W_0)[0]))
W = W_0 * rho/rhoW
"""
Step 5. 收集:取得每一時刻的狀態x(t),然後存在所有時刻的狀態X中
- t=0時,x(0)為一個尺寸(隱藏層神經元數,1)的零矩陣,y(0)為一個尺寸(1,輸出層神經元數)的零矩陣
- 記憶庫響應狀態x(t=0)=(resSize, 1)
- 有偏權值:x(t) = (1-a)*x(t-1) + a*tanh( Win*[1;u(t)] + W*x(t-1) )
= (隱藏層神經元數,1) = 純量*(隱藏層神經元數,1) + 純量*( (隱藏層神經元數,1+輸入層神經元數)*(1+輸入層神經元數,1) + (隱藏層神經元數, 隱藏層神經元數)*(隱藏層神經元數,1) )
= (隱藏層神經元數,1) = 純量*(隱藏層神經元數,1) + 純量*( (輸入層神經元數,1) + (輸入層神經元數,1) )
- 無偏權值:x(t) = (1-a)*x(t-1) + a*tanh( Win*u(t) + W*x(t-1) )
- 記得要刪掉X的前len_transient筆
"""
X = []
x = np.zeros([resSize, 1])
for t in range(len_train):
u = data.loc[t]
x = (1-a)*x + a*np.tanh( np.dot(Win, np.vstack((1, u))) + np.dot(W, x) )
X.append(np.vstack([1, u, x]))
X = X[len_transient:]
X = np.array(X).reshape(-1, 1+inSize+resSize)
"""
Step 6. 訓練:利用所有時刻的狀態X、所有時刻的目標Yt,以Ridge回歸求得輸出層權重Wout
- 輸出層權重的尺寸為(輸出層神經元數, 1+輸入層神經元數+隱藏層神經元數)
- 借鑑Madalina Ciortan,我直接用Ridge取代了Wout
- L1正則的回歸器效果都不太好(Lasso、ElasticNet),我猜是因為很多權重被刪掉的關係
- y(t) = Wout*[1;u(t);x(t)]
(輸出層神經元數,1) = (輸出層神經元數,1+輸入層神經元數+隱藏層神經元數)*(1+輸入層神經元數+隱藏層神經元數,1)
"""
Yt = data.loc[len_transient+1:len_train]
ridge = Ridge(alpha=1e-8)
ridge.fit(X, Yt)
"""
Step 7. 測試
- 第一筆測試輸入u(t-1)=data[2000]
- 第一筆狀態x(t-1)延續於Step 5
- Y是用來記錄模型在測試階段各時刻的輸出
- 作者提供兩種模型輸出:遞迴式多步預測和單步預測,選一個用就可以了
- 有偏權值:x(t) = (1-a)*x(t-1) + a*tanh( Win*[1;u(t)] + W*x(t-1) )
y(t) = Wout*[1;u(t);x(t)]
- 無偏權值:x(t) = (1-a)*x(t-1) + a*tanh( Win*u(t) + W*x(t-1) )
y(t) = Wout*[u(t);x(t)]
"""
Y_pred = []
u = data.loc[len_train]
for t in range(len_test):
x = (1-a)*x + a*np.tanh( np.dot( Win, np.vstack([1,u]) ) + np.dot( W, x ) )
y = ridge.predict(np.vstack((1,u,x)).T)
Y_pred.append(y)
# 遞迴式多步預測,也就是當前時刻的模型輸出會作為下一刻模型的輸入
u = y
# 單步預測,當前時刻的輸入數據是從實際量測或者離線數據中取得
# u = data.loc[len_train+t+1]
Y_pred = np.array(Y_pred)
Y_pred = Y_pred.reshape(-1, outSize)
"""
Step 8. 採MSE計算測試集中前len_error筆誤差
- 為什麼只計算len_error筆誤差,因為Mantas當初是採遞迴式多步預測作為輸出方式
- 遞迴式多步預測(Recursive Multi-Step Forecasting)的問題在於預測能力會隨著時間而衰弱,從本代碼的執行結果中也顯而易見
- 所以我猜這就是他只取500筆作計算的原因
"""
mse = mean_squared_error(data.loc[len_train+1:len_train+len_error], Y_pred[:len_error])
print('MSE = ' + str( mse ))
"""
畫出測試集輸入訊號
"""
plt.figure('Target and generated signals').clear()
plt.plot(data.loc[len_train+1:len_train+len_test].to_numpy(), 'g')
plt.plot( Y_pred, 'b' )
plt.title('Target and generated signals $y(n)$ starting at $n=0$')
plt.legend(['Target signal', 'Free-running predicted signal'])
"""
畫出20條權重在t=100~300的狀態響應X
"""
plt.figure('Some reservoir activations').clear()
plt.plot( X[0:200, 0:20] )# 看起來是t=0~200,但加上沖洗時間initLen=100後應為t=100~300
plt.title('Some reservoir activations $\mathbf{x}(n)$')
"""
畫出輸出權重的值
"""
plt.figure('Output weights').clear()
plt.bar( range(1+inSize+resSize), ridge.coef_.ravel() )
plt.title('Output weights $\mathbf{W}^{out}$')
plt.show()
遞迴式多步預測結果,可以注意到從第1000筆開始發散,所以Lukoševičius才會只取500筆計算誤差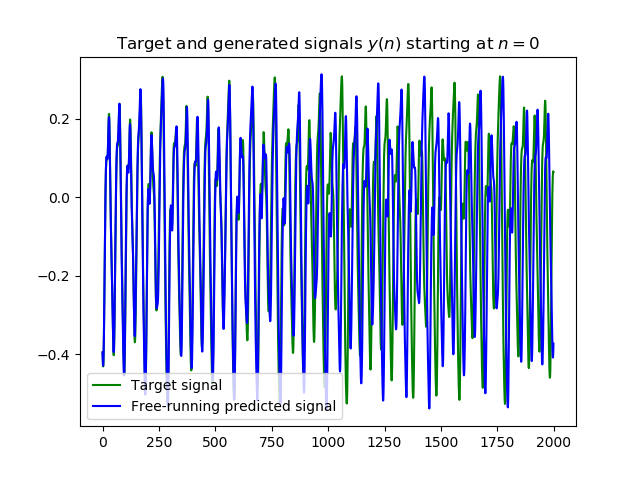
單步預測結果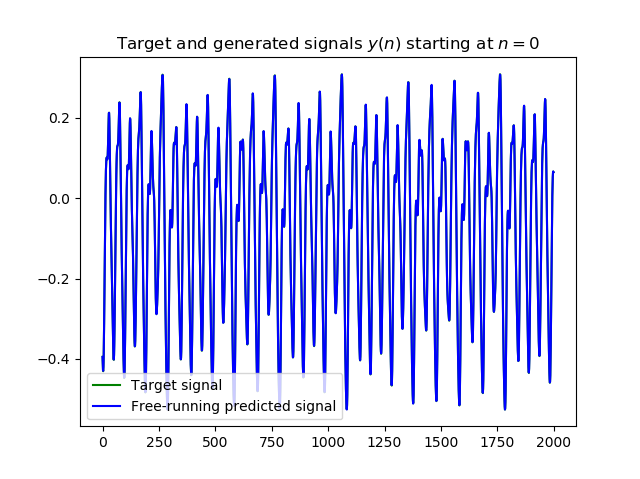
Medium網友[7]:
# -*- coding: utf-8 -*-
"""
重點文獻:
1. Reservoir computing approaches for representation and classification of multivariate time series
2. https://towardsdatascience.com/gentle-introduction-to-echo-state-networks-af99e5373c68
"""
import numpy as np
import scipy.io
from scipy import sparse
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
from sklearn.linear_model import Ridge
from sklearn.metrics import accuracy_score, f1_score
"""
Reservoir implementation
"""
class Reservoir(object):
def __init__(self, n_internal_units=100, spectral_radius=0.99, leak=None,
connectivity=0.3, input_scaling=0.2, noise_level=0.01, circle=False):
"""
Step 1. 建立參數
- n_internal_units = 記憶庫神經元,某文獻說約在300~100,但我看過的期刊最少都100起跳
- input_scaling = Win的縮放因子
- noise_level = 白噪音的縮放因子
- leak = 洩漏率,範圍在[0, 1]之間
"""
self._n_internal_units = n_internal_units
self._input_scaling = input_scaling
self._noise_level = noise_level
self._leak = leak
"""
Step 2. 輸入權重Win初始化為None
- _input_weights = 輸入權重
"""
self._input_weights = None
"""
Step 3. 根據遞迴機制circle啟用與否(Wr),來決定記憶庫權重W的建立方式
- circle = 遞迴機制
- _internal_weights = 記憶庫權重,size=[n_internal_units, n_internal_units]
"""
if circle:
# W+Wr
self._internal_weights = self._initialize_internal_weights_Circ(n_internal_units,
spectral_radius)
else:
# W
self._internal_weights = self._initialize_internal_weights(n_internal_units,
connectivity,
spectral_radius)
def _initialize_internal_weights_Circ(self, n_internal_units, spectral_radius):
"""
"""
internal_weights = np.zeros((n_internal_units, n_internal_units))
internal_weights[0,-1] = spectral_radius
for i in range(n_internal_units-1):
internal_weights[i+1,i] = spectral_radius
return internal_weights
def _initialize_internal_weights(self, n_internal_units,
connectivity, spectral_radius):
"""
Step 4. 以常態分佈產生稀疏度connectivity的記憶庫權重W
- internal_weights = 記憶庫權重W,size=[n_internal_units, n_internal_units]
- connectivity = 稀疏度,部分期刊建議設1%~5%。例如某個10X10的矩陣,稀疏度設10%,則矩陣中只有10個元素不為零。
- spectral_radius = 譜半徑,必須要<1
"""
internal_weights = sparse.rand(n_internal_units,
n_internal_units,
density=connectivity).todense()
"""
Step 5. 記憶庫權重W所有非零項範圍從0~+1=>-0.5~+0.5
"""
internal_weights[np.where(internal_weights > 0)] -= 0.5
"""
Step 6. 求得記憶庫權重W的特徵值E,然後以e_max=max( abs( E ) )和譜半徑spectral_radius調整記憶庫權重W
- W = (spectral_radius*W)/e_max
- 這邊的spectral_radius為調整譜半徑用的係數
- 實際上W的譜半徑是e_max沒有錯
"""
E, _ = np.linalg.eig(internal_weights)
e_max = np.max(np.abs(E))
internal_weights /= np.abs(e_max)/spectral_radius
return internal_weights
def _compute_state_matrix(self, X, n_drop=0):
"""
Step 10. 初始化過往狀態x(t)
previous_state = 過往狀態,size=[N, _n_internal_units]
"""
N, T, _ = X.shape
previous_state = np.zeros((N, self._n_internal_units), dtype=float)
"""
Step 11. 建立狀態矩陣X
state_matrix = 狀態矩陣,size=[N, T-n_drop, _n_internal_units]
"""
state_matrix = np.empty((N, T - n_drop, self._n_internal_units), dtype=float)
for t in range(T):
# 取得當前輸入u(t)
current_input = X[:, t, :]
# 計算活化函數前的狀態狀態x(t)
# state_before_tanh = W*x(t-1)+Win*u(t)
state_before_tanh = self._internal_weights.dot(previous_state.T) + self._input_weights.dot(current_input.T)
# 加入白噪音
#state_before_tanh = W*x(t-1)+Win*u(t) + random*_noise_level
state_before_tanh += np.random.rand(self._n_internal_units, N)*self._noise_level
# 加入非線性tanh()以及洩漏率_leak
# 雖然原作者列了條件,但應該可以概括為x(t) = (1-a)*x(t-1) + tanh(W*x(t-1)+Win*u(t) + random*_noise_level)
# 當a=1即條件1;否則條件2
if self._leak is None:
# 條件1:a=1,ESN
previous_state = np.tanh(state_before_tanh).T
else:
# 條件2:a=[0, 1),Leaky ESN
# 這邊應該要寫x(t)=(1-a)*x(t-1) + a*x(t)
previous_state = (1.0 - self._leak)*previous_state + np.tanh(state_before_tanh).T
# 當超過沖洗時間,將過往狀態儲存x(t)在狀態矩陣X
if (t > n_drop - 1):
state_matrix[:, t - n_drop, :] = previous_state
return state_matrix
def get_states(self, X, n_drop=0, bidir=True):
# 取得數據列數N、時間步數T、特徵數V
# 若Win未建立,則建立Win
"""
Step 8. 根據數據的三個維度大小(N:列數或資料筆數;T:時間步數;V:行數或特徵數),建立輸入權重Win
- _input_weights = 輸入權重,size=[_n_internal_units, V]
- np.random.binomial(1, 0.5 , [self._n_internal_units, V]):RxV個0或1
- 2.0*np.random.binomial(1, 0.5 , [self._n_internal_units, V]) - 1.0:RxV個-1或1
- (2.0*np.random.binomial(1, 0.5 , [self._n_internal_units, V]) - 1.0)*self._input_scaling:RxV個-_input_scaling或_input_scaling
"""
N, T, V = X.shape
if self._input_weights is None:
self._input_weights = (2.0*np.random.binomial(1, 0.5 , [self._n_internal_units, V]) - 1.0)*self._input_scaling
"""
Step 9. 計算順向狀態矩陣X
- states/state_matrix = 狀態矩陣,size=[N, T-n_drop, _n_internal_units]
"""
states = self._compute_state_matrix(X, n_drop)
"""
Step 12. 如果雙向機制bidir啟動,將數據反向後再算一次狀態矩陣X,然後順向狀態矩陣X與反向狀態矩陣Xr合併
"""
if bidir is True:
# 數據沿著時間軸反向
X_r = X[:, ::-1, :]
# 計算反向狀態矩陣states_r
states_r = self._compute_state_matrix(X_r, n_drop)
# 順向狀態矩陣states與反向狀態矩陣states_r合併
states = np.concatenate((states, states_r), axis=2)
return states
def getReservoirEmbedding(self, X,pca, ridge_embedding, n_drop=5, bidir=True, test = False):
"""
Step 7. 取得初始狀態res_states
- 初始狀態矩陣res_states = 各時刻的狀態(除了前n_drop筆)
- 拋棄筆數n_drop = 前n筆不記錄在狀態矩陣states
"""
res_states = self.get_states(X, n_drop=5, bidir=True)
"""
Step 13. 為了降維,將初始狀態矩陣res_states從[N, T-n_drop, _n_internal_units]重塑為res_states[N*(T-n_drop), _n_internal_units]
資料筆數N_samples
"""
N_samples = res_states.shape[0]
res_states = res_states.reshape(-1, res_states.shape[2])
"""
Step 14. 根據當前模式,決定PCA是對res_states採學習或者轉換方式
經降維後的res_states
"""
# 若目前為測試模式,則pca僅執行轉換
if test:
red_states = pca.transform(res_states)
# 若目前為訓練模式,則pca執行學習
else:
red_states = pca.fit_transform(res_states)
# 重新將red_states從[N*(T-n_drop), _n_internal_units]=>[N, T-n_drop, _n_internal_units]
red_states = red_states.reshape(N_samples,-1,red_states.shape[1])
"""
Step 15. 透過Ridge回歸,進行編碼
編碼器input_repr
"""
coeff_tr = []
biases_tr = []
for i in range(X.shape[0]):
ridge_embedding.fit(red_states[i, 0:-1, :], red_states[i, 1:, :])
coeff_tr.append(ridge_embedding.coef_.ravel())
biases_tr.append(ridge_embedding.intercept_.ravel())
print(np.array(coeff_tr).shape,np.array(biases_tr).shape)
input_repr = np.concatenate((np.vstack(coeff_tr), np.vstack(biases_tr)), axis=1)
return input_repr
"""
讀取資料
"""
data = scipy.io.loadmat('dataset/JpVow.mat')
X = data['X']
Y = data['Y']
Xte = data['Xte']
Yte = data['Yte']
"""
對輸出作熱編碼
"""
onehot_encoder = OneHotEncoder(sparse=False, categories='auto')
Y = onehot_encoder.fit_transform(Y)
Yte = onehot_encoder.transform(Yte)
"""
建立降維器、編碼器,以及解碼器
"""
pca = PCA(n_components=75)
ridge_embedding = Ridge(alpha=10, fit_intercept=True)
readout = Ridge(alpha=5)
"""
ESN訓練
"""
res = Reservoir(n_internal_units=450, spectral_radius=0.6, leak=0.6,
connectivity=0.25, input_scaling=0.1, noise_level=0.01, circle=False)
"""
降維器訓練、編碼器訓練
"""
input_repr = res.getReservoirEmbedding(X, pca, ridge_embedding, n_drop=5, bidir=True, test = False)
"""
將測試資料餵入ESN,並且進行編碼
"""
input_repr_te = res.getReservoirEmbedding(Xte,pca, ridge_embedding, n_drop=5, bidir=True, test = True)
"""
Step 16. 解碼器訓練
"""
readout.fit(input_repr, Y)
"""
將測試資料餵入解碼器
"""
logits = readout.predict(input_repr_te)
"""
分類
"""
pred_class = np.argmax(logits, axis=1)
"""
結果可視化
"""
true_class = np.argmax(Yte, axis=1)
print(accuracy_score(true_class, pred_class))
print(f1_score(true_class, pred_class, average='weighted'))
以[6]維框架,加入了[7]的Wfb、noise、Win的定義方法後,其誤差可以降到9.58e-10
# -*- coding: utf-8 -*-
"""
原代碼, Mantas Lukoševičius(開山祖師Jaeger的學生), http://mantas.info
數據集可以到Lukoševičius那邊下載
"""
import matplotlib.pyplot as plt
import scipy
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, ElasticNetCV, Lasso, LassoCV
from sklearn.metrics import mean_squared_error
np.random.seed(42)
"""
Step 1. 讀取數據(MackeyGlass_t17),尺寸為(10000, 1)
"""
data = pd.read_table('MackeyGlass_t17.txt', header=None).to_numpy()
"""
Step 2. 定義訓練集長度len_train、測試集長度len_test、暫態長度len_transient、誤差計算長度len_error
"""
len_train = 2000
len_test = 2000
len_transient = min(int(len_train / 10), 100)
len_error = 500
"""
Step 3. 畫出數據前1000筆的曲線
"""
plt.figure('A sample of data').clear()
plt.plot(data[0:1000])
plt.title('A sample of data')
"""
Step 4. 定義ESN架構
輸入層神經元數Nu:
- 等於輸入資料的特徵數
輸出層神經元數Ny:
- 等於目標資料的特徵數
隱藏層神經元數Nx:
- 建議最少100顆,且每次增幅單位為50顆
- 沒看過超過1000的
洩漏率a:
- 加強短期記憶能力,範圍在[0, 1]
- 若a=1則ESN;a<1則Leaky ESN(P7)
輸入層的縮放因子input_scaling
- 範圍在[0, 1]
稀疏程度sparsity:
- 建議在0.01(1%)~0.05(5%),也有人建議0.05(5%)~0.2(20%)
指定譜半徑rho:
- 範圍在[0, 1)
使用偏權值use_bias
使用輸出層回饋權重(Wfb)use_fb
"""
Nu = 1
Ny = 1
Nx = 500
a = 0.3
input_scaling = 0.01
sparsity = 0.05
rho = 0.99
use_bias = True
use_fb = True
noise_level = 0.00
"""
Step 5. 初始化輸入層權重Win、隱藏層權重W
輸入層權重Win:
- 如果有偏權值,則尺寸為(隱藏層神經元數, 1+輸入層神經元數)
- 否則(隱藏層神經元數, 輸入層神經元數)
- 常見範圍在[-1, 1]或者[-0.5, 0.5]
- 建議用常態分布
輸出層回饋權重Wfb:
- 尺寸為(輸出層神經元數, 1)
- 常見範圍在[-1, 1]或者[-0.5, 0.5]
- 建議用常態分布
初始隱藏層權重W_0:
- 尺寸為(隱藏層神經元數, 隱藏層神經元數)
- 常見的初始範圍在[-1, 1]或者[-0.5, 0.5]
- 這邊提供另一種寫法,借鑑於Madalina Ciortan,這個方法才真正達到稀疏效果
- W_0 = scipy.sparse.rand(resSize, resSize, density=sparsity).todense() - 0.5
- scipy.sparse.rand(列數, 行數, density=稀疏程度).todense()
- 假設density=0.1(10%)、列數=10、行數=10,則10x10的矩陣中只有總計10個元素不為零,而且是不規則零散分布在矩陣中
初始隱藏層權重的譜半徑rhoW:
- max( abs( W_0 ))
- rhoW<1,隱藏層才具有ECHO特性
隱藏層權重W:
- W = W_0 * rho/rhoW
"""
if use_bias==True:
# Win = (np.random.rand(Nx, 1+Nu)-0.5) * input_scaling
Win = (2.0*np.random.binomial(1, 0.5 , [Nx, 1+Nu]) - 1.0) * input_scaling
else:
# Win = (np.random.rand(Nx, Nu)-0.5) * input_scaling
Win = (2.0*np.random.binomial(1, 0.5 , [Nx, Nu]) - 1.0) * input_scaling
if use_fb==True:
# Wfb = np.random.rand(Nx,Ny)-0.5
Wfb = (2.0*np.random.binomial(1, 0.5 , [Nx, Ny]) - 1.0)
else:
Wfb = np.zeros([Nx,Ny])
# W_0 = np.random.rand(Nx,Nx)-0.5
W_0 = scipy.sparse.rand(Nx, Nx, density=sparsity).todense()
W_0[np.where(W_0 > 0)] = W_0[np.where(W_0 > 0)] - 0.5
rhoW = np.max(np.abs(np.linalg.eig(W_0)[0]))
W = W_0 * rho/rhoW
"""
Step 5. 收集:取得每一時刻的狀態x(t),然後存在所有時刻的狀態X中
- t=0時,x(0)為一個尺寸(隱藏層神經元數,1)的零矩陣,y(0)為一個尺寸(輸出層神經元數,1)的零矩陣
- 無偏權值、無回饋:x(t) = (1-a)*x(t-1) + a*tanh( Win* u(t) + W*x(t-1) + 0 );X尺寸=(筆數, 輸入層神經元數+隱藏層神經元數 )
- 無偏權值、有回饋:x(t) = (1-a)*x(t-1) + a*tanh( Win* u(t) + W*x(t-1) + Wfb*y(t-1) );X尺寸=(筆數, 輸入層神經元數+隱藏層神經元數+輸出層神經元數)
- 有偏權值、無回饋:x(t) = (1-a)*x(t-1) + a*tanh( Win*[1;u(t)] + W*x(t-1) + 0 );X尺寸=(筆數, 1+輸入層神經元數+隱藏層神經元數 )
- 有偏權值、有回饋:x(t) = (1-a)*x(t-1) + a*tanh( Win*[1;u(t)] + W*x(t-1) + Wfb*y(t-1) );X尺寸=(筆數, 1+輸入層神經元數+隱藏層神經元數+輸出層神經元數)
- X應為一個尺寸(隱藏層神經元數,筆數)
- 在訓練Wout前記得要刪掉X的前len_transient筆
"""
X = []
x = np.zeros([Nx, 1])
y = np.zeros([Ny, 1])
for t in range(len_train):
u = data[t:t+1]
if use_bias==True:
x = (1-a)*x + a*np.tanh( np.dot(Win, np.vstack([1, u])) + np.dot(W, x) + np.dot(Wfb, y) + np.random.rand(Nx, 1)*noise_level)
else:
x = (1-a)*x + a*np.tanh( np.dot(Win, u) + np.dot(W, x) + np.dot(Wfb, y) + np.random.rand([Nx, 1])*noise_level)
if use_bias==False and use_fb==False:
X.append(np.vstack([u, x]))
elif use_bias==False and use_fb==True:
X.append(np.vstack([u, x, y]))
elif use_bias==True and use_fb==False:
X.append(np.vstack([1, u, x]))
elif use_bias==True and use_fb==True:
X.append(np.vstack([1, u, x, y]))
y = data[t:t+1]
X = X[len_transient:]
X = np.array(X).reshape(len_train-len_transient, -1)
"""
Step 6. 訓練:利用所有時刻的狀態X、所有時刻的目標Yt,以Ridge回歸求得輸出層權重Wout
- 輸出層權重的尺寸為(輸出層神經元數, 1+輸入層神經元數+隱藏層神經元數)
- 借鑑Madalina Ciortan,我直接用Ridge取代了Wout
- L1正則的回歸器效果都不太好(Lasso、ElasticNet),我猜是因為很多權重被刪掉的關係
- 無偏權值、無回饋:Wout尺寸=(輸出層神經元數, 輸入層神經元數+隱藏層神經元數 )
- 無偏權值、有回饋:Wout尺寸=(輸出層神經元數, 輸入層神經元數+隱藏層神經元數+輸出層神經元數)
- 有偏權值、無回饋:Wout尺寸=(輸出層神經元數, 1+輸入層神經元數+隱藏層神經元數 )
- 有偏權值、有回饋:Wout尺寸=(輸出層神經元數, 1+輸入層神經元數+隱藏層神經元數+輸出層神經元數)
"""
y_train = data[len_transient+1:len_train+1]
ridge = Ridge(alpha=1e-8)
ridge.fit(X, y_train)
"""
Step 7. 測試
- 第一筆測試輸入u(t-1)=data[2000]
- 第一筆狀態x(t-1)延續於Step 5
- Y是用來記錄模型在測試階段各時刻的輸出
- 作者提供兩種模型輸出:遞迴式多步預測和單步預測,選一個用就可以了
- 無偏權值、無回饋:y(t) = Wout*[ u(t);x(t)]
- 無偏權值、有回饋:y(t) = Wout*[ u(t);x(t);y(t-1)]
- 有偏權值、無回饋:y(t) = Wout*[1;u(t);x(t)]
- 有偏權值、有回饋:y(t) = Wout*[1;u(t);x(t);y(t-1)]
"""
y_pred = []
u = data[len_train:len_train+1]
for t in range(len_test):
if use_bias==True:
x = (1-a)*x + a*np.tanh( np.dot(Win, np.vstack([1, u])) + np.dot(W, x) + np.dot(Wfb, y) + np.random.rand(Nx, 1)*noise_level)
else:
x = (1-a)*x + a*np.tanh( np.dot(Win, u) + np.dot(W, x) + np.dot(Wfb, y) + np.random.rand(Nx, 1)*noise_level)
# print(t)
# if t==504:
# print()
if use_bias==False and use_fb==False:
y = ridge.predict(np.vstack([u, x]).T)
elif use_bias==False and use_fb==True:
y = ridge.predict(np.vstack([u, x, y]).T)
elif use_bias==True and use_fb==False:
y = ridge.predict(np.vstack([1, u, x]).T)
elif use_bias==True and use_fb==True:
y = ridge.predict(np.vstack([1, u, x, y]).T)
y_pred.append(y)
# 遞迴式多步預測,也就是當前時刻的模型輸出會作為下一刻模型的輸入
# u = y
# 單步預測,當前時刻的輸入數據是從實際量測或者離線數據中取得
u = data[len_train+t+1:len_train+t+2]
y = data[len_train+t:len_train+t+1]
y_pred = np.array(y_pred)
y_pred = y_pred.reshape(-1, Ny)
"""
Step 8. 採MSE計算測試集中前len_error筆誤差
- 為什麼只計算len_error筆誤差,因為Mantas當初是採遞迴式多步預測作為輸出方式
- 遞迴式多步預測(Recursive Multi-Step Forecasting)的問題在於預測能力會隨著時間而衰弱,從本代碼的執行結果中也顯而易見
- 所以我猜這就是他只取500筆作計算的原因
"""
mse = mean_squared_error(data[len_train+1:len_train+1+len_error], y_pred[:len_error])
print('MSE = ' + str( mse ))
"""
畫出測試集輸入訊號
"""
plt.figure('Target and generated signals').clear()
plt.plot(data[len_train+1:len_train+1+len_test], 'g')
plt.plot( y_pred, 'b' )
plt.title('Target and generated signals $y(n)$ starting at $n=0$')
plt.legend(['Target signal', 'Free-running predicted signal'])
"""
畫出20條權重在t=100~300的狀態響應X
"""
plt.figure('Some reservoir activations').clear()
plt.plot( X[0:200, 0:20] )# 看起來是t=0~200,但加上沖洗時間initLen=100後應為t=100~300
plt.title('Some reservoir activations $\mathbf{x}(n)$')
"""
畫出輸出權重的值
"""
plt.figure('Output weights').clear()
if use_bias==False and use_fb==False:
plt.bar( range(Nu+Nx), ridge.coef_.ravel() )
elif use_bias==False and use_fb==True:
plt.bar( range(Nu+Nx+Ny), ridge.coef_.ravel() )
elif use_bias==True and use_fb==False:
plt.bar( range(1+Nu+Nx), ridge.coef_.ravel() )
elif use_bias==True and use_fb==True:
plt.bar( range(1+Nu+Nx+Ny), ridge.coef_.ravel() )
plt.title('Output weights $\mathbf{W}^{out}$')
plt.show()
[1]An Introduction to the Echo State Network and its Applications in Power System:入門級期刊(含應用),若不認識ESN的話這篇一定要先看
[2]Adaptive Nonlinear System Identification with Echo State Networks:開山祖師Jaeger寫的,也是入門級期刊,若不認識ESN的話這篇一定要先看
[3]A Practical Guide to Applying Echo State Networks:Lukoševičius(開山祖師Jaeger的碩+博學生)寫的,重點觀念在P2~P3
[4]Predictive Modeling with Echo State Networks:這篇加了Wfb,以及各參數的實驗結果,2.1節是重點
[5]Echo State Networks for Adaptive Filtering:重點觀念在P18的Algorithm 1,終於明白Lukoševičius原代碼的1.25是什麼了
[6]Simple Echo State Network implementations:Lukoševičius提供簡易代碼,與[2]相呼應
[7]Gentle introduction to Echo State Networks:Ciortan(Medium網友)的代碼,該代碼源頭可追朔到[8]
[8]Reservoir computing approaches for representation and classification of multivariate time series:作時間序列辨識的,加入雙向機制、降維和編解碼器
[9]An Introduction to:Reservoir Computing and Echo State Networks:入門級投影片
 a26833765
a26833765
