在前四篇文章,大概介紹了如何畫圖以及一些變數的調整,而內部的細節這邊不在做深度的討論。接著這篇文章開始要介紹另一個package dplyr ,這個套件主要用途是用來調整你的資料,包括缺失值的處理等等。而 dplyr 一樣在 tidyverse 的內部,以及我們將使用一些來自 package nycflights13 裡面的資料。
library(nycflights13)
library(tidyverse)
這次我們會使用 nycflights13 裡面的 flights 這筆資料。
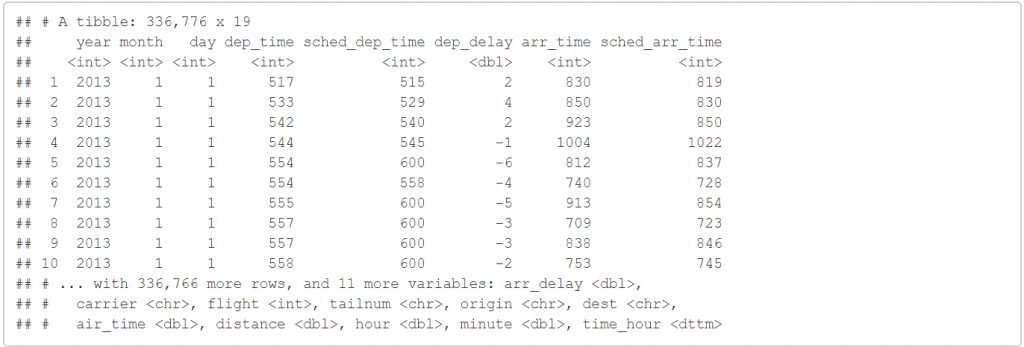
glimpse(flights)

我們可以看到它是 336776x19 的表格資料,也就是說它有19個變數,而在每個變數後面會有一些英文縮寫,這是代表的該欄位的資料類型,比較常見的資料型態有:
而接下來幾篇文章會為大家介紹在 dplyr 裡面幾個常用的函數。
首先會看到 filter() ,它的功能跟 subset 相似,可以擷取你想要的資料的小區塊,以底下例子來說明。
flights 是航班資料,如果今日我只想要看 1/1 的資料,我們可以試試看以下語法。
filter(flights,month==1,day==1)
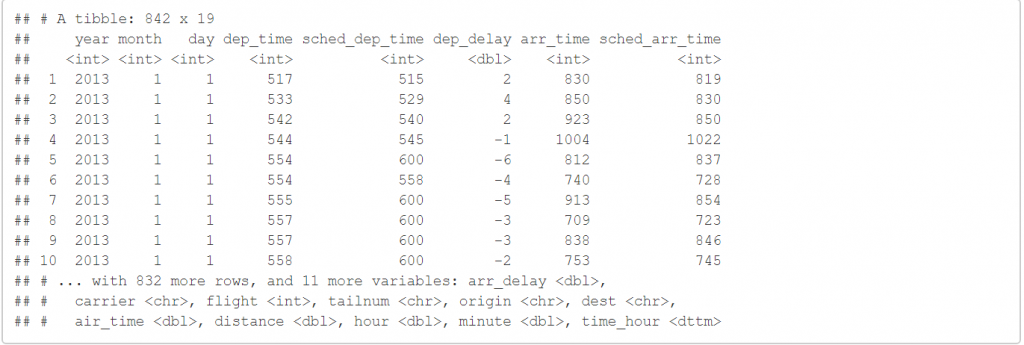
我們可以看到,33萬多筆的資料中,有842筆 1/1 的資料。而 filter 的第一個參數是data,後面的參數就是你想要限制的條件,我們甚至可以試試一些真假值條件, & ! | 依序代表的是 且 否定 或。例子如下
filter(flights,month==11|month==12)
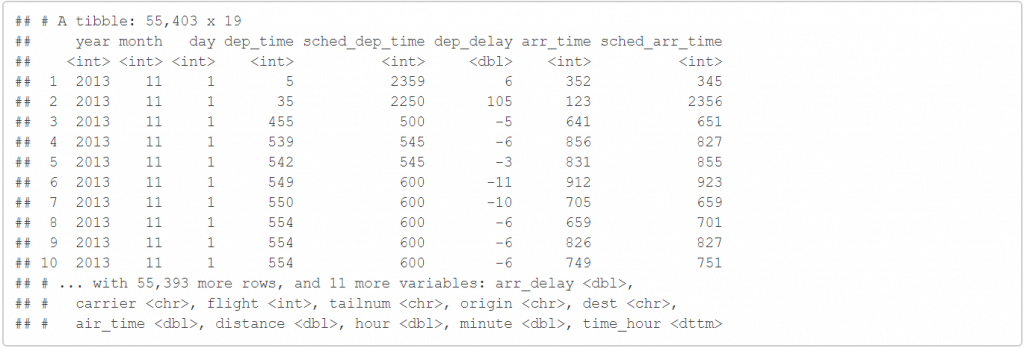
我們就可以去擷取所有十一月跟十二月的資料,在使用 且 的時候,我們也用逗號作為代替。
接下來我們來看下一個函數 arrange ,顧名思義就是重排,使用方法與 filter 類似,如果我們輸入以下程式碼:
arrange(flights,year,month,day)
它的意思是從flights這筆資料,由year,month,day這些變數由小到大重新排列,但是因為我們這筆資料本身就是這樣的排列了。那我們可以試試下面這個與法。
arrange(flights,desc(arr_delay))
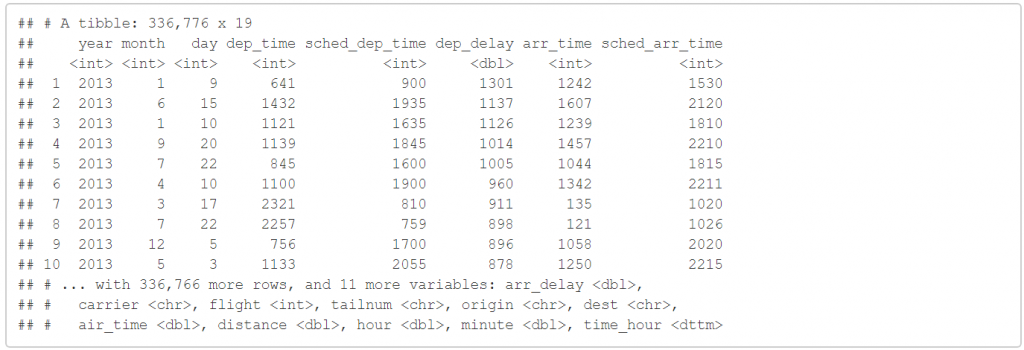
它就會將資料由 arr_delay 從大到小的重排,而缺失值總是會排在資料的最後端。
所謂 缺失值 就是資料中缺失的資料,通常缺失資料會顯示 NA ,在R語言中,缺失資料通常很難處理,因為它不同於前面所說的資料形態。
而且我們看到
NA==NA

這是相當弔詭的事情,我們也可以透過 class 這個函數去查看它的資料形態。
像是
class(pi)

是數值資料。
class(TRUE)

是邏輯資料。
那 NA 到底是何種資料呢?
class(NA)

這邊看到它是邏輯資料,但是如果我們拿NA去跟數值做一些運算,會發現一些有趣的事情。
NA+5

NA>5

上面兩個結果雖然都是NA,但是如果用資料形態去看它。
class(NA+5)

class(NA>5)

卻是不同的結果,很弔詭吧?而事實上缺失值的處理一直是資料分析中的一門學問,在這邊我們先用一個簡單的語法來判斷資料是否為缺失值:
is.na(NA)

is.na(NA>6)

若為缺失值,則會顯示TRUE,不是則FALSE。
下一篇文章會繼續針對 dplyr 的其他函數做討論,這篇文章就先介紹到這,謝謝大家。
 df568923
df568923

 iThome鐵人賽
iThome鐵人賽