如何選擇適當的Primary Key?這對使用Scylla或者是其他非關聯性資料庫的人,都是一個不容易的課題。
與關聯性資料庫不同的地方,Scylla再設計一張table的時候,應該要先從會使用的查詢語法下手。
在一開始接觸的時候,的確是很難跳出原本的觀念來設計,我們用例子來解釋為何要這樣設計。
今天如果需要統計枕頭山上A觀測站每天觀察到的平均氣溫,每半小時紀錄一次。
我們依據需求建立了PilloHillT這個表格,包括了觀測站代碼id,觀測站名稱name,日期date,紀錄時間time四個欄位,然後我們使用id當作partition key,而time當成cluster key。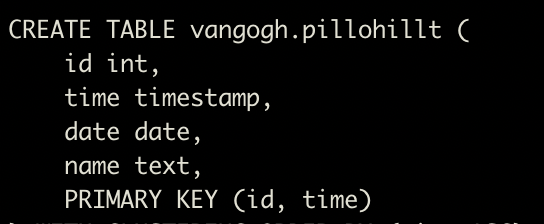
以這樣設計的方式,在id=1這個partition裡頭,一天會有48筆紀錄,一年兩年過去,這個partition最後會儲存大量的數據。產生了large_partition。
雖然我們依然可以使用time當成時間區間條件去過濾我們要的資料,但是會面臨越來越多的資料筆數,以及越來越差的查詢效能。
接著我們用另一個方式來設計這張表,這次我們用id與date當成parititon key。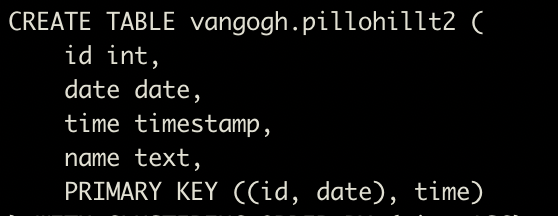
這樣的設計下,我們一樣可以用time去過濾條件,但是因為partition key是由id與date組成,所以只要過濾一天的資料。
Scylla會把產生large_partition的情況紀錄在system.large_partitions裡頭,做好初期的規劃,避免large_partition的產生,可以降低資料庫上線之後,監控圖上的latency突然一個衝高導致偏頭痛的頻率。


 iThome鐵人賽
iThome鐵人賽