前三章介紹了三種Beats,為什需要這些工具從不同方向監控呢?
Elastic的Tanya Bragin的文章Product Lead for Observability 中介紹如何運用這些工具達到所謂的可視性(Observability)
參考:Observability with the Elastic Stack
https://www.elastic.co/blog/observability-with-the-elastic-stack
文章提到建立Observability的兩個好處:
其一: 構建“Observability”系統的目標是確保在生產中運行時,負責該系統的維運人員(operators)可以檢測到不良行為(例如,服務停機,錯誤,回應緩慢),並掌握可操作的信息以查明根本原因以有效的方式
其二: 可以更有效的設置SLA,因為看的面向更廣、,避免忽略的及漏掉的資訊;再來利用同一個平台統整Logs、Metrics、Traces 更符合成本效益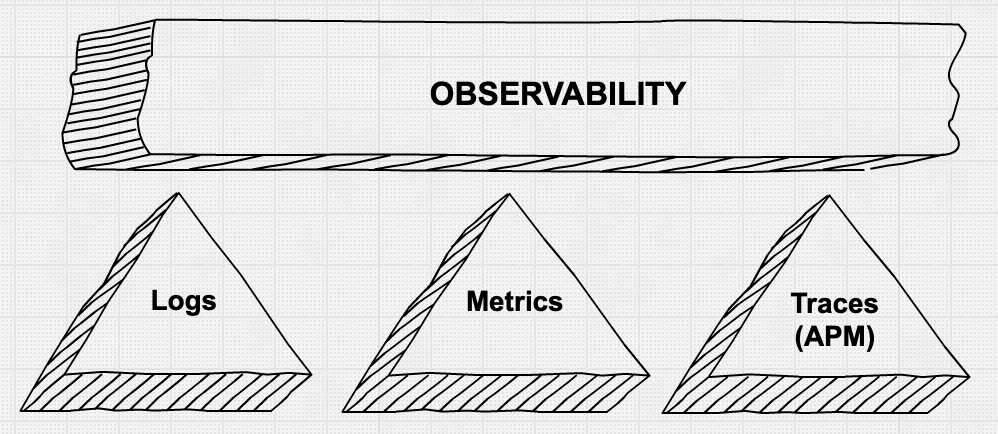
而當架構更大的時候一連串的問題併發,成千上萬條告警同時,沒有一個統整系統,做關聯關係和儀表板,查問題就像是大海撈針
looking at metrics in one browser window, manually correlating it to logs in another window, and pulling up traces (if relevant) in yet a third window
以下5分鐘的短片Demo 追蹤問題的流程,可以藉由這部短片思考一下該在那些地方加什麼監控,以及除錯的流程方式。
同上影片CSDM說明 https://blog.csdn.net/u013613428/article/details/103366974


 iThome鐵人賽
iThome鐵人賽