Scylla提供了監控的模板,是由Prometheus搭配Grafana來呈現。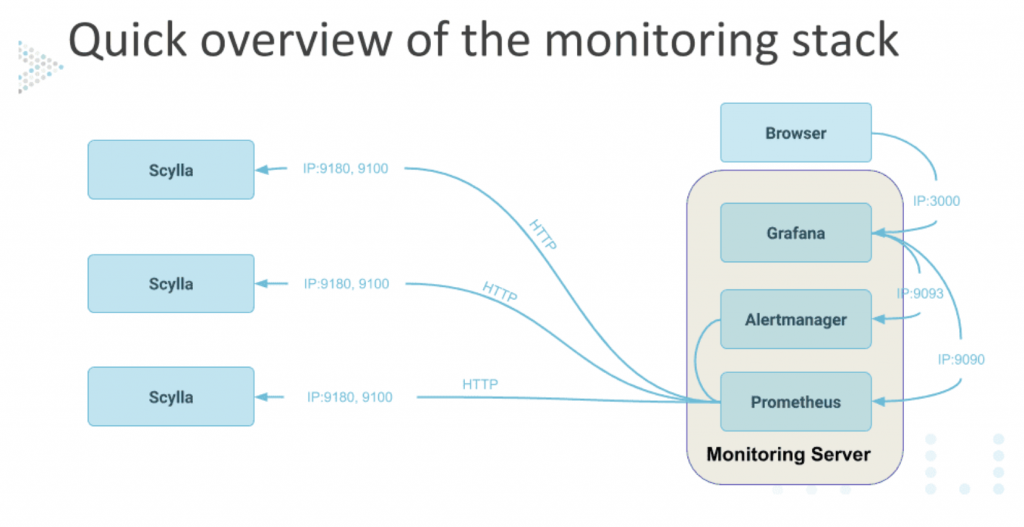
目前最新的版本是3.4,官方建議使用的機器規格為CPU至少2 physical cores,15GB以上的記憶體,預設資料保留天數為15天,所需的硬碟空間可用監控的node數量乘上每個node的CPU核心數乘上200MB,舉例來說一個包含3個node的cluster,每個node是4core,則預估的硬碟大小為
3 * 4 *200MB = 2.4GB。
官方提供docker安裝,下載安裝完,把要監控的node ip填入scylla_servers.yml,一套熱騰騰的監控就好了。詳細安裝設定請參閱官方文件。
https://github.com/scylladb/scylla-monitoring
從Grafana呈現的畫面如下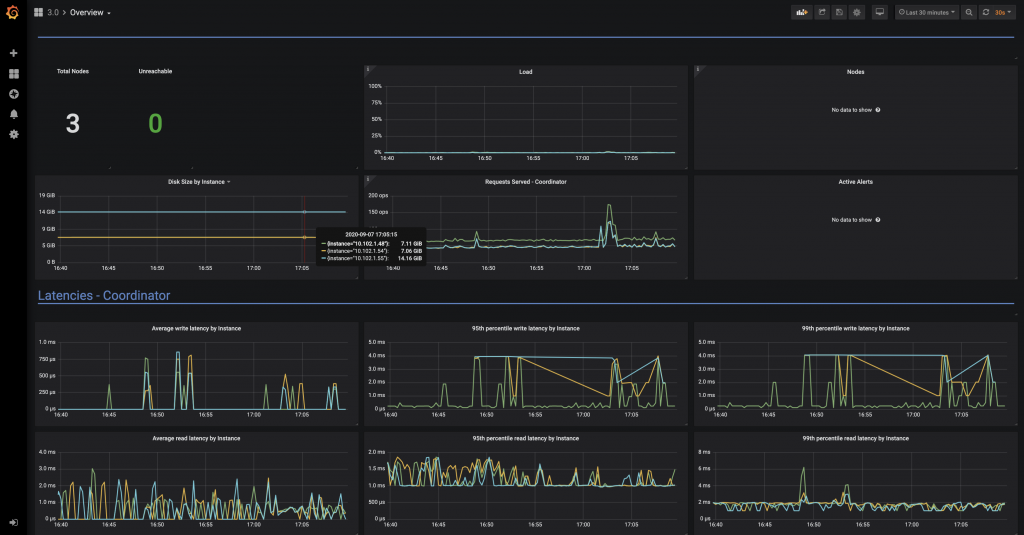
Overview:
在這個Metrics裡,可以看到目前Node的數量有3個,0個node斷線。以及每個node磁碟的使用量,cpu的loading,還有平均每台coordinator的latency等數值。
Scylla Manager Metrics:
這個Metrics會紀錄我們透過Scylla Manager使用sctool執行repair,透過監控圖來觀察執行的情形。如圖中目前正在執行1個repair動作,進度為0.7%。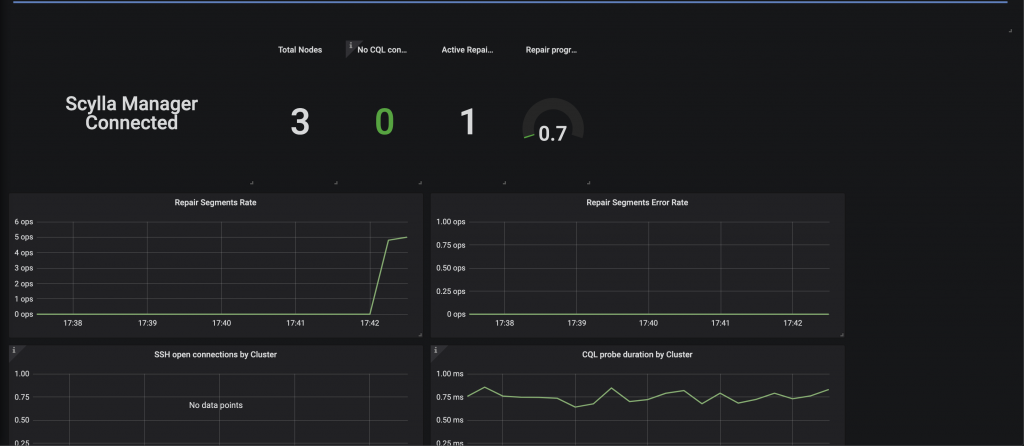


 iThome鐵人賽
iThome鐵人賽