負責執行一次性任務, 執行完畢會把Pod狀態設定為Completed, 如果過程發生錯誤會依照重啟策略進行下一步驟。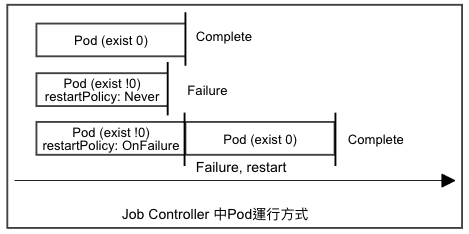
運行的情境有三種:
只執行一次,Pod做完就收工, 每個Pod正常終止後, Job狀態會轉為Completed。
需要確定Pod運作達到預期數量時:
設定工作數量: spec.parallellism(預設1), 設定預期數量: spec.comlpetions(預設1),當成功執行完的Pod數量達到spec.comlpetions, 這個Job狀態會轉為Completed。
work queue 併行Job:
不設定spec.completions, 預設spec.completions 等於 spec.parallelism, 一個Pod成功完成時, 其他的Pod也會停下來, 所有的Pod都會一起退出程序。
Job Controller spec 必填字段只有template, 使用方式和Deployment一樣。Job會幫其Pod對象新增標籤job-name=JOB_NAME和controller-uid=UID, 並使用labelSelector完成controller-uid=UID的關聯,Job 位於API群組的batch/V1中。
另外, spec.restartPolicy 預設為 Always, 這並不適用Job, 需要另外設定為OnFailure or Never。
創建YAML範例
-> % cat job-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
spec:
containers:
- name: job-hello
image: nginx:latest
args:
- /bin/sh
- -c
- echo test
restartPolicy: Never
查看job運行結果
-> % kubectl get jobs job-demo
NAME COMPLETIONS DURATION AGE
job-demo 0/1 3m40s 3m40s
查看Job Pod
-> % kubectl get pods -L app
NAME READY STATUS RESTARTS AGE APP
job-demo-ljzfc 1/1 Running 0 5m21s
刪除Pod
Pod的狀態設為Completed之後就不再佔用資源, 用戶可以依照使用需求刪除或保留; 如果遇到設定 restartPolicy: OnFailure 且一直發生錯誤導致無法將狀態Completed或是其他無法正常終止的狀況, Pod可能會一直不停的循環重啟, 針對這樣的狀況, Job 提供兩個屬性可以避免佔用資源:
spec.activeDeadlineSeconds <integer>: 指定最長活動時間, 時間到就會將它終止spec.backoffLimit <integer>: 用來標記失敗狀態之前的重試次數, 預設為6, 達到允許重試次數就會被終止spec:
backoffLimit: 5
activeDeadlineSeconds: 100
上面的設定表示如果Job失敗重啟超過5次或是執行超過100秒仍未完成, 那Job就會被系統終止。
負責定時或週期性的執行任務, 用在管理Jobs的運行時間。CronJob類似Linux的crontab支援預約未來執行任務時間或是固定在某個週期重複執行任務。
CronJob spec支援以下字段:
必填, 用來產生job的模板必填, 設定運行時間Allow,Forbid,ReplaceAllow: 預設, 允許CronJob底下多個Job同時執行Forbid: 禁止兩個Job同時執行, 前一個未執行完會跳過下一個Replace: 禁止兩個Job同時執行, 前一個未執行完會終止前一個,啟動下一個來取代1
3
false
-> % cat job-demo-multi.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-demo
labels:
app: cronjob-test
spec:
schedule: "*/2 * * * *"
jobTemplate:
metadata:
labels:
app: cronjob-jobs-lbi
spec:
parallelism: 2
template:
spec:
containers:
- name: job-multi-test
image: apline
args:
- /bin/sh
- -c
- echo test
restartPolicy: OnFailure
-> % kubectl get cronjobs
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-demo */2 * * * * False 0 <none> 8s
ACTIVE: 活動狀態的Job數量SCHEDULE: 調度時間點SUSPEND: 後續任務是否暫停LAST SCHEDULE: 上次調度的時間長度Job 可以應用在升級後的服務檢測, 或是特定項目異動後檢查。
例如: 我們有使用lua編寫會隨著需求增加的邏輯檔案, 只有在超出現有邏輯的狀況才需要新增lua檔案, 新增頻率不高, 通常只需要在新增後跑一遍全部測試就好, 此時就可以運用Job手動觸發測試程式檢查。
CronJob 適合用在服務定期重啟或定時檢測。
例如: 在每週的固定維護更新後執行預想的User Story路徑檢查。
K8s可以透過PodDisruptionBudget來限制可自願中斷的最高Pod數以及確保最少可用的Pod數, 藉此來維持服務高可用性。自願中斷像是人為刪除或是更新image造成的Pod重建, Deployment雖然可以確保Pod數量接近期望值, 但是無法保證在特定時段一定會存在指定數量或比例的Pod對象, 此時可以透過PodDisruptionBudget來解決。PodDisruptionBudget支援Deployment, ReplicaSet, StatefulSet...等, 主要用來保護LabelSelector關聯到的Pod對象可以精確的存活一定的比例。
PodDisruptionBudget spec 可以使用三個字段:
100%
0
miniAvailable 和 maxUnavailable 互斥, 一是只能選一個設定。
YAML配置
-> % cat pdb-demo.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: pdb-example
spec:
minAvailable: 2
selector:
matchLabels:
app: deploy-demo
查看結果
-> % kubectl get pdb
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
pdb-example 2 N/A 0 5s
到今天大致上把Pod Controller 都走過一遍了, 應用時可以先釐清需求的情境, 依照不同的情境來選用不同的 Controller來實作, 接下來要前進到Service的部分了!

