今天我要要開始寫一些再複雜一點的指令。首先我們來說說什麼是 Aggregation (聚合). Aggregation Pipeline 指的是把查詢拆成步驟,想水流一樣,層層處理。讓我們先看一個例子。
db.grades.aggregate(
[{$match: {student_id: {$lte:5}}},
{$match: {class_id: {"$gte":400}}}]
)
Aggregate 這個函數帶的是一個陣列 (array) ,這個列表順序表示他針對這筆資料逐步做的處理。在這邊我們地一次將grades這裡的資料針對student_id 小於等於五的先過濾選出來,第二步再去對應出課程編號大於400的課。這個範例我刻意把一個很簡單的find 改寫成aggregate,但隨著你知道mongoDB 有哪一些好用的函式,就會知道aggreagte 強大的地方。在這裡我強烈推薦使用 Mongo Compass 的GUI 可以讓第一次寫aggregation的讀者快速上手並寫出非常複雜的指令。
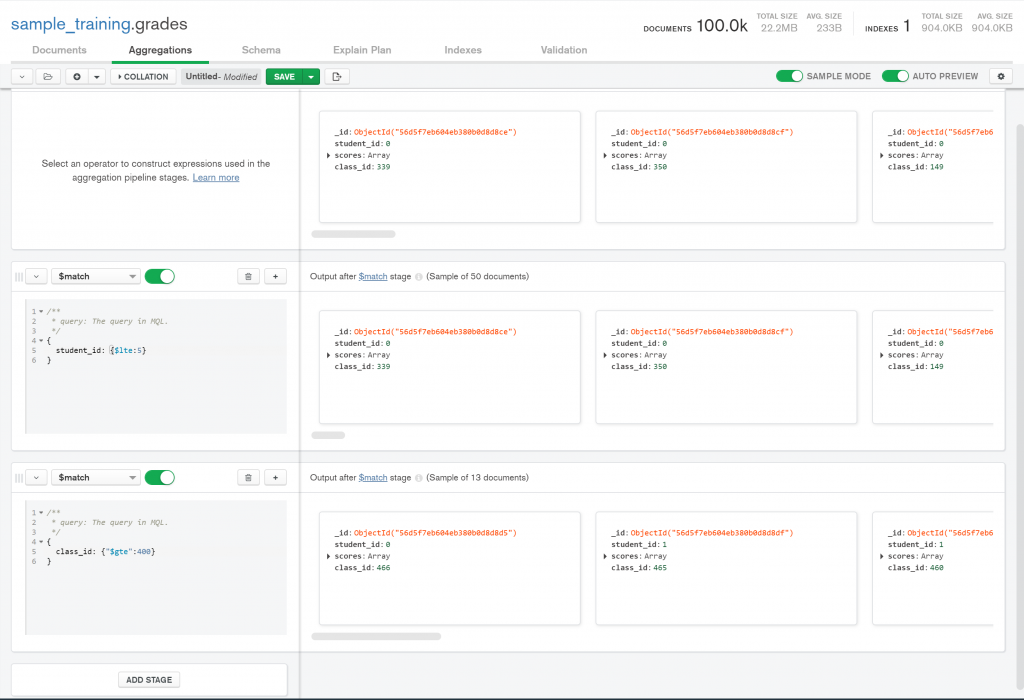
在原本選擇在documents 的隔壁點選Aggregation. 這相當於在編輯每一段陣列以面的查詢。第一列市所有資料集合中的資料,下面我先做了一個 match ,這時候就會顯示出預覽符合這個條件的資料,然後在往下就是第二次過濾。完成後我們就可以點選中間綠色 Save 按鈕右邊的白色按鈕,看到整個查詢的指令。基本上就跟上面寫的一樣囉!
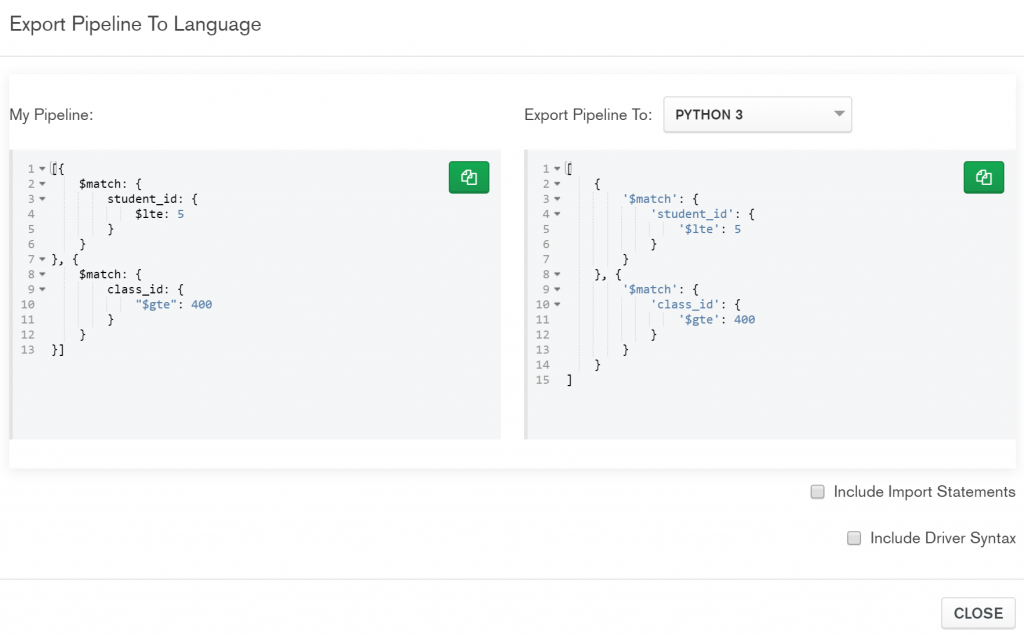
先來介紹什麼事 unwind. 你可以把她想成是分裝。讓我們看下面這個虛擬的例子:
{ studnet_id: 1, friends: [2, 5, 7] }
如果針對這個document 進行friends unwind,就會變成:
{ { studnet_id: 1, friends: 2 },
{ studnet_id: 1, friends: 5 },
{ studnet_id: 1, friends: 7 } }
這個函式把相同的部分留下來,把指定的列表拆開成獨立的Document. 這有什麼好處呢? 讓我們看下面這個例子。回到原本的範例資料,看一下這個頗複雜的查詢指令:
db.grades.aggregate([
{$unwind: {path: "$scores"}},
{$project: {
student_id:1,
class_id:1,
type:"$scores.type",
scores:"$scores.score"}},
{$match: {type:"homework"}},
{$group: {
_id: "$class_id",
assignment_score: {$avg: "$scores"},
scores: {$addToSet: "$scores"}}},
{$project: {
_id: 0,
class_id: "$_id",
assignment_score: {$round: ["$assignment_score", 2]},
scores: 1}},
{$sort: {class_id: 1}}])
假設我們現在想要得到每一堂課的學生作業的平均成績,和成績清單。
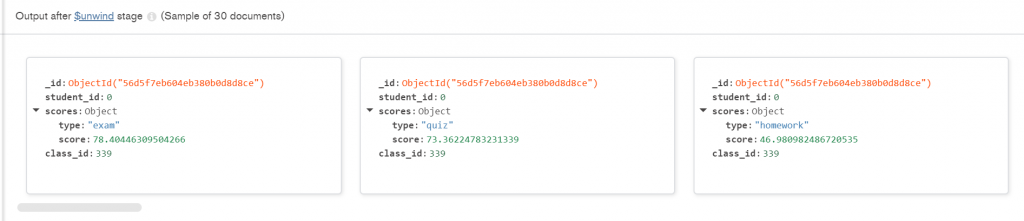
第一步 — unwind: 接續上面的解釋第一步我先將原本分數的陣列拆解。每一個人的成績都放在一個陣列當中,有考試有作業的成績,拆解過後就可以確定每個文檔裡面只有一個屬於某項評分的分數。
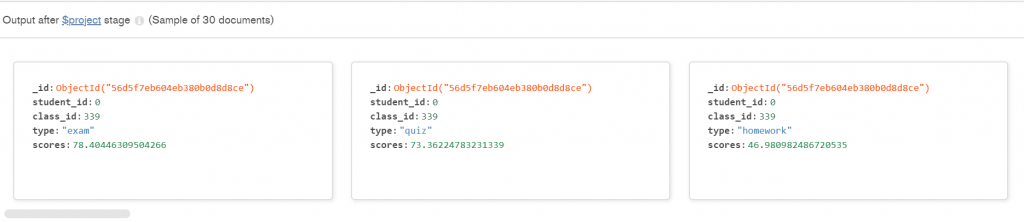
第二步 — project: 因為拆解過後,拆解的東西會藏在scores底下,讓我們用project重新改變他的表現方式,簡單來說可以把他想成 SQL中的 Select 可以重新命名的功能。
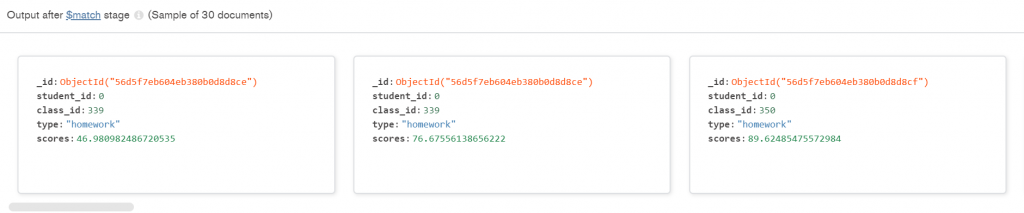
第四部 — group: 這個是這個查詢最重要的核心,這個函式受先要先定義用什麼來框組,這裡選擇的是用 course_id 來分組。分組過後我們針對同組的資料做兩件事情,首先我們先取得這組資料的平均數值,第二件事情是把裡面的成績 $push 推入一個空白的陣列。這樣就可以義路所有出現的成績了! 這裡的 $push 是bag operation (不會重複出現!) 若是希望數值只有唯一(例如說想要找的是沒有重複出現的班級編號,就會使用 $addToSet 。
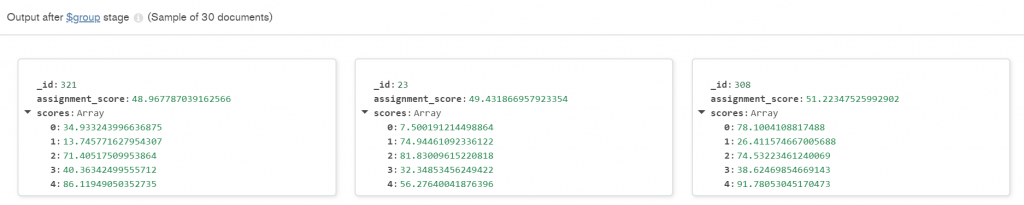
第五步 — project: 最後我們來調整呈現的資要樣態,首先把 _id 改名,並讓成績四捨五入到小數點下第二位,最後顯示成績陣列。
第六步 — sort: 然後再加上排序。
其實複雜的Mongo Aggregation Pipeline 就是把複雜的問題拆成片段,把手算的過程獨立的分開,再把它寫成小的函式,逐一去運行。相較於以前只有命令提式字元可以寫MongoDB的指令,現在讀者可以透過 Compass 可視化中間的步驟結果,慢慢成為 MongoDB 大師。


 iThome鐵人賽
iThome鐵人賽