接下來的三天,我們要解答,究竟資料庫的資料進在哪裡,為什麼可以快速的存取呢? 在回答這個問題之前,我們我們要先來回過頭來看一下,電腦裡面的資料,是怎麼儲存的。
電腦儲存資料,我們大致分成三個階層 — 磁碟 (Disk)、主記憶體 (Memory) 和 快取 (Cache)。磁碟,就是我們平常熟知的硬碟、記憶卡、SSD,都是磁碟記憶體。這種記憶體容量大,但是相對的儲存所需要花的時間就比較長。記憶體,也就是我們熟知的 RAM,他的讀取速度比磁碟記憶體快上不少,但他的容量比較小。最後是快取記憶體,一般來說快取記憶體都放置在處理器裡面,負責協助處理器存放短期所需要的暫存資料。快取記憶體是三者中讀寫速度最快,但容量也是最小的。
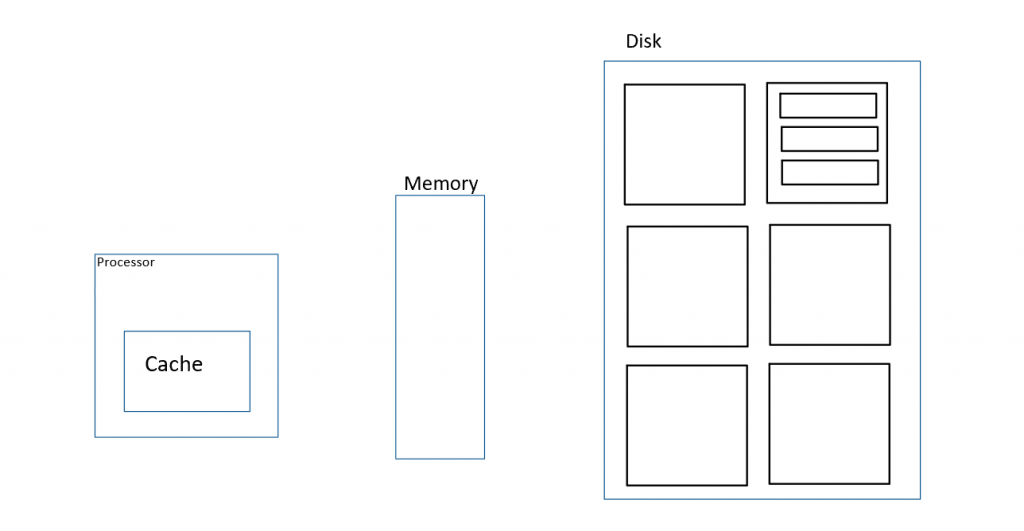
為什麼這個觀念很重要? 我們都知道資料庫的資料非常的多,大部分的時候我們得把資料庫的資料放在磁碟記憶體之中,但是我做運算的時候還是需要在處理器中做運算,這時候既然我們無法把所有資料庫的東西一次都塞在快取或是記憶體當中,我們需要一些方法讓這些資料扔然可以在快取中運行。
所以平常處理器(ie. CPU) 在運算的時候,舉例來說,他會把它需要的東西從磁碟記憶體拿來放在記憶體中,把她正在算的中繼結果放在快取中,最後把檔案寫回到磁碟記憶體。
接下來我們看看磁碟是怎麼存放這些資料的。在上面的圖示中,磁碟裡面有一快快的方格,我們稱之為 Memory Block (記憶塊) 每個記憶塊中有 Record。這樣講有點抽象,我們直接來舉例。想像一個很大的圖書館,有很多書櫃,每個書會有很多架子。這時候你有一套百科全書想要放到圖書館中,這時候你就會把一本一本的書放到架子上,一排滿了放下一排,一個書櫃滿了放到下一個書櫃,一直放到放完為止。沒錯,電腦的記憶體也是這樣,每個書架我們就稱之為 Block,架上每一行就是 Record。
這時候問題來了: 在這麼大的一個讀書館當中,如果我想要找一本書,我要怎麼找呢?
最直覺的方法就是一本一本找,從第一個書櫃的第一列開始翻閱,一直翻到找到為止。(你可定會笑我太慢了!)
沒錯,所以我們需要更聰明的方法 — 索引 (index)。
索引,或是目錄就是用比較少的資訊,去對應出原本的資訊。就像一本書的索引,你可以翻閱他找到關鍵字,他就指向書本的某一個頁面。又或者是圖書館的書籍編號,有其對應的類別,就可以快速找到放置的位置。
資料庫也是一樣的,我們會對整個資料庫先建構一個索引,也就是說每一筆資料都有一個對應的編碼(Key,但是這個Key 不是關係表中的鍵!)。這個索引(想像成目錄!) 的體積比資料庫小非常的多。既然體積縮小了,我們就可以把他放在記憶體甚至是快取當中,這樣我們就可以快速的找到目標資料到底存在磁碟上的哪個位置。更嚴謹的來說,我們可以把資料庫想成兩個部份,一個就是我們熟知的資料檔案 (Data Files),存放所有寫入的資料,另外一個部分我們稱之為索引檔案 (Index Files),負責記錄每個索引所對應的資料。
索引的方法有很多種,這邊我們介紹幾個。
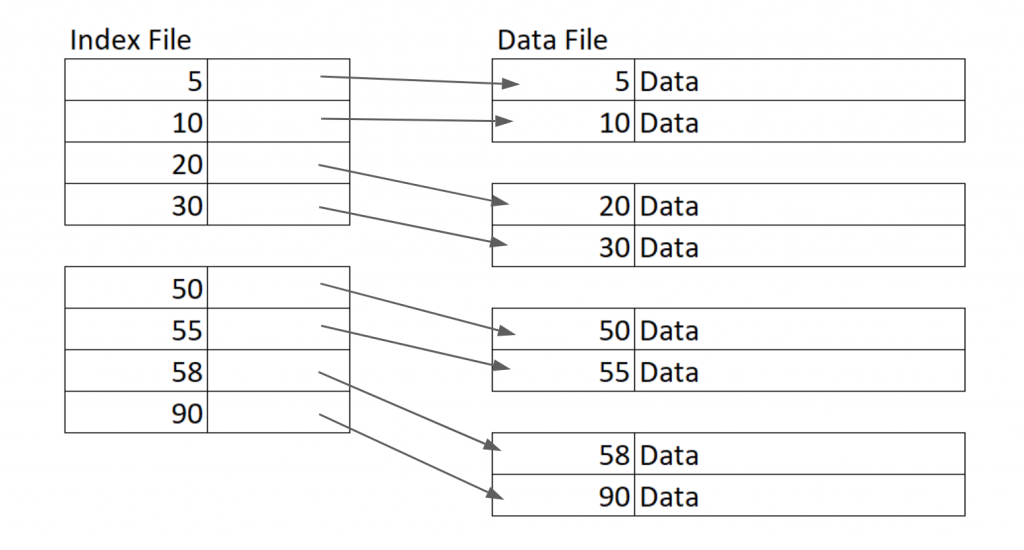
所以如果我們現在想建構一個密集的有序索引就會像這樣,非常的直覺。
當我們換成有序的鬆散的索引就會變成這樣
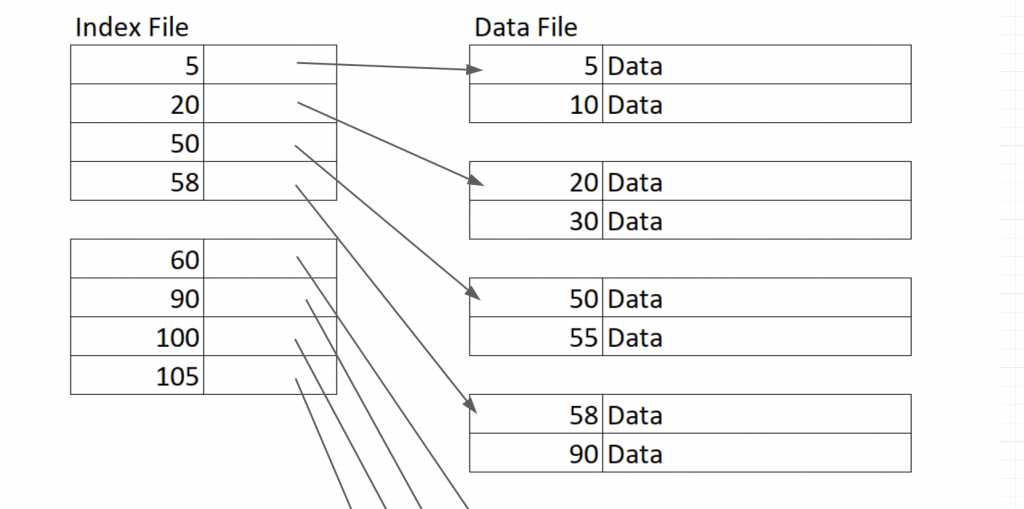
一樣的資料中我們卻使用比上面少一半的索引,這是因為我們所指向的數值可以透過推導的方式找到,例如我想找30,我知道30比50小但是比20大,所以我可以從20開始往下找。這樣就會找到30了。這樣的儲存方式節省了儲存的空間,但相對的在推倒過程需要額外的時間。
今天索引的內容間介紹到這裡,明天的文章中我們會介紹關聯式資料庫最主要使用的索引方式。這個資料結構掌管了關聯式資料庫中的儲存、搜尋、更新、刪除資料的重要功能。

