對一個非本科的工程師來說,對於這類知識大多是第一次接觸的,雖然跟讀資工的同事聊過他們在學校也只有實作簡單的功能,不過至少在要開始嘗試的時候會相對容易許多。在這樣的狀況下,mruby-L1VM 這個專案就變成非常好的學習對象,只有 1000 行左右的程式碼對大部分的工程師都能沒有負擔的閱讀。
在大多數人的認知中 Ruby 是一種直譯語言,也就是在執行的時候才將 Ruby 程式碼轉換成機器可讀取的語言來執行,不過 mruby 作為一個設計給嵌入式系統的語言最有可能遇到的是記憶體和儲存裝置的限制,也因此 mruby 將「編譯」跟「執行」設計成獨立的功能,雖然我們可以將「編譯」的機制包含在我們產出的檔案但是對微控制器來說可能會因為太大而放不進去。
也因此 mruby-L1VM 以及我們這次要挑戰的部分都是「執行」的部分,也就是可以運行由 mruby 編譯出來的機器碼(Byte Code)的實現,跟完整實現編譯器跟虛擬機比起來,我們的難度已經下降了一半。
那麼,我們就開始閱讀 mruby-L1VM 的本體 mruby_l1vm.h 這個檔案吧!
閱讀原始碼的方式有很多種,我自己比較偏好從「功能」開始閱讀,在比較大的專案中完整閱讀原始碼除了非常耗費精力之外,也會因為每個人記憶力和集中力的差異而影響閱讀,從某個功能切入的話就可以依照情況跳過一些程式碼,只專注在我們「想知道」的情報上。
因為我們的目標是「可以執行 Ruby」這件事情,所以第一個步驟是先找到 mruby-L1VM 是怎麼讀取機器碼來執行的。
// test.c
int main(int argc, char** argv) {
// ...
uint8_t buf[maxlen];
// ...
FILE* fp = fopen(fn, "rb");
int filelen = fread(buf, 1, maxlen, fp);
// ...
int n = mrb_run(&vm, buf);
x_printf("%d\n", n);
return 0;
}
在 test.c 這個檔案中我們發現讀取了一個 rb 檔後,會去呼叫 mrb_run 這個方法來執行這個檔案所讀取到的內容。
被 mruby 編譯後的檔案通常會叫做.mrb之類的,這邊似乎是直接用.rb當作副檔名,實際上應該要是一個二進位的檔案。
網友提醒這邊不是副檔名,這是fopen的函式的read binary的意思,寫文章時沒有注意到。
// mruby_l1vm.h
// for mrb 2.0 binary
#define mrb_getIREP(mrb) ((mrb) + 34)
#define mrb_run(vm, mrb) irep_exec((vm), mrb_getIREP(mrb), NULL, 0)
打開 mruby_l1vm.h 之後,會發現實際上呼叫的是 irep_exec 這個方法,不過會先將讀取到的資料向後移動 34 個單位(unit8_t)才讓傳給 irep_exec 使用。
這是因為在 mruby 的設計裡面有檔頭(Header)的設計,用來紀錄檔案的版本跟 CRC 校驗碼等資訊,可以讓虛擬機透過這些資訊來判斷對應的處理,因為 mruby 還在不斷的開發,在寫這篇文章時是 mruby 2.1.2 的版本,產生出來的機器碼會多出幾種不同的 OPCode,而舊版的 mruby 就會因爲無法辨識而無法正常運作。
檔案起始包含了兩種 Header ,第一種是 mrb 檔案的 rite_binary_header 資料。
// mruby/dump.h
/* binary header */
struct rite_binary_header {
uint8_t binary_ident[4]; /* Binary Identifier */
uint8_t binary_version[4]; /* Binary Format Version */
uint8_t binary_crc[2]; /* Binary CRC */
uint8_t binary_size[4]; /* Binary Size */
uint8_t compiler_name[4]; /* Compiler name */
uint8_t compiler_version[4];
};
另一個是被稱為 rite_section_header 的資料,在 mruby 的編譯器中除了程式本身的區段之外之外,也存在著除錯資料的可能性,不過在我們自己製作的虛擬機中還不會碰到,所以我們只需要知道移動 34 個單位的原因是在這邊省略了對這兩種 Header 的處理直接進入 mruby 的資料部分。
/* section header */
#define RITE_SECTION_HEADER \
uint8_t section_ident[4]; \
uint8_t section_size[4]
struct rite_section_header {
RITE_SECTION_HEADER;
};
總體來說,一個 mruby 的機器碼大致上有著這樣的結構。
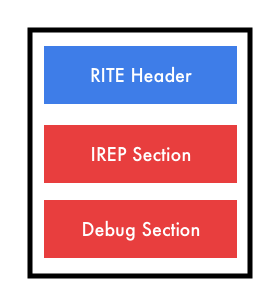
如果我們在使用 mrbc 編譯 Ruby 原始碼的時候不選擇除錯資訊的話,就會將 Debug Section 的部分排除,而檔案也會相對的比較小,在搜集資料時發現 RubyConf TW 2014 年就有日本的講者在台灣演講過,上面的圖片也是參考投影片修正我所知道的資訊後所更正的版本。
下一篇我們會繼續深入 IREP 區塊的資訊進行討論。
文末提到的講者是高橋征義,在 Ruby 圈也是非常知名的大大之一,因為覺得名字很眼熟查了一下原來就是高橋流簡報法的發明人,不過 2014 年我還不知道 mruby 的存在,竟然錯過了一場六年後可能會對自己有幫助的演講。


 iThome鐵人賽
iThome鐵人賽