哈囉大家好,我是橘白卯咪,歡迎大家來看看我能不能撐過30天
開場先來點題外話
最近一直在關注自己的點閱率,有點懷疑自己到底寫得好不好,大家都是看什麼來決定要不要點開一篇文章的呢?
到底要寫的深入一點還是輕鬆一點好呢
寫到第15天了,在毫無存貨的狀況下,會覺得自己寫得有點亂
不過初心就是完賽就好啦~所以今後希望自己能快樂地寫下去~撐完剩下的日子
感謝每個點進來看的人們,橘白卯咪感謝你
如題,訓練模型是一件非常費時的工作
不同的是我使用的這套系統,最費時的部分,在於讓工具從影像當中抓出關鍵點
看完openpose的demo影片,應該會覺得交給它就沒問題了吧
所以我常常晚上12點按下執行,早上6點起來看它跑完沒
就是這個but,跑完了≠跑的是你要的結果啊
今天我們就來看一下一些 不可思議 的畫面
首先是某一次試驗,拿妖怪手錶的舞蹈影片來訓練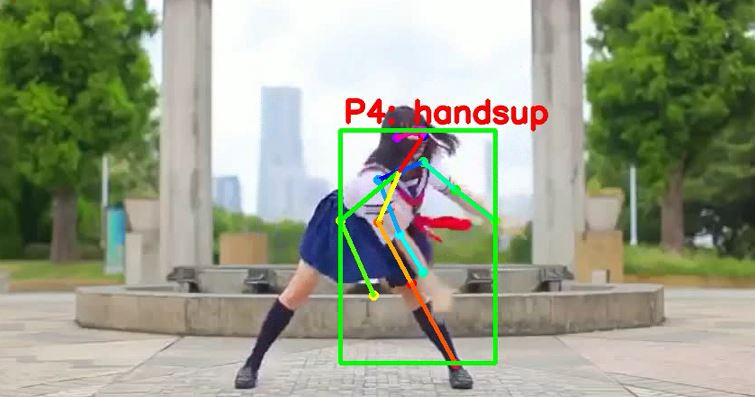
啊諾餒,那個腳的位置是否有點尷尬...這也不是一個handsup的動作啊
關鍵點工具常常在肢體有重疊的狀況下容易誤判,雖然人眼看起來是正常簡單不過的判斷....
再來是常見的,物品誤判情形
領帶被判斷成另一隻手臂了!!!
也因為這樣的狀況經常發生,例如掛著的外套被判斷成靜止、站立的人,所以如果要使用openpose這類的關鍵點工具,要注意場景當中是否有容易導致誤判的雜物
但關鍵點工具之所以蔚為研究與開發的新寵兒,一定是有它厲害的地方,但到頭來,會不會最厲害的還是人類呢?
接下來這張你會覺得它辛苦了
重重字幕遮擋不影響它找到人的決心,問題是,找成後面照片裡的人啦!!
人類可以輕鬆判斷哪一個是目標,也有可能是判斷的依據是動態的、有前後文關係的
但這套工具使用的是一幀幀的影像,所有的人在他眼裡,都是記錄了某個瞬間照片中的"人形"而已
面對以上結果應該怎麼做呢?
我的作法是,在時間容許的狀況下,與其讓它學習錯誤的關鍵點特徵,不如就把那一部分的訓練資料換成正確的資料
當時其他人也提出了不同的做法,例如: 保留該幀但增加其他的判斷、使用上下文判斷決定該幀的正確度
如果是你,會怎麼做呢?
明天,讓我們繼續往建辨識模型的方向走過去~~

