第二天啦~ 今天要講的是如何實作爬蟲,爬台股每五秒指數的歷史資訊。
先到 https://www.twse.com.tw/zh/page/trading/exchange/MI_5MINS_INDEX.html 這個網頁,此網頁是證交所提供的資料,台股各指數每五秒的資訊。
從網址上其實看不出來要怎麼爬,這時候先在網頁上 點右鍵-> 檢查 -> 選擇 Network -> 重新整理網頁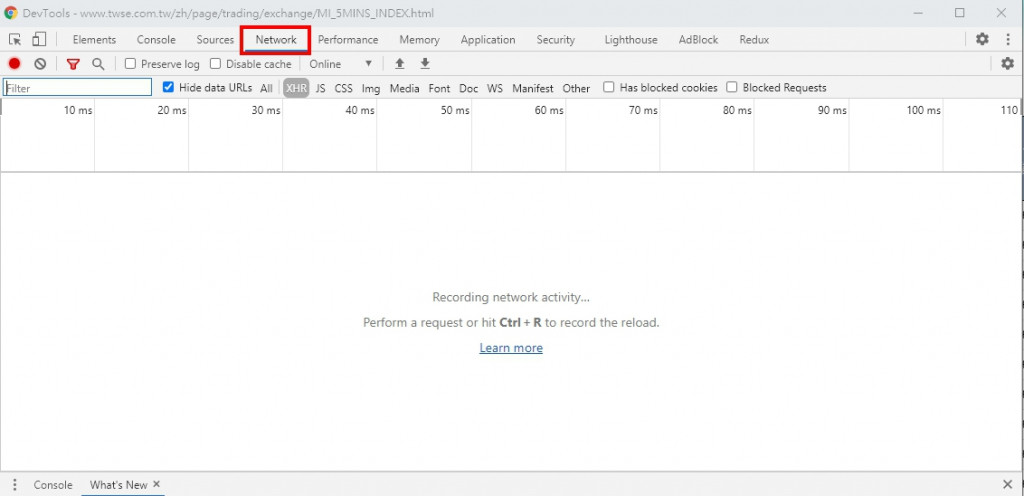
選擇下圖紅色框框圈起來的那個 request,再看到右邊的 request url,這邊看到參數 response 的部份這邊是等於 json,然後 date 的部分是20200914,我們也可以把它改為其他日期,不過格式要符合 YYYYMMDD,如果date是空的話,預設是拿今天的資料。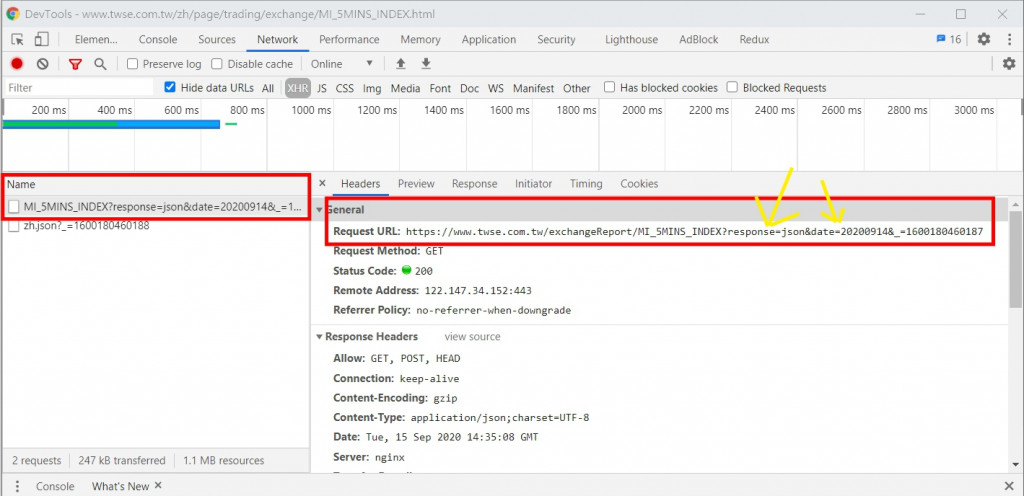
實際上把該網址貼到瀏覽器上執行,會看到以下回傳結果: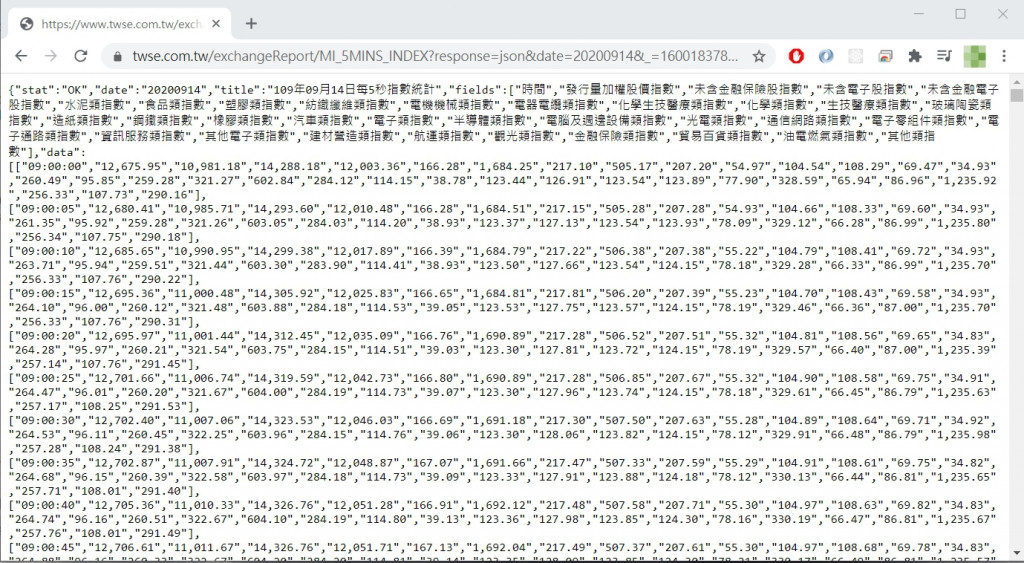
我們可以把 response 參數值改為 csv,然後在瀏覽器上重新執行一次,這次就會直接把資料下載成一個 csv 檔案,那我們之後要爬的時候就是要使用 csv所以 response 的部份要改為 csv。
OK,知道我們要爬的 url 之後,就可以打開我們的工具 jupyter lab,開始實作啦~~
在這之前,先提醒一下,此篇會用到的套件如下:
套件記得要在虛擬環境中安裝哦~
都安裝好了之後,就可以打開 jupyter lab 了
conda activate stockenv (stockenv 請自行修改為自己建立的虛擬環境)jupyter lab 開啟 jupyter lab首先使用 requests 套件,對我們要爬的網頁發出 request 取得資料。
import requests
req = requests.get('https://www.twse.com.tw/exchangeReport/MI_5MINS_INDEX?response=csv&date=20200914')
req.text
若成功執行,你應該可以看到輸出的結果就像下圖那樣密密麻麻的文字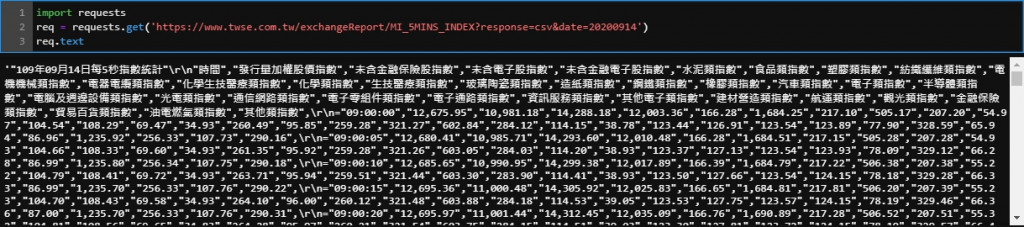
看到這麼一大坨資料其實我們看不出個所以然,所以我們需要 pandas 這個工具,把我們的得到的 csv 資料,用 DataFrame 的方式顯示出來,做法如下:
df = pd.read_csv(StringIO(res.text), header = 1, index_col='時間')
執行後的到的結果如圖: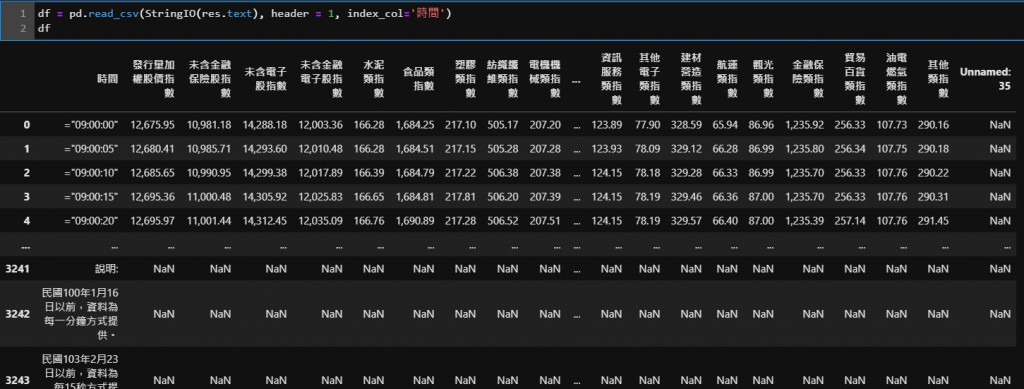
read_csv 這個 function 中,我們第一個參數放的是csv資料,header=1 則代表資料的部分從第一行開始,index_col='時間' 代表我們用 時間 這個欄位作為 column,目前我們已經得到一個不錯的資料格式了。
不過從上圖可以發現時間的部分前面都有一個等號,所以我們要想辦法把它拿掉,以及資料後面有很多 NaN ,這個部分也是我們用不到的,我們可以改進上面的程式達到此效果:
df = pd.read_csv(StringIO(res.text.replace("=", "")), header=1, index_col='時間')
df = df.dropna(how='all', axis=0).dropna(how='all', axis=1)
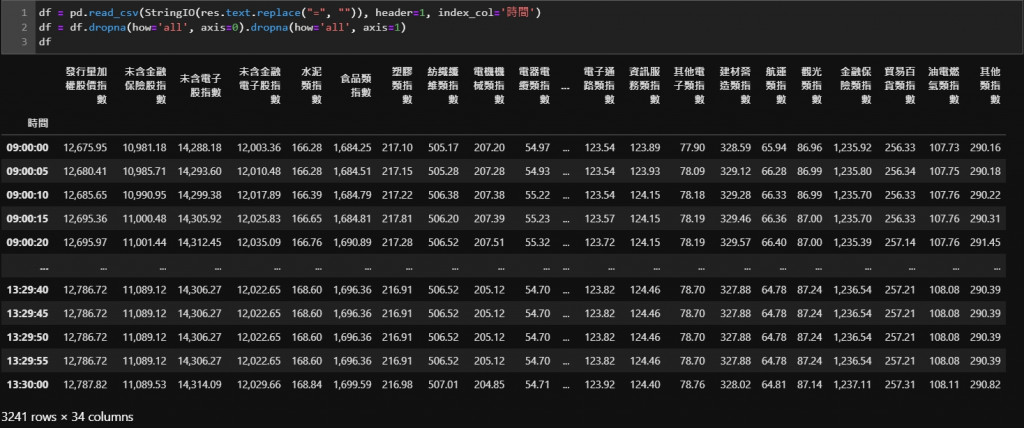
資料終於被我們整理得很乾淨了,今天的任務就到這邊囉!
也可以趕快自己動手試試看囉,證交所網頁上有各種你需要的股市資料,也可以試著爬取不同的資料囉!

