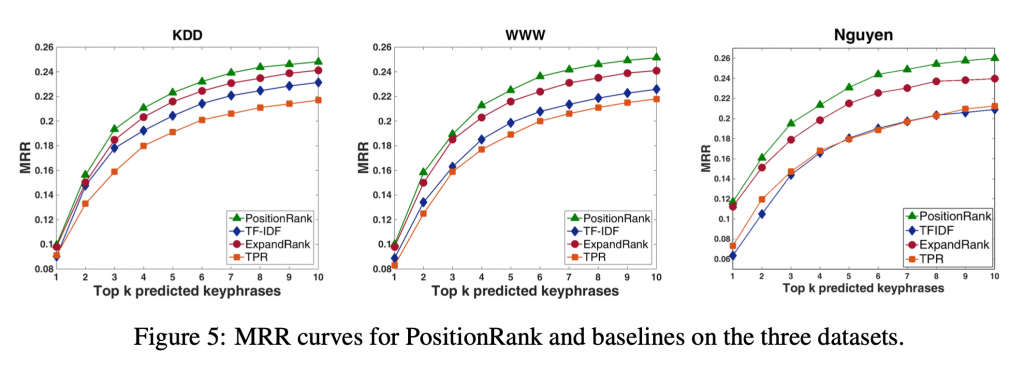
此文章試圖改進原始的 TextRank 的演算法的明顯缺陷:沒有利用到位置資訊。藉由將 PageRank 算法中原有的 Random surfer 訪問不同節點的平均機會改成加權機會在演算法中強調位置資訊。而加權的權重則是將目標詞所有出現位置的倒數加總而來。此文方法在科學文章摘要資料集的各項分數中,顯著地優於 TextRank、TPR 等經典方法。
https://www.aclweb.org/anthology/P17-1102/
1/1 + 1/4 + 1/8 = 1.375。p 的部分,所以可以說這個做法與原始 PageRank 的差別就在這裡而已。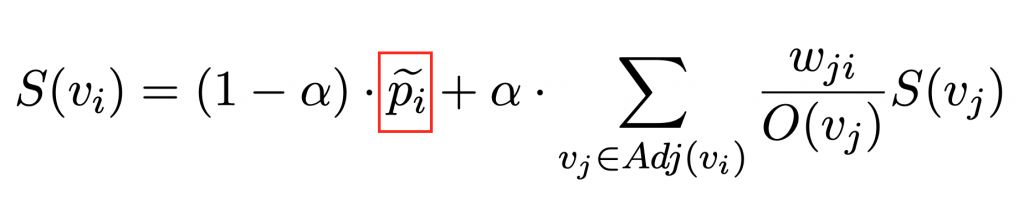



 iThome鐵人賽
iThome鐵人賽