已經知道如何 Index Document 了,但歷史資料這麼巨量,不可能一筆筆打 API 去 Index ,所以今天要來談談 Bulk API。
POST /<target>/_bulk
{ Action }
{ Source data}
Target
可以是 data stream 的名字或是 Index 名字 ( data stream 是啥?再找機會專門來研究)
Action
Bulk 操作支援 create, delete, index 和 update 四種 action。 Action 的格式如下:
{ "index" : { "_index" : "index's name", :"_id" : "document's id" } }
其中 _index 是選填項目,如果在 給定 Index ,可以不用填。有Index 和 Create 的差別是,如果 document 已經存在,index action 會取代舊的 document,而 create 會報錯。
Source data
就是 JSON 格式,要被 Index 的 Document
{ "stock_id":"0050", "date":"2020-09-11", "volume":2905291,"open":103.20, "high":103.35, "low":102.80, "close":103.25 }
大家有沒有覺得我幹嘛把上面這串打出來騙字數?! 這是因為這有個「坑」啊。切記,在 _bulk 操作時, JSON 文件不能「斷行」,必須是同一行才會成功,不然會遭遇以下的 Error。
{
"error" : {
...
"type" : "illegal_argument_exception",
"reason" : "Malformed action/metadata line [3], expected START_OBJECT but found [VALUE_STRING]"
},
"status" : 400
}
現在試試一次 Index 兩筆 Document,如下圖: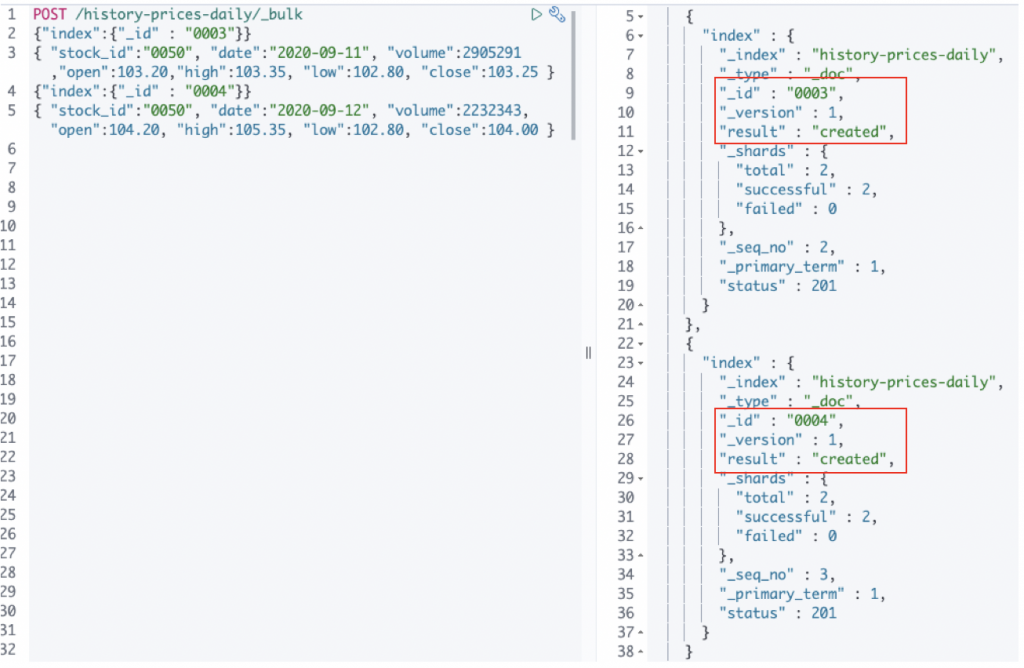
再用 Index 打一次,會得到下面的 Response。
Version number 自動加 1,顯示是 "updated"。 酷!這樣就符合我的使用需求啦!
Bulk request 會被接受請求的 Node 整筆放在 Memory 中,所以太大筆的資料,會影響同一台機器處理其他 Request 的能力。那麼要如何定義適當的 Bulk size ?這是一個值得專門研究的主題,我打算再找一天專門講講。 不過在 Elasticsearch: The Definitive Guide 一書提到一個可供參考的經驗值: 5 - 15 MB。 在我進一步探索前,就用這個值來切資料大小吧!
看來每天都在挖不同的坑給自己跳,明天繼續加油!


 iThome鐵人賽
iThome鐵人賽