利用簡單的方式就可以實現 AI 功能的服務
Cognitive Service 是一個低門檻的 AI 服務,資訊人員可以不用知道 AI 相關的 Domain Knowledge,卻可以實作出許多智慧化的功能,像是辨識圖片、辨識聲音、辨識文意等等。
從技術的角度來説,自己建立模型,並且用此模型解決問題才是真正的AI。但是自己建立模型需要一定的背景知識,礙於成本考量或是專案的狀況,直接聘請一個 Domain Expert 來坐鎮未必是最佳解。所以有些服務,像是 Cognitive Service,已經建立好模型,等待使用者設定一些 Critical Factor,就可以直接使用,這些服務就是 AI 服務。
以下是兩者的特徵比較
| AI 服務 | AI |
|---|---|
| 學會操作後,使用門檻相對低很多 | 需要 Domain Knowledge 從頭開始建立 |
| 專注在 Enable Business/Project | 致力於實現某項智慧功能 |
| 可變動性相對較小 | 可變動性大 |
Cognitive Service 會被包裝成 API 或 SDK 的形式,我們可以在程式碼中呼叫這些服務,並使用回傳的資料完成智慧化的功能。
def predict_sentence(prediction_url, body):
headers = {
# Request headers
'Content-Type': 'application/json',
'Ocp-Apim-Subscription-Key': subscription_key ,
}
url = prediction_url ## API 的URL
response = requests.request("POST", url, data = body, headers=headers)
response_text = json.loads(response.text)
return response_text
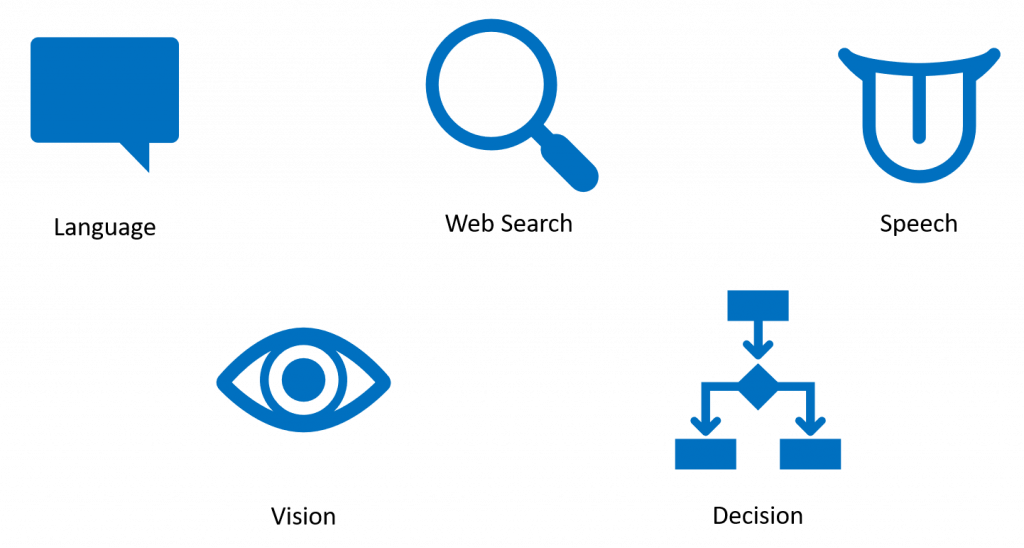
Language : 可以將人說的文句判斷並擷取其中的意思、關鍵字及輿情分析,還可以將一句話翻譯成多種語言。我們也可以創建屬於自己的知識庫,做出一個線上QAWeb search : 利用Bing搜尋引擎尋找想要的內容,最簡單的像是文字搜尋、圖片搜尋,也可以幫忙找拼字錯誤、找品牌、自動預先鍵入Speech : 將語音處理整合到應用程式與服務,文字轉語音、語音轉文字、即時語音翻譯Decision : 更快做出更聰明的決策,可以幫你自動審核影像、文字及影片,提供個人化的使用體驗Vision : 識別及分析圖片、影片和數位筆跡中的內容,偵測、識別、分析人臉,也可以創建專屬於自己的視覺模型接下來 6 天,我會介紹 4 種不同的 Cognitive Service 的操作及設定,分別是

