Overfitting 這個字要怎麼翻譯?網路上查到的有「過度配適」、「過度適應」、「過適」、「過度擬合」、「過擬合」、「過度學習」等等,為了方便,在這裏就用「過適」好了(註一)。
「過適」是訓練深度神經網路 (DNN;Deep Neural Network) 時,必須要避免的現象。一個過適的 DNN ,在實際應用時,預測 (prediction) 及推理 (inference) 的精確度常會偏低,以一個過適的人臉辨識模型為例,也許在實驗室訓練時,精確度可以到達 99%,但是用實際資料驗證時,精確度可能連 50% 都不到。
維基百科上(註二)對於過適現象有一些說明,在此就借用它上面的一張圖。
圖一(來源:維基百科)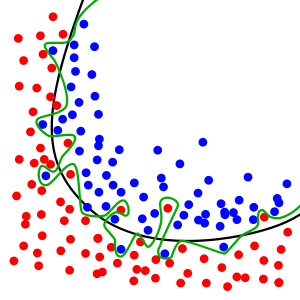
圖一表示一個二元分類問題 (Binary Classification Problem) 的訓練資料集,藍色的點和紅色的點分屬於兩類,黑線表示「無過適模型」的訓練結果,可以看出它在訓練資料集上的準確度並未到達 100%,仍有若干資料點會被錯誤地分類。綠線表示「過適模型」的訓練結果,它能完全正確地分類訓練資料。
圖二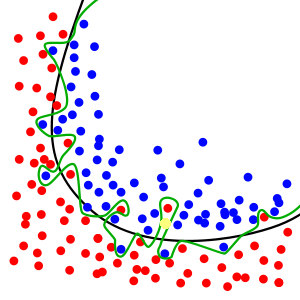
圖二的黃點表示一筆測試(或驗證)資料,如果用「無過適模型」來分類這一個點的話,它是屬於藍色那一類;如果用「過適模型」模型來分類它的話,則會被歸類為紅色那一類。但是綜觀紅點及藍點的分布狀況,黃點應該是屬於藍色那一類,也就是說「過適模型」誤判了它。
由這個例子,大家可以初步地了解過適現象為什麼會造成模型在實際資料(或測試、驗證資料)上較大的誤判率。
老頭在學習 AI 的初期,由於沒有注意過適的避免,鬧了個不大不小的笑話。為了展示研發成果給主管看,我們在展示的當天早上做了一個預演,因為時間太趕,模型還沒有完成訓練(其實是我們自以為它還沒完成),所以就使用某一個檢查點 (checkpoint) 的暫時模型,效果還可以,大家都很滿意。到了下午展示時,拿了剛完成訓練的模型直接上場,結果糟透了,當場被主管打臉!還好有一個同仁機靈,馬上換成上午的版本,並解釋說「剛剛用錯了檔案」才勉強過關。
現在「避免過適」已成為老頭在訓練模型時的一個「第一優先檢查項目」。老頭也建議剛剛入門的 AI 人把過適這個問題好好的研究,並建立避免過適的標準作業程序,網路上有非常多的資源可供大家參考,在此就不贅述了。
(註一:如果要查比較官方的建議,可以上國家教育研究院所提供的學術名詞查詢網站 (http://terms.naer.edu.tw/) ,老頭上去查詢的結果是「過度配適」和「過度擬合」。)
(註二:參考 https://zh.wikipedia.org/wiki/%E9%81%8E%E9%81%A9 )

