
昨日我們完成了前端網頁路徑路由的處理,今天就來讓我們對這些路徑能夠從對應的資料管理系統 API 去抓取資料,並將資料顯示在網頁上。
為了要能夠讓我們發送 HTTP Request 到資料管理系統去獲取資料,我們要使用 Fetch API 來進行抓取資料的動作,其函式為 window.fetch([路徑])。由於這個函式是一個非同步函式(也就是可以與其他的流程同步運行),在 Kotlin 語言裡面,我們可以使用 kotlin-coroutine 去進行非同步函式的處理。為了要使用 kotlin-coroutine 的功能,首先先在 build.gradle.kts 的 dependencies 區塊中,增加下方的這行去安裝該套件:
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.3.9")
接著我們可以先來定義抓取資料用的類別 Fetcher,程式碼如下所示:
import kotlinx.browser.window
import kotlinx.coroutines.await
class Fetcher<T>(val path: String) {
suspend fun fetch(): T =
window.fetch(path).await()
.json().await()
.unsafeCast<T>()
}
在這類別裡面,我們會代入一個 path 變數來作為抓取資料所要發送的 HTTP request 的目的地路徑。而裡面有個函式 fetch() ,整體的內容就是與該路徑抓取資料後,轉成 JSON 格式字串,再將該格式字串轉成 T 型態傳回來。在這個函式裡面,有兩個字詞是之前沒有看過的,分別是 suspend 和 await(),底下就讓我來稍微解釋一下它們代表什麼意思。
由於 window.fetch(path) 抓取資料的動作會花很久的時間,故執行該函式時,它的設計上不會讓主執行緒卡在這個函式的位置,而是會另外利用一個執行緒去進行抓取資料的動作,而讓主執行緒能夠繼續往後去執行。而為了要讓程式知道後續的動作是需要先等待資料抓取完後才能繼續進行的,這裡會使用 await() 函式去中斷後續的動作,直到前面要進行的工作做完才會往後執行,所以 window.fetch(path).await() 和 json().await() 分別就是要等待抓取資料動作結束與將資料轉成 JSON 格式的動作結束為止。而如果在函式內部有用到像是 await() 這種中斷執行的函式的話,其函式定義必須加上 suspend 來表示這是一個會在中途中斷執行的函式的意思。
有了 Fetcher 類別後,我們就可以先利用題目資料來測試看看這個 Fetcher 是否能正常運作。先確認一下其資料在資料管理系統回傳的格式長怎樣,可以在開啟資料管理系統後,利用瀏覽器輸入 http://0.0.0.0:8081/problems 確認,結果如下所示:
{
"data" : [ {
"id" : "9",
"title" : "A + B + C Problem"
}, {
"id" : "10",
"title" : "A + B + C Problem"
}, {
"id" : "11",
"title" : "A + B Problem"
}, {
"id" : "12",
"title" : "A + B + C Problem"
} ]
}
依照這個格式,我們可以建立出能夠裝載這份資料的資料類別 ProblemsData,如下程式碼所示:
data class ProblemsData(
val data: Array<ProblemData>
)
data class ProblemData(
val id: String,
val title: String
)
定義完資料後,就可以建立抓取這份資料的 Fetcher 物件了。這裡在 Fetcher 內部定義一個 companion object,讓 Fetcher 類別本身有一些函式在不需要宣告出物件的情況下,就可以直接被呼叫去建立一個相對應的 Fetcher 物件,如下程式碼所示:
const val DATA_URL = "http://0.0.0.0:8081"
class Fetcher<T>(val path: String) {
companion object {
fun createProblemsFetcher() = Fetcher<ProblemsData>("$DATA_URL/problems")
}
suspend fun fetch(): T = /* ...... fetch() 程式碼部分 ...... */
這樣定義完以後,我們就可以直接使用 Fetcher.createProblemsFetcher() 去創建出可以抓取題目列表資料的 Fetcher 物件。在目前的架構中,先嘗試看看是否可以抓到題目列表吧!建立一個新的 ProblemsArticle Component 去處理顯示題目列表資料的頁面,如下所示:
class ProblemsArticle: RComponent<RProps, RState>() {
override fun RBuilder.render() {
article {
section {
/* ...... 顯示題目列表資料的位置 ...... */
}
}
}
}
fun RBuilder.problemsArticle(handler: RProps.() -> Unit): ReactElement =
child(ProblemsArticle::class) {
attrs(handler)
}
整個類別與 MainArticle 基本上沒有太大的差異,差別只在於 顯示題目列表資料的位置 的地方該怎麼處理拉取題目列表資料與顯示題目列表資料的兩件事情了。由於抓取資料的動作是一個非同步的動作,意思就是當你說要執行這個動作後,預期上會需要等待一段時間後才能得到資料。在 React 中,對於資料變更的部分可以利用 state 來進行實作,state 有一個專門進行修改的函式叫做 setState(),其可以在將 state 中的值變更後,讓 React 自動去更新相對應需要這個 state 資料的地方,藉以讓改變的 Virtual DOM 能夠再刷新到畫面上。故這裡我們要讓 ProblemsArticle 類別使用 state 去做資料改變的狀態處理,讓我們來為 ProblemsArticle 類別建立一個 ProblemsArticleState 的 state 吧!
external interface ProblemsArticleState: RState {
var problemsData: List<ProblemData>
}
ProblemsArticleState 繼承了 RState,並且在裡面放置了我們所需要的 problemsData 資料以進行資料變更與顯示資料的操作。接著就讓 ProblemsArticle 會代入一個 ProblemsArticleState 類別參數,並在初始化的時候開始執行抓取資料的動作,程式碼如下所示:
class ProblemsArticle: RComponent<RProps, ProblemsArticleState>() {
override fun ProblemsArticleState.init() {
problemsData = listOf()
val mainScope = MainScope()
mainScope.launch {
val remoteProblemData = Fetcher.createProblemsFetcher().fetch()
setState {
problemsData = remoteProblemData.data.toList()
}
}
}
override fun RBuilder.render() { /* ...... render() 的程式碼部分 ...... */ }
}
我們在這裡覆寫了 ProblemsArticleState.init(),讓它裡面會先初始化 state 的 problemsData 資料為一個空列表。接著宣告一個 MainScope 這個協同處理用的區塊,利用這個區塊去執行 fetch() 這個可以被中斷使用的函式。如果我們不使用一個區塊去幫我們執行 fetch() 的話,理論上會讓目前所執行的這個執行緒在進入 fetch() 後被裡面的 await() 給中斷,這樣的話程式後面該做的事情就沒有辦法被執行到。為了不發生這種事情,我們必須要跟程式表示這邊是一個協同處理的區塊,內有會被中斷執行的函式,故程式在執行的時候,就會知道在執行時被中斷後,還可以繼續執行這個協同處理區塊後面的事情。那編譯器為了不讓你犯這種錯誤,基本上是沒辦法讓你在不是協同處理區塊的地方呼叫標註有 suspend 的函式。
在協同處理區塊內,我們抓取了題目列表的資料回來,然後利用 setState() 這個函式去重新設定 ProblemsArticleState.problemsData 的值為抓取回來的資料。而由於呼叫了 setState(),故程式就會重新檢查因為 state 變更而需要產生變化的地方有哪些,並且重新比對 Virtual DOM 和實際使用的 DOM 的差異在哪,藉以更新顯示的內容。
那在這裡之所以不使用 props 來實作,原因是 props 並不是要讓你直接對它的值進行修改而設計的,它是為了要因應上層的 state 被改動後,能夠重新反應 state 改動後的資料而設計的。故如果你是有自己需要進行的資料變更,請盡量使用 state 去做設計,並且記得在變更的時候要使用 setState() 函式,否則資料是不會產生更新的唷!
那 render() 的部分可以先簡單的顯示內容即可,如下程式碼所示:
override fun RBuilder.render() {
article {
section {
for (data in state.problemsData) {
div {
+"${data.id} - ${data.title}"
}
}
}
}
}
接著將 App.kt 內 route("/problems") 的地方換成使用 ProblmesArticle。
route("/problems", exact = true) { problemsArticle { } }
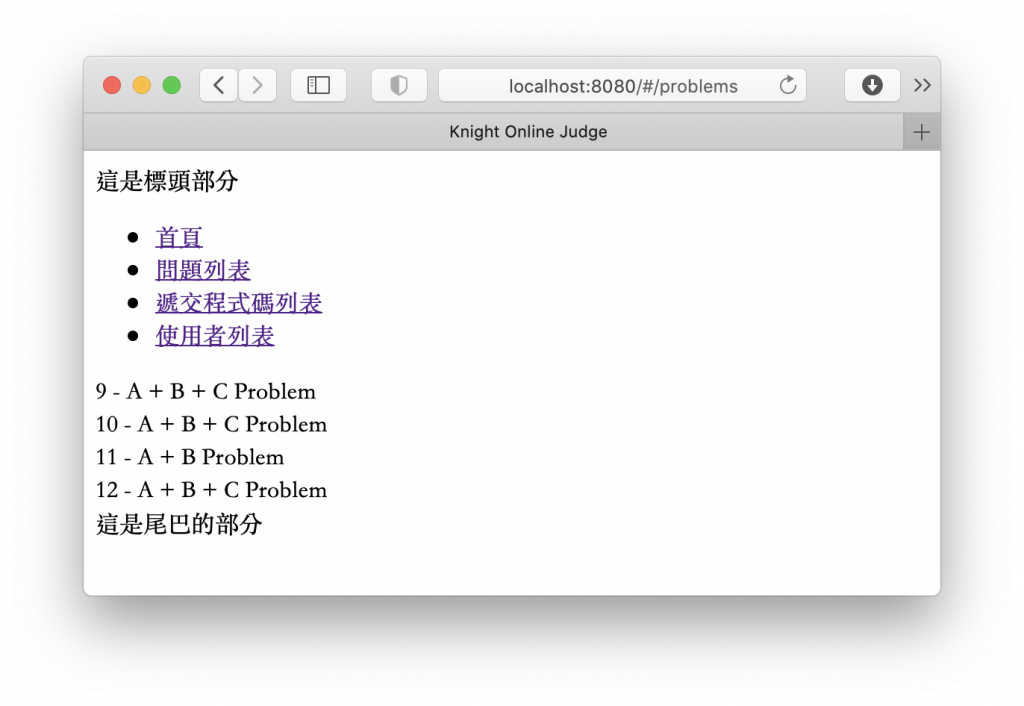
完成後我們就可以來執行看看了,記得在執行的時候要一併打開資料管理系統唷!
執行完了以後,點選「問題列表」,會發現什麼都沒顯示,並且如果打開瀏覽器提供的主控台,會發現類似如下的錯誤訊息出現:

由於我們網頁專案所在的根目錄網址為 http://0.0.0.0:8080,而資料管理系統所在的根目錄網址為 http://0.0.0.0:8081,兩者雖然在同一個 IP 上,但由於 port 不同,故兩者實際上屬於不同的網域。而資料管理系統的伺服器在初始的預設設定會防止這種跨網域的 HTTP request,避免可能是來自惡意客戶端的攻擊,故如果要讓資料管理系統的伺服器能夠正常地給予網頁專案所要求的資料,必須要讓資料管理系統使用 CORS (Cross-Origin Resources Sharing;跨來源資源共用) 這個功能才行。在資料管理系統的專案內,我們可以利用 Ktor 的 install(CORS) 去設定有哪些請求是可以被允許的,程式碼如下所示:
install(CORS) {
method(HttpMethod.Get)
anyHost()
}
在上述的程式碼中,我們利用 method() 函式去表示如果送過來的請求方法為 GET 的話,允許其做 CORS 的請求。而 anyHost() 函式則代表不管請求來自於何方,通通允許其做 CORS 的請求。如果你覺得允許所有來源的請求很危險的話,也可以利用 host() 函式代入允許的網域去局部允許部分網域的請求即可。
這樣設定完後,我們的網頁專案就可以抓到題目列表的資料了,那麼抓取資料顯示的部分就完工了!
今天我們開始可以與資料管理系統進行溝通,獲取我們需要的資料來進行顯示。但是目前網頁的樣子還是有點過於陽春,在繼續將其他的資料抓取下來之前,我們明天就先來看看該怎麼將之前設計的網頁佈局用比較漂亮的方式呈現出來吧!

