今天來介紹網路爬蟲Spider,
Spider這項功能也是滿單純,
就是做一個爬站的動作。
首先需要知道的就是甚麼是爬蟲?
這邊附上一個Wiki的連結:
https://zh.wikipedia.org/wiki/%E7%B6%B2%E8%B7%AF%E7%88%AC%E8%9F%B2
首先要知道一件事情,在談到網路爬蟲的時候,
可能會常看到三個英文單字Spiders/Bots/Crawlers,
其實呀,就把這三個東西視為同個東西就行了!
關於爬蟲可以很簡單的理解成,
利用工具來自動化的去幫我們進行大量瀏覽網站的動作。
網路爬蟲其實有不同的實作方法與不同演算法,
但是大方向來說都會有使用到差不多的方法,
就是會有個初始的URL,獲取頁面之後會解析新的URL。
從起點的頁面開始,解析這個頁面裡面有的URL,
再將解析到的這個URL爬下來(也就是我們這邊講的送出Request/收到Response),
接著再去進一步去解析收到的Response的內容,
如果裡面有其他的URL,就繼續往下重複同樣的動作。
大致了解了甚麼是爬蟲之後呢,
我們就來看看在如何在Burp去使用操作這個Spider功能,
再來比較重要的可能是要稍微知道爬蟲的設定。
Spider下有兩個選項,
分別為Control與Option。
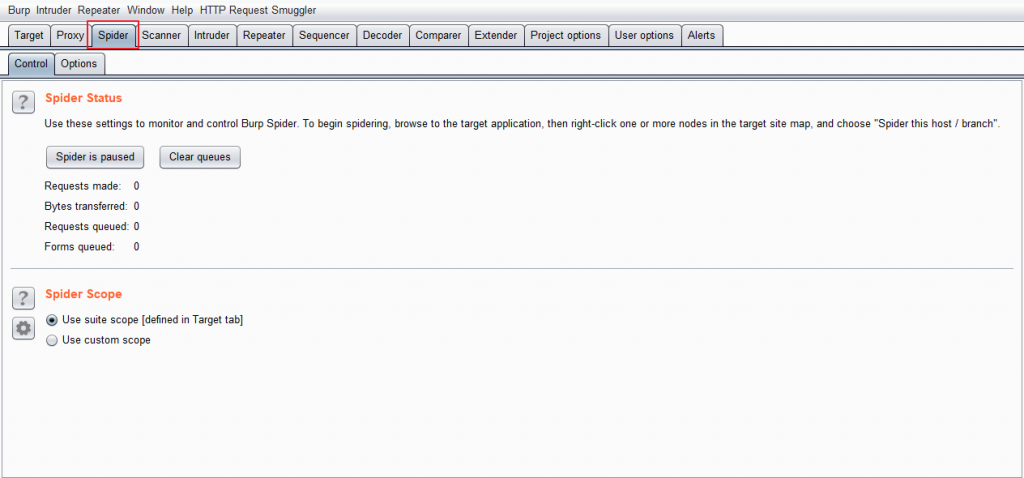
Control下上半部分為Spider Status,
告訴你目前的爬蟲狀態還有可以開始與暫停爬蟲,
顯示的狀態包含了目前送出的請求數量跟正在排隊準備送出的請求數量。
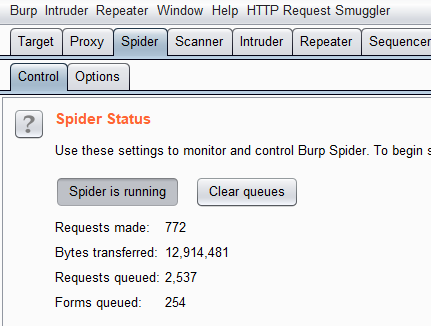
而下半部分則是Spider Scope,
這邊只有兩個選擇可以勾選。
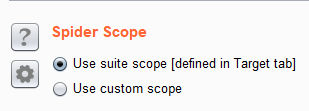
一個其實就是我們昨天所提到的Scope,
當我們勾選Use scope,
這邊爬蟲就只會針對我們Scope的目標去爬。
如果選擇custom的話,
就會出現另一個專門這對Spider功能的Scope。
不過實際上我在測試時很少會動到這邊,
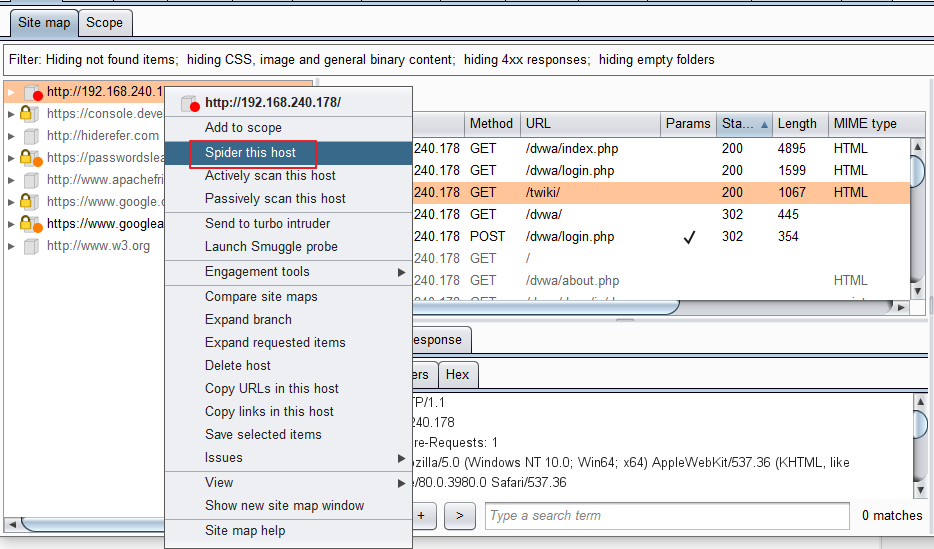
都是直接在SiteMap針對我想進行爬蟲的網站或是節點,
點選右鍵Spider this host或是Spider this branch可以了。
注意!按下去之後Spider就會立刻開始爬站了喔!
不過也要注意一下,在如果還沒加入Scope的話,
會先跳出一個貼心提醒說你現在要爬的站不在Scope裡面,
如果你按下確定要繼續的話它,才會開始爬站,
並且也會將這個網站或是節點路徑加入到Scope當中。

接著來介紹Option部分,這邊內容就比Control地方多了不少。
這邊就是設定關於Spider Engine的各項規則與爬蟲處理方式,
我僅僅只針對到一些我比較常會使用與更動,
或是覺得可能需要特別注意與了解的地方說明。
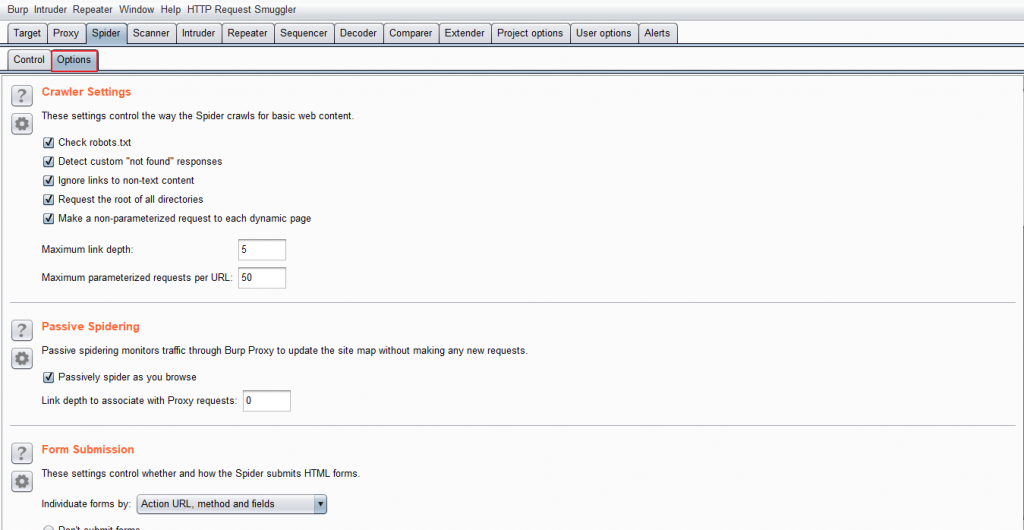
最開頭的Crawler Settings是一些基本設定項目,
這邊基本上就使用預設的設定值與規則沒甚麼問題。
Robots.txt這個檔案是網站中寫給搜尋引擎看的的一個文字檔,
網站可以利用Robots.txt來告訴搜尋引擎,
我網站中的哪些內容不想被搜尋到,哪些想被搜尋到之類的,
不過實際上這個只是一個約定俗成的傳統,
並沒有強制的規範,搜尋引擎要不要照做是它家的事情。
https://zh.wikipedia.org/wiki/Robots.txt
Detect custom "not found" responses,
這個選項會去判斷網站中的404 "not found"的形式,
個人認為這個是作為網站弱掃工程師或是滲透測試人員應該要知道的事情,
大多數的掃描工具或是爬站工具都會有這類型的機制,
因為網站開發人員並不一定會按照RFC規範標準來制定404的頁面,
許多的頁面都是開發人員自己客製化的「404找不到頁面」,
也許畫面中回傳的是404,但是實際上Status Code卻是200 OK,
這個選項就是在協助去判斷究竟甚麼樣的頁面才是真正的"not found"頁面。
Maximum link depth,就是限制爬站的最大深度,同時也避免陷入某些循環中。
Maximum parameterized requests per URL,這項也是覺得需要稍微提一下,
用意在於去限縮某些應用程式僅僅只改變了參數,但其實可能都是同一支應用程式,
譬如以下的網址:
https://hackercat.org/calendar?month=1&day=1&year=2020
https://hackercat.org/calendar?month=2&day=5&year=2020
https://hackercat.org/calendar?month=3&day=8&year=2020
https://hackercat.org/calendar?month=4&day=13&year=2020
........
從上面這個URL可以很合理的觀察與推測,
載入的應用程式為calendar,後面的參數就是年月日,
如果我們沒有設定這個選項,很有可能會無限發散的爬不完。
並且以安全測試的角度來說,
類似這樣的URL,也很有可能只需要去測試其中一個URL即可,
其他頁面皆是以相同的原理去運作,
只要其中一個有漏洞,其他的也就是有漏洞。
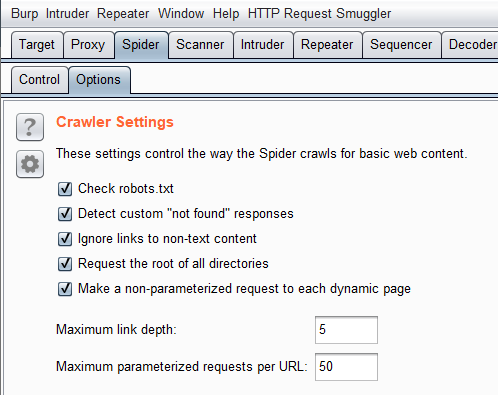
第二個部分是Passive Spidering。
這個表示被動去解析,不會真的送出請求,
(因為沒有送出請求,所以在SiteMap中會呈現灰色狀態)
這也是為什麼有時候你開啟Burp,明明只點了一個網站,
卻發現為什麼Site map出現一大堆東西就這個原因。
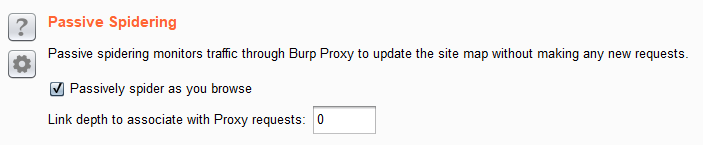
接下來的兩個區塊都是針對於表單的設定,
送出表單完全是根據需求與測試者的習慣做選擇。
網站通常都會有很多表單可送出,
譬如像是帳密的登入、留言、地址、信箱資訊等等,
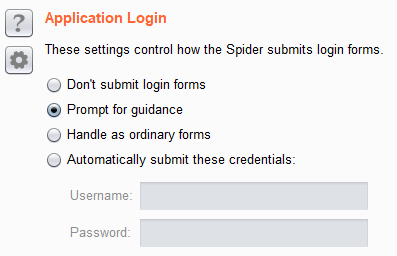
你可以選擇都不要送出表單, 或是自動採用預設內容送出,
也可以讓他遇到表單時跳出提示給你填寫。
預設表單是自動填入送出,登入這種身分驗證的表單則會跳出提示,
這邊我的習慣通常會是都改成不送出,
真的有表單我都會用手動方式去爬,不會利用Spider。
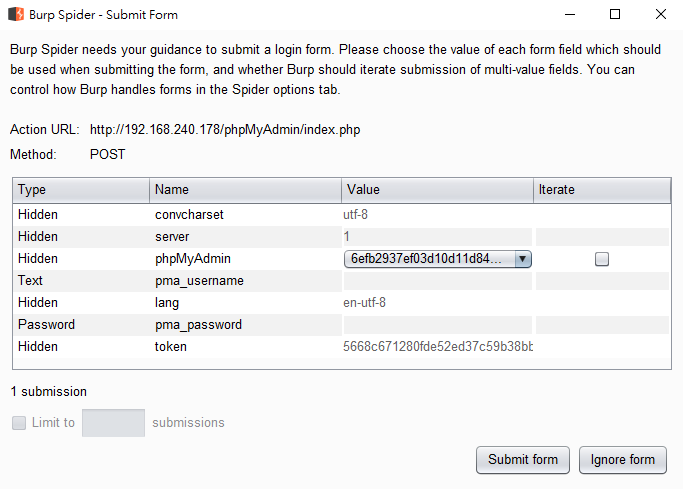
如果是利用跳出提示的方式的話,爬站過程會跳出以下的內容。
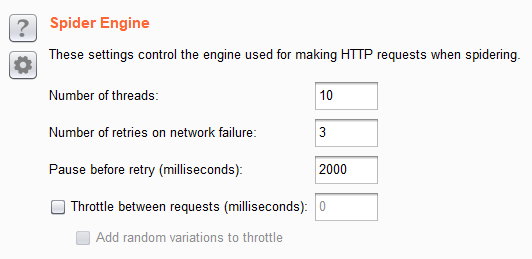
接下來Spider Engine是用來調整掃描threads與速度,
大致上有幾種用途,第一是在於避免讓server crash,
有時候你掃得太快請求量太大,反而把DoS打掛網站。
第二是讓Spider看起來像是human一樣,而不是機器,
尋求穩定性,得到更好的爬站結果。
這邊可以使用預設的值,
但是建議視網站的情形與爬出來的結果做調整。
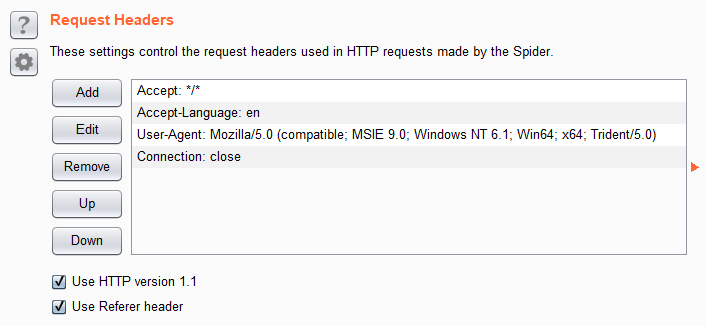
最後一項是Request Headers,
這邊可以在每個送出的請求加上特定的Header。
通常是某些網站會去驗證或是接受某些特定Header使用。
最後還有一點稍微提醒,就是會先建議先使用手動爬網,
再利用spider自行自動爬網,
不要只看到一個頁面,就開始用Spider爬站。
今天關於網路爬蟲Spider介紹就到這裡。

