遇到困難挫折時,多想一下自己的初衷;如果你沒有初衷,那就想一下薪水吧
 筆者有話先說
筆者有話先說我的文章是以專案的角度寫作,遇到問題才會分析解決的方案,與專門介紹套件的文章風格不同,因為這個系列文撰寫的初衷並不是教一個技術而是培養你解決問題的能力
 今日目標
今日目標1.1 用 Google 關鍵字來尋找解答
1.2 調整 chrome 的參數來關閉通知彈窗
2.1 判斷自己的 FB 是經典版本還是新版
2.2 在 .env加入參數來做區別
4.1 程式執行的順序跟你想的不一樣
4.2 從畫面判斷使用者是否登入成功,使用 Class 抓取網頁元件
4.3 加入登入完成才能前往粉專的邏輯
5.1 在粉專頁面找出追蹤人數的位置,並分析取出元件的方法
5.2 取出粉專的追蹤者人數
昨天登入FB的時候應該大家畫面都會長這樣
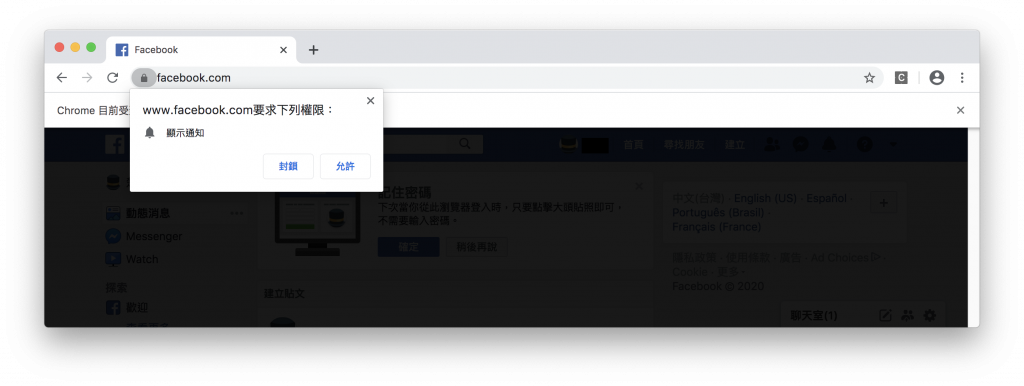
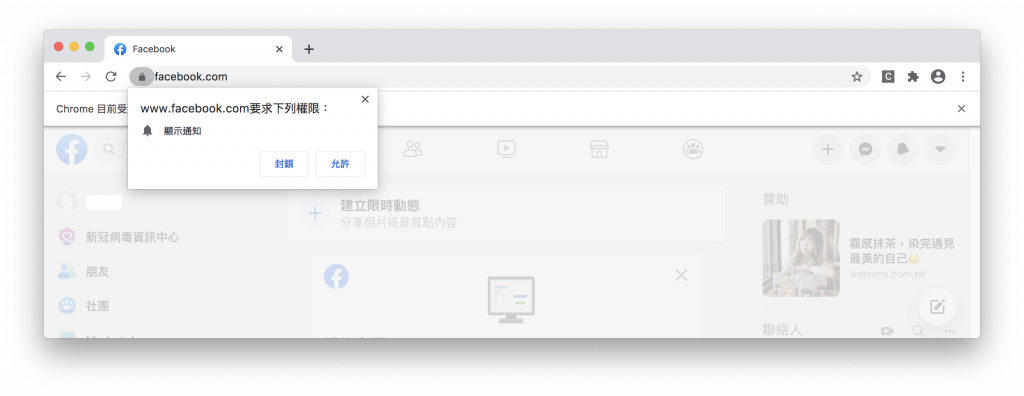
在通知彈窗存在的狀態下是無法抓取網頁元件的(充滿嘗試精神的讀者的可以嘗試看看)
遇到你覺得很多人也會遇到的問題時用 Google 找解答會比你研究文檔快很多,像這個問題在 Google 下關鍵字:nodejs selenium-webdriver notifications,前幾篇一定會有文章能解決你的問題
在這裡 通知 的英文為 notification,
再次提醒用英文比較容易找到解答,如果一開始不知道哪個才是準確的關鍵字,你可以先用 Google 翻譯,然後每個單字都嘗試看看
const chrome = require('selenium-webdriver/chrome');
const options = new chrome.Options();
//因為FB會有notifications干擾到爬蟲,所以要先把它關閉
options.setUserPreferences({ 'profile.default_content_setting_values.notifications': 1 });
let driver = new webdriver.Builder().forBrowser("chrome").
withCapabilities(options).build();// 建立這個browser的類型
yarn start
FB 網頁更新非常頻繁,到現在更有經典版以及新版的區別,如果不清楚自己是什麼版本可以看下面的畫面做判斷
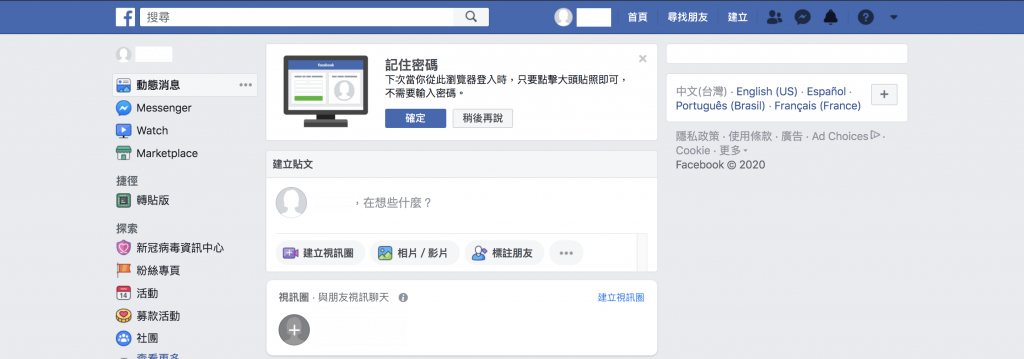
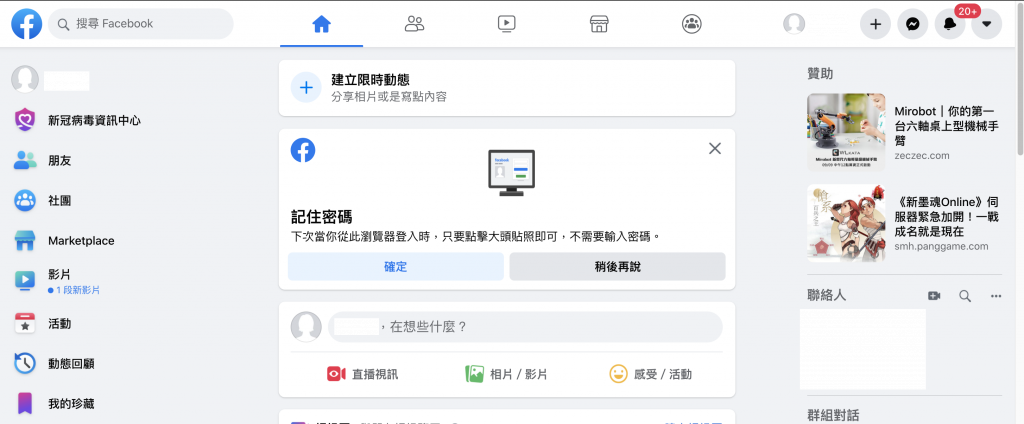
因為有經典版(classic)及新版(new)的區別,所以我們在 .env環境設定檔需要增加一個參數:FB_VERSION 來識別,檔案調整如下:
#填寫自己登入FB的真實資訊(建議開小帳號來實驗,因為帳號使用太頻繁會被官方鎖住)
FB_USERNAME='fb username'
FB_PASSWORD='fb password'
#FB跑經典版還是新版(classic/new)
FB_VERSION='new'
接下來的畫面也會依據經典版以及新版做相關的說明
面對複雜問題時,我一律建議把大問題先拆解成小問題,小問題再細分成功能項目,這樣同一時間只需集中注意力完成一個功能,這樣的做法能帶給你階段性成就感,也讓你大腦有喘息的空間
像是今天要做的功能 前往 FB 粉專取得追蹤人數資訊 可以拆分成幾個步驟:
建議大家可以自己先按照昨天所提供的方法來實做看看會遇到什麼樣的問題,再來看下面我我所遇到的狀況及解決方式
我一開始天真的以為在使用者登入後兩行程式碼就能解決
//登入成功後要前往粉專頁面
const fanpage = "https://www.facebook.com/baobaonevertell/"
await driver.get(fanpage)
但實際執行後你會發現很詭異的事情,在FB登入成功前網頁就直接導向到粉絲專頁了
因為 FB 在執行登入作業時需要等待 server 回應資料確認使用者身份,這塊我們可以從 FB 有什麼元件是登入後才會出現在畫面的這個方向去思考,接下來我會介紹用 Class 抓取網頁元件的方法
_1vp5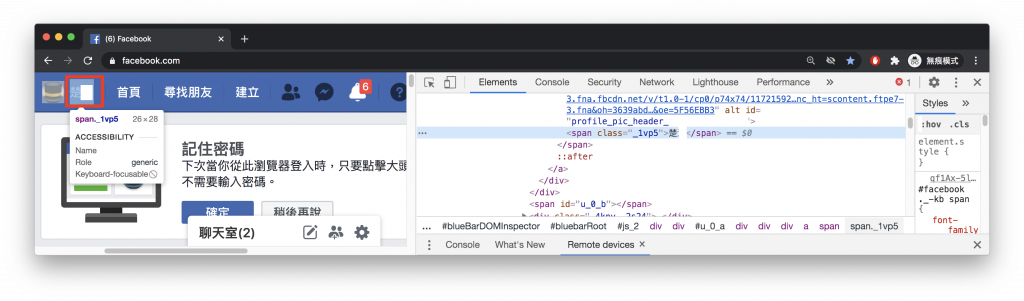
fzdkajry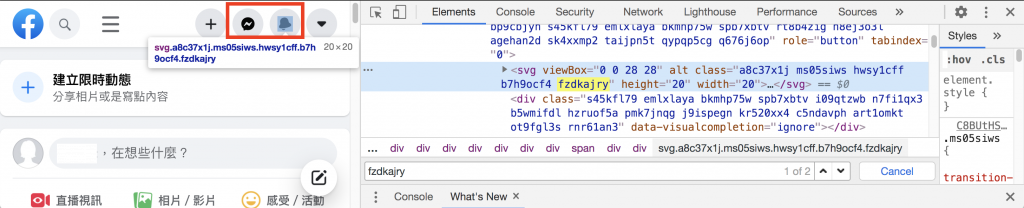
昨天教的用 Xpath 取出元件的方法在這裡不適用,因為他們取出的路徑太過複雜,只要 FB 的版面一改版就有很高的機率壞掉
* 經典版://[@id="u_0_e"]/div[1]/div[1]/div/a/span/span
* 新版: //[@id="mount_0_0"]/div/div[1]/div[1]/div[2]/div[4]/div[1]/div[1]/span/div/div[1]/svg
getCrawlerPath,來回傳各自的爬蟲路徑
function getCrawlerPath () {
if (process.env.FB_VERSION === 'new') {//如果是新版FB
return {
"fb_head_path": `//*[contains(@class,"fzdkajry")]`
}
} else {//如果為設定皆默認為舊版
return {
"fb_head_path": `//*[contains(@class,"_1vp5")]`
}
}
}
fb_head_path,作為判斷登入與否的依據.
.
.
// FB有經典版以及新版的區分,兩者的爬蟲路徑不同,我們藉由函式取得各自的路徑
const { fb_head_path } = getCrawlerPath();
//因為登入這件事情要等server回應,你直接跳轉粉絲專頁會導致登入失敗
//以登入後才會出現的元件作為判斷登入與否的依據
await driver.wait(until.elementLocated(By.xpath(fb_head_path)))
//登入成功後要前往粉專頁面
const fanpage = "https://www.facebook.com/baobaonevertell/"
await driver.get(fanpage)
.
.
.
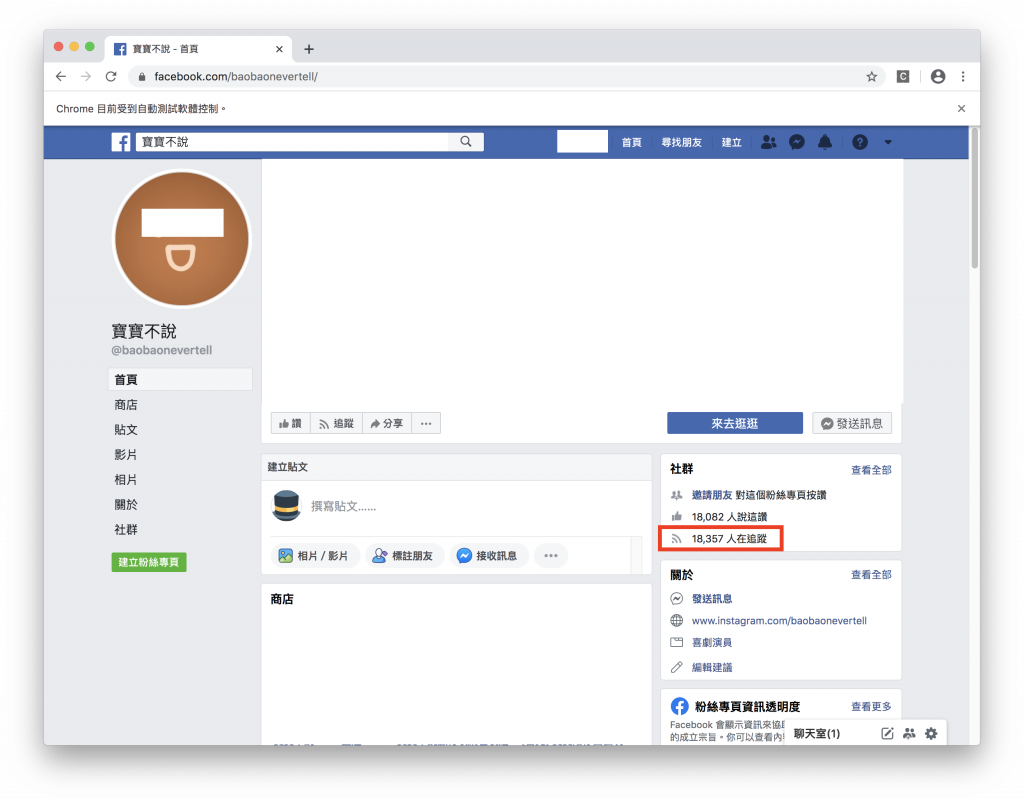
//*[@id="PagesProfileHomeSecondaryColumnPagelet"]/div/div[1]/div/div[1]/div[4]/div/div[2]/div
不是每個粉絲團顯示追蹤人數的 Xpath 位置都一樣,下面的粉絲團網址你可以點進去試試看:
//*[@id="PagesProfileHomeSecondaryColumnPagelet"]/div/div[1]/div/div[2]/div[4]/div/div[2]/div
//*[@id="PagesProfileHomeSecondaryColumnPagelet"]/div/div[3]/div/div[2]/div[4]/div/div[2]/div
下面的幾張圖你可以觀察到這個追蹤者的資訊都在相同的 class="_4bl9" 之下



但是 Facebook 有很多的元件都使用到這個 class 所以我們需要把所有符合的 class 都抓下來,透過分析字串(xxx人在追蹤)來得到正確的資訊
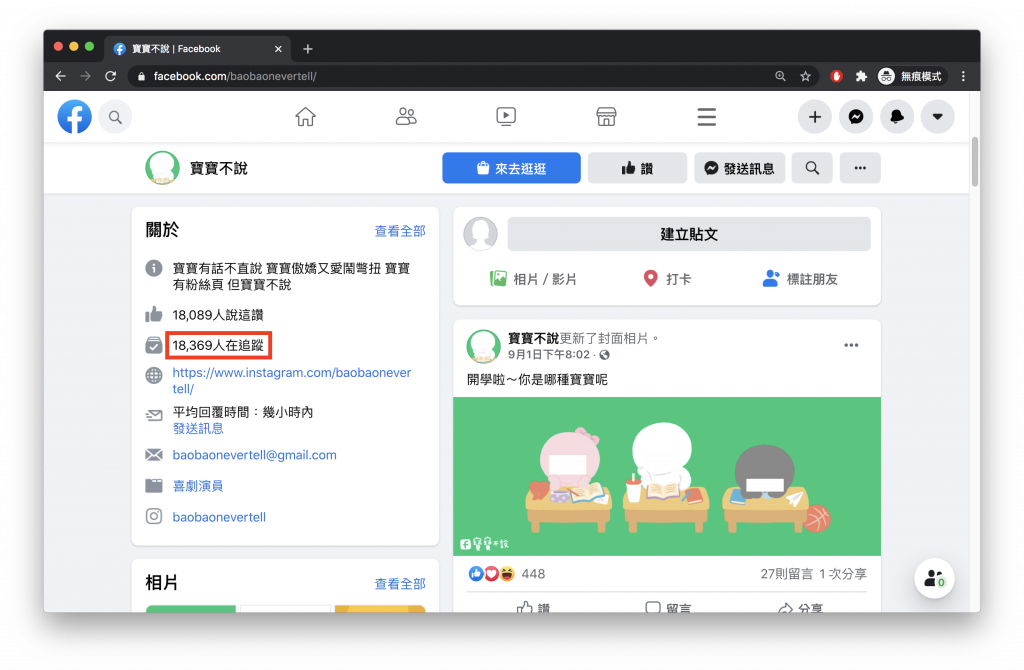
//*[@id="mount_0_0"]/div/div[1]/div[1]/div[3]/div/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[1]/div/div/div/div[2]/div[4]/div/div/div/div[2]/div/div/span/span

在發現這些 class 都與很多 facebook 元件共用的狀態下,你要思考的是哪個元件被共用的次數是最少的,經由這樣的邏輯思考後,發現 class="knvmm38d" 是裡面共用次數最少的getCrawlerPath 回傳參數中
function getCrawlerPath () {
if (process.env.FB_VERSION === 'new') {//如果是新版FB
return {
"fb_head_path": `//*[contains(@class,"fzdkajry")]`,
"fb_trace_path": `//*[contains(@class,"knvmm38d")]`
}
} else {//如果為設定皆默認為舊版
return {
"fb_head_path": `//*[contains(@class,"_1vp5")]`,
"fb_trace_path": `//*[@id="PagesProfileHomeSecondaryColumnPagelet"]//*[contains(@class,"_4bl9")]`
}
}
}
抓取的資料要從複數個 class 裡面篩選出來,但在我們無法決定 class 載入的順序的情況下,偶而會出現抓不到追蹤人數的元件,為了保證元件載入的穩定性,讓瀏覽器前往粉專頁面3秒後再進行爬蟲
await driver.sleep(3000)
.
.
.
await driver.sleep(3000)
let fb_trace = 0;//這是紀錄FB追蹤人數
//因為考慮到登入之後每個粉專顯示追蹤人數的位置都不一樣,所以就採用全抓在分析
const fb_trace_eles = await driver.wait(until.elementsLocated(By.xpath(fb_trace_path)))
for (const fb_trace_ele of fb_trace_eles) {
const fb_text = await fb_trace_ele.getText()
if (fb_text.includes('人在追蹤')) {
fb_trace = fb_text
break
}
}
console.log(`追蹤人數:${fb_trace}`)
.
.
.
儘量不要在 forEach 中使用 aysnc/await,因為他還需要透過一個 callback 函式才能使用,邏輯表現不如 for/of 來的直觀
確認爬蟲都執行完畢後,用下面這行程式即可關閉瀏覽器
driver.quit();
 執行程式
執行程式yarn start

相信到這裡大家都能成功地抓出粉專的追蹤者人數了,對這個爬蟲專案應該也充滿了信心了吧!
 參考資源
參考資源免責聲明:文章技術僅抓取公開數據作爲研究,任何組織和個人不得以此技術盜取他人智慧財產、造成網站損害,否則一切后果由該組織或個人承擔。作者不承擔任何法律及連帶責任!
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、個人研究」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008



 iThome鐵人賽
iThome鐵人賽