除了要有專業外,你更要有技術整合的能力
 筆者有話先說
筆者有話先說這份專案所用到的各種技術都不難,難的是將這些技術整合成一個能讓客戶買單的專案;當時在跟工程師朋友分享這個專案的技術組成時他們都覺得很是獵奇,沒想到爬蟲專案還能用如此低成本的方式完成,而且真的能幫客戶解決問題
今天這篇文章是實作的最後一篇,我們要將爬蟲執行時的資訊做成一份摘要,透過 LINE 發送給使用者
 今日目標
今日目標lineNotify 函式中整合摘要訊息根據需求規格書,在摘要中需包含以下訊息:
crawlerIG、crawlerFB 回傳的結果 result_array 是陣列的形式,所以數量的部分使用陣列的長度即可SPREADSHEET_ID 組成連結crawlerIG、crawlerFB 中紀錄無法爬蟲的標題下面用 crawlerFB 來舉例,crawlerIG 可以自己嘗試修改看看喔~
error_title_array 來紀錄無法爬蟲的標題async function crawlerFB (driver) {
const isLogin = await loginFacebook(driver)
if (isLogin) {
console.log(`FB開始爬蟲`)
let result_array = [], error_title_array = []// 紀錄無法爬蟲的標題
for (fanpage of fanpage_array) {
let trace = null
try {
const isGoFansPage = await goFansPage(driver, fanpage.url)
if (isGoFansPage) {
await driver.sleep((Math.floor(Math.random() * 4) + 3) * 1000)
trace = await getTrace(driver, By, until)
}
if (trace === null) {// 將無法爬蟲的標題放入陣列
error_title_array.push(fanpage.title)
console.log(`${fanpage.title}無法抓取追蹤人數`)
} else {
console.log(`${fanpage.title}追蹤人數:${trace}`)
}
} catch (e) {
console.error(e);
continue;
} finally {
result_array.push({
url: fanpage.url,
title: fanpage.title,
trace: trace
})
}
}
// 回傳爬蟲結果、無法爬蟲的粉專標題
return { "result_array": result_array, "error_title_array": error_title_array }
}
}
spend_time 函式把時間差轉換成 時 分 秒的格式
因為朋友數百個品牌爬蟲總費時快兩小時,如果用秒數呈現實在太不人性化了
lineNotify 所需的參數: 爬蟲總費時(spend_time)、總計掃描FB粉專、IG帳號數量(result_array.length)、無法爬蟲的FB粉專、IG帳號名稱(error_title_array)require('dotenv').config();
const { initDrive } = require("./tools/initDrive.js");
const { crawlerFB } = require("./tools/crawlerFB.js");
const { crawlerIG } = require("./tools/crawlerIG.js");
const { updateGoogleSheets } = require("./tools/google_sheets");
const { lineNotify } = require("./tools/lineNotify.js");
exports.crawler = crawler;
async function crawler () {
const start_time = new Date(); // 取得開始時間
const driver = await initDrive();
if (!driver) {
return
}
// 分別取出爬蟲結果、無法爬蟲的粉專標題
const { "result_array": ig_result_array, "error_title_array": ig_error_title_array } = await crawlerIG(driver)
const { "result_array": fb_result_array, "error_title_array": fb_error_title_array } = await crawlerFB(driver)
driver.quit();
await updateGoogleSheets(ig_result_array, fb_result_array)
const end_time = new Date(); // 取得結束時間
// 計算爬蟲作業總費時
const spend_time = spendTime(start_time, end_time)
// 執行完畢後用 lineNotify 回報爬蟲狀況
lineNotify(spend_time, ig_result_array.length, fb_result_array.length, ig_error_title_array, fb_error_title_array)
}
function spendTime (start_time, end_time) {
const milisecond = end_time.getTime() - start_time.getTime() //時間差的毫秒數
//計算出相差天數
const days = Math.floor(milisecond / (24 * 3600 * 1000))
//計算出小時數
const leave1 = milisecond % (24 * 3600 * 1000)// 計算天數後剩余的毫秒數
const hours = Math.floor(leave1 / (3600 * 1000))
//計算相差分鐘數
const leave2 = leave1 % (3600 * 1000)// 計算小時數後剩余的毫秒數
const minutes = Math.floor(leave2 / (60 * 1000))
//計算相差秒數
const leave3 = leave2 % (60 * 1000)// 計算分鐘數後剩余的毫秒數
const seconds = Math.round(leave3 / 1000)
let time_msg = ""
if (days !== 0)
time_msg = time_msg + days + '天'
if (hours !== 0)
time_msg = time_msg + hours + '小時'
if (minutes !== 0)
time_msg = time_msg + minutes + '分'
if (seconds !== 0)
time_msg = time_msg + seconds + '秒'
return time_msg
}
lineNotify 中整合摘要訊息combineErrMsg 將無法爬蟲的FB粉專、IG帳號標題整合message 變數中const axios = require('axios')
var FormData = require('form-data');
require('dotenv').config();
module.exports.lineNotify = lineNotify;
async function combineErrMsg (error_title_array, type) {
let error_msg = ""
for (const error_title of error_title_array) {
error_msg = error_msg + '\n' + error_title
}
if (error_msg !== "") {
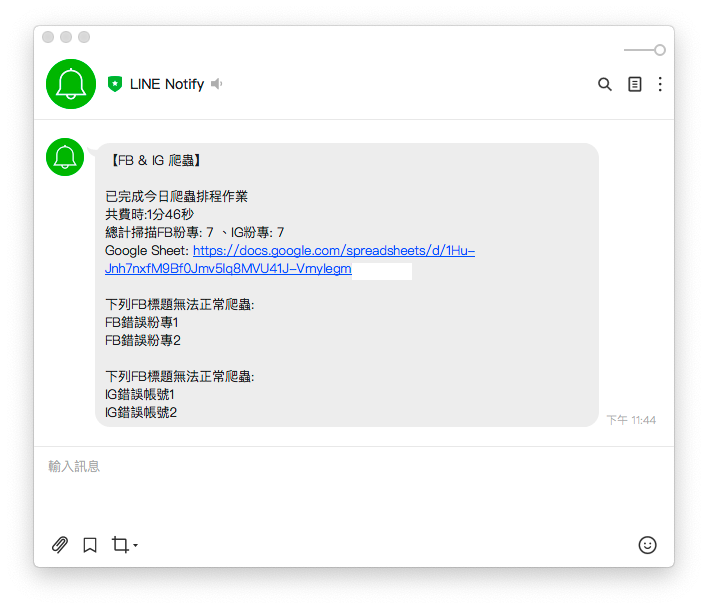
error_msg = `\n\n下列${type}標題無法正常爬蟲:` + error_msg
}
return error_msg
}
async function lineNotify (time, ig_total_page, fb_total_page, ig_error_title_array, fb_error_title_array) {
const token = process.env.LINE_TOKEN;
// 無法爬蟲的FB粉專、IG帳號名稱整合
const fb_error_msg = await combineErrMsg(fb_error_title_array, "FB")
const ig_error_msg = await combineErrMsg(ig_error_title_array, "IG")
let error_msg = fb_error_msg + ig_error_msg
// 組合傳送訊息
const message =
`\n\n已完成今日爬蟲排程作業` +
`\n共費時:${time}` +
`\n總計掃描FB粉專: ${fb_total_page} 、IG帳號: ${ig_total_page}` +
`\nGoogle Sheet: https://docs.google.com/spreadsheets/d/${process.env.SPREADSHEET_ID}` +
error_msg;
const form_data = new FormData();
form_data.append("message", message);
const headers = Object.assign({
'Authorization': `Bearer ${token}`
}, form_data.getHeaders());
axios({
method: 'post',
url: 'https://notify-api.line.me/api/notify',
data: form_data,
headers: headers
}).then(function (response) {
// HTTP狀態碼 200 代表成功
console.log("HTTP狀態碼:" + response.status);
// 觀察回傳的資料是否與 POSTMAN 測試一致
console.log(response.data);
}).catch(function (error) {
console.error("LINE通知發送失敗");
if (error.response) { // 顯示錯誤原因
console.error("HTTP狀態碼:" + error.response.status);
console.error(error.response.data);
} else {
console.error(error);
}
});
}
 執行程式
執行程式我在 ig.json、fb.json 裡面各新增了兩個無效的粉專網址
yarn start
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、自我修煉」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008


