在開始前,想說一下! 感謝團隊的殺氣讓我堅持不懈。
撐過10天了,要換中級題目了。
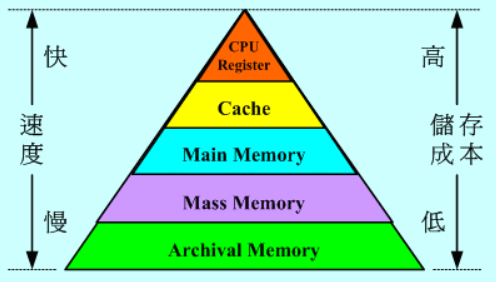
在電腦中,Cache非常地快,但儲存空間非常的小,如何有效率地使用這些空間就是一個許多人在研究的問題。
當Cache存滿了資料,而又有新的資料要放到Cache中,那該把誰請出cache呢? 如果淘汰到很常使用的資料,需要又要去記憶體拿,這樣實在太慢啦!! 這就是快取置換機制在解決的問題。
那最基本的2種作法 就是LRU與LFU。
思想:最近被使用過的資料,那麼將來被訪問的概率也多,最近沒有被訪問,那麼將來被訪問的概率也比較低。
如圖,P1到P7都有最後一次使用的時間,今天如果滿了,我們就淘汰最久沒被使用的,如圖的P7。
但這想法並不考慮頻率,所以會有問題,例如今天突然需要遍歷資料,那這個遍歷會將真正常用的資料淘汰出cache。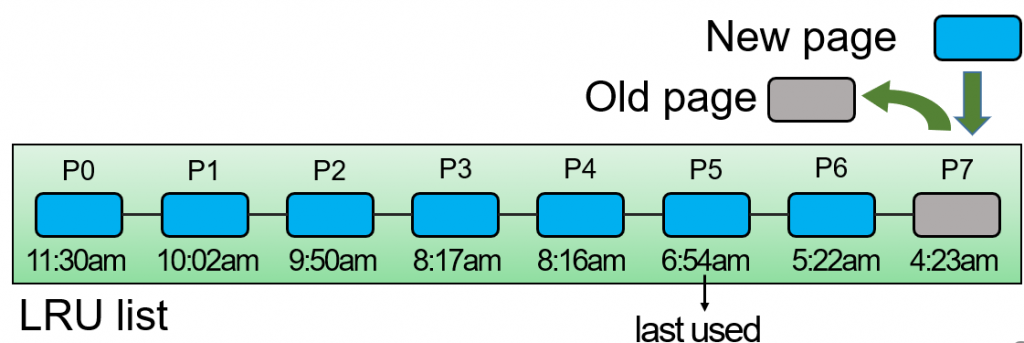
思想:將存取次數最少的淘汰。
記錄在裡面的page,每個被使用的次數,當滿的時候,淘汰使用次數最小的那個,如圖中P7只有2次,為最少的,所以被淘汰。
想當然,只考慮頻率也不對啦,今天一個資料只是短暫地經常被使用,那它的頻率紀錄可能會非常高,就會存在cache中很久之後才可能被淘汰,那就會一直浪費那個空間在那。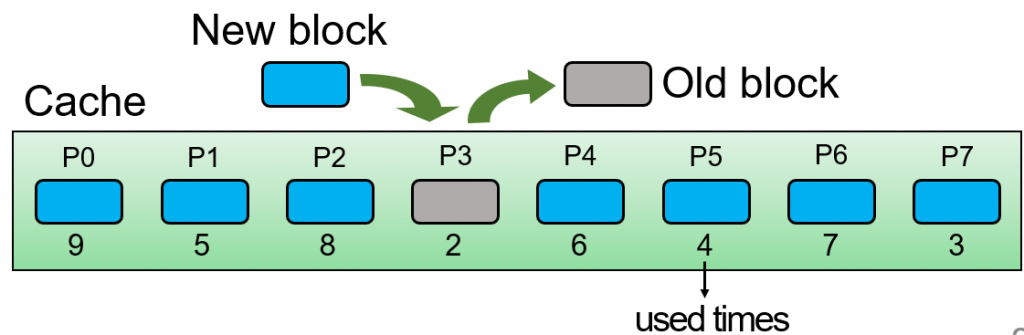
我們能使用linked list,將所有push進來的key-value pair儲存起來,然後只要是被存取到的,就移至最前面,變成head node,那這樣要淘汰的時候,就是淘汰最後一個node。
但使用linked list的缺點就是要搜索時需要 O(n)的時間,所以多用一個hash table同時維護,能使搜索變成只要平均O(1)的時間。
C++ STL有提供資料結構,就不用自己刻了
linked list 是STL中的 list class
hash table 是STL中的 unordered_map
key-value 使用 STL中的pair儲存。
class LRUCache {
list<pair<int,int>> d_list;
unordered_map<int, list<pair<int,int>>::iterator> hash_list;
int cap;
public:
LRUCache(int capacity) {
cap = capacity;
d_list.clear();
hash_list.clear();
}
int get(int key) {
auto itr = hash_list.find(key); //找key
if(itr == hash_list.end()){
//沒找到,直接回傳-1
return -1;
}
//將找到的那個node變成head node
d_list.splice(d_list.begin() , d_list, itr->second);
//更新hash table
hash_list[key] = d_list.begin();
return hash_list[key]->second;
}
void put(int key, int value) {
auto itr = hash_list.find(key); //找key
if(itr != hash_list.end()) { //有找到
//更新value
itr->second->second= value;
//將找到的那個node變成head node
d_list.splice(d_list.begin() , d_list ,itr->second);
}
else{ //沒找到
if(d_list.size() == cap) { //cache滿
//刪除最後一個linked list中最後一個node(最久沒使用的),
//記得hash table, linked list都要刪。
hash_list.erase(d_list.back().first);
d_list.pop_back();
//把新push的這個變成head node。
d_list.push_front(pair<int,int>(key,value));
}
else{ //cache未滿
//把新push的這個變成head node。
d_list.push_front(pair<int,int>(key,value));
}
}
//更新hash table
hash_list[key] = d_list.begin();
}
};