了解製作爬蟲功能前,需要一些前置手續與基礎知識
一種可以在網路上自動抓取資料的工具,又稱「網路爬蟲」(Web Crawler)
在製作爬蟲功能前,需要一些前置手續與基礎知識學習,就讓我們緩緩來看看有哪些步驟。
若是使用 Anaconda 安裝環境的話,Anaconda request 已有內建
用其他方法安裝環境的讀者,可以使用以下指令安裝與更新:
pip install -U requests
使用 get()方法,將 GET 請求發送到指定的 URL,當伺服器接到就會回應
使用方法(使用前需要導入 requests 模組):
import requests
Response 物件變數 = requests.get(url)
而在 Response 物件變數裡可使用以下屬性取得不同的資料:
text:取得網頁的原始碼
response.text
status_code:取得 HTTP 的狀態代碼
response.status_code
若是遇到讀取網頁編碼問題,可以設定 encoding 在做讀取動作,通常常見的編碼有「UTF-8」、「BIG5」
(預設讀取編碼為UTF-8)
response.encoding = 'UTF-8'
若要帶參數查詢,僅需在網址的後方與參數連結的位置之間加上「?」連接,而參數與值之間要用「=」連接,並且參數與參數之間需以「&」連接
這邊使用 value1 及 value2 兩個當參數,參數值分別為 1 跟 2
http://www.testurl.com/index.html?value1=1&value2=2
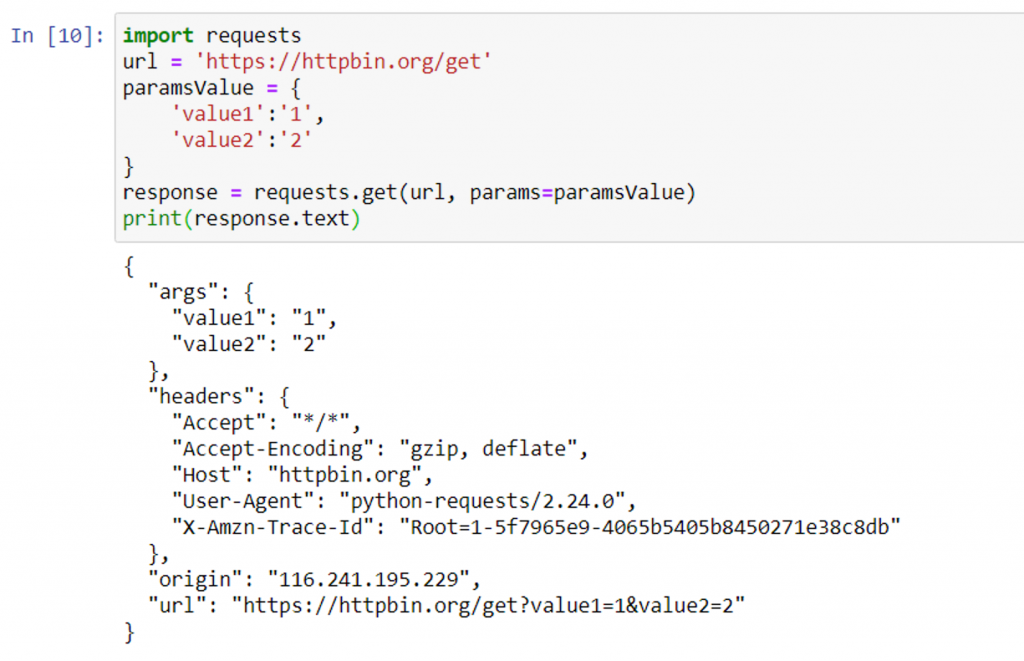
URL 的參數也可使用字典的方式再行帶入 requests.get() 中
paramsValue = {
'value1':'1',
'value2':'2'
}
response = requests.get(url, params=paramsValue)
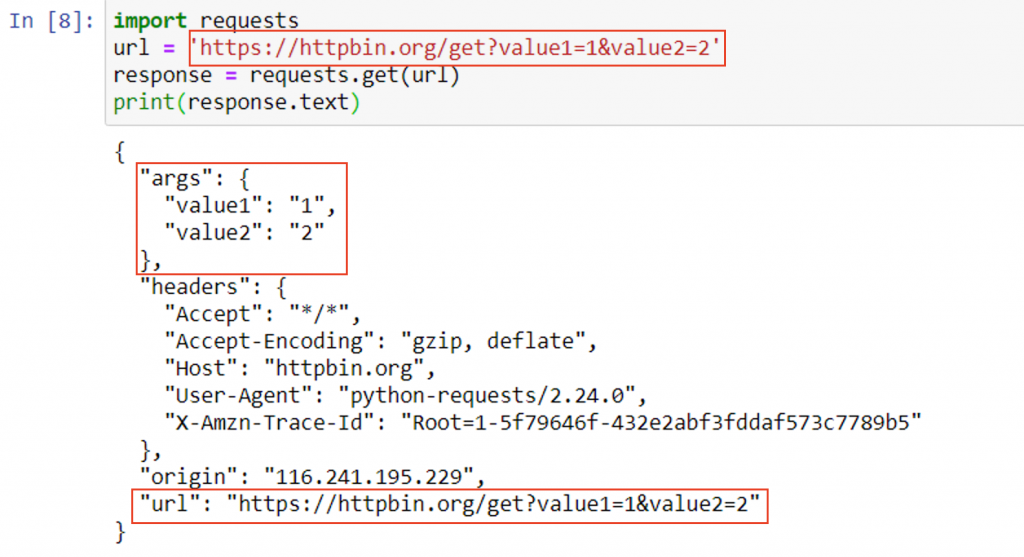
這邊的實作需要說到 httpbin 這個網站,因 httpbin 是一個專門拿來測試 HTTP Request 的工具,只需依照說明文件請求 HTTP Request,就可將請求發送給對方的內容以 JSON 格式回傳,在測試或講解時挺實用
import requests
url = 'https://httpbin.org/get?value1=1&value2=2'
response = requests.get(url)
print(response.text)
import requests
url = 'https://httpbin.org/get'
paramsValue = {
'value1':'1',
'value2':'2'
}
response = requests.get(url, params=paramsValue)
print(response.text)
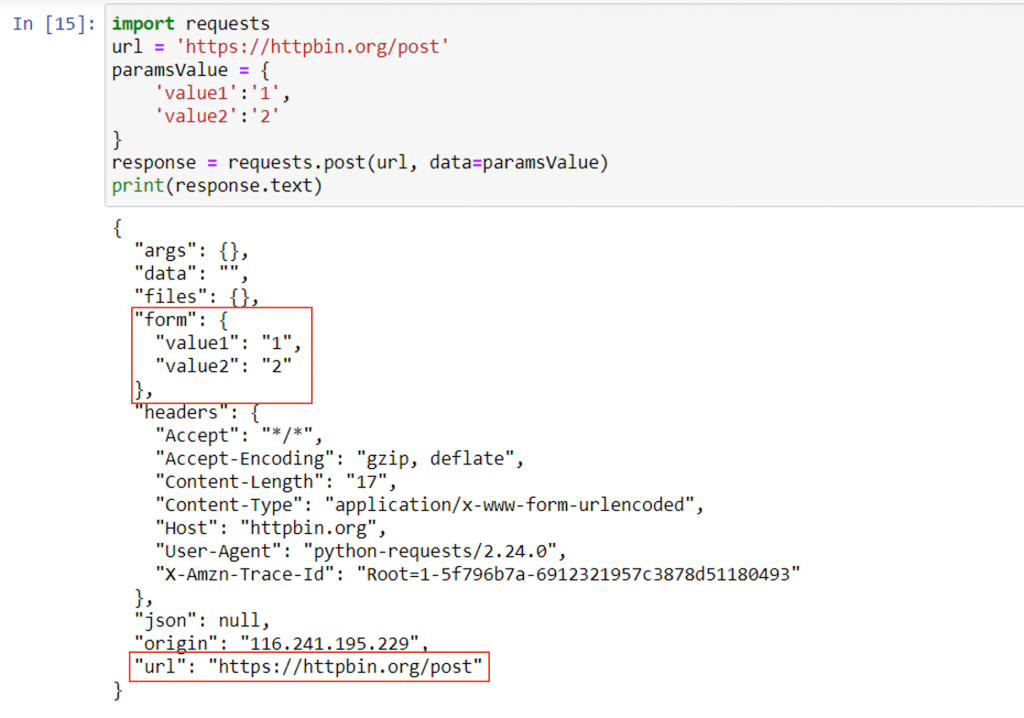
在 requests 模組中,POST 傳遞參數都需要使用字典資料型態,接著如上述 GET 帶字典參數的方法大同小異,僅差在 GET 帶參數內容時,參數值是「params」,而 POST 是「data」
import requests
paramsValue = {
'參數1':'參數值1',
'參數2':'參數值2'
}
Response 物件變數 = requests.post(url, data=paramsValue)
import requests
url = 'https://httpbin.org/post'
paramsValue = {
'value1':'1',
'value2':'2'
}
response = requests.post(url, data=paramsValue)
print(response.text)
在 requests 模組中,還有其他進階的使用方法,但因此系列是給初心者學習的,所以關於這方面就不再繼續解說下去了,若是有興趣的可以自行 Google 學習一下。
接下來,將會說到取得到網頁原始碼後,該如何解析並取得我們想要的數值。

