今天要來學習的是語音辨識,這是一個瀏覽器內建的功能,除了單純輸出文字轉語音之外,還可以用關鍵字觸發一些功能喔
今天的練習還是需要server,可以使用原作者提供的,也可以用自己習慣的喔
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
第一步要先將SpeechRecognition設為全域變數,因為在chrome上會加上前綴(prefix),所以會需要這段
目前僅支持針對桌面和Android的Chrome瀏覽器對Web Speech API語音識別的支持-Chrome自33版本開始就支持該功能,但帶有前綴接口,因此您需要包括它們的前綴版本,例如webkitSpeechRecognition
const recognition = new SpeechRecognition();
recognition.interimResults = true;
要使用SpeechRecognition,要先建立一個SpeechRecognition物件
接下來,將interimResults屬性設為true
interimResults
此屬性控制是否返回臨時結果,臨時結果是尚未最終確定的結果(例如,SpeechRecognitionResultResult.isFinal屬性為false),預設不返回(false)
continuous
此屬性控制每個識別返回連續結果還是返回單個結果,預設單結果
lang
此屬性返回並設置當前SpeechRecognition的語言,如果未指定,則默認為HTML lang屬性值,又或者是用戶代理(user-agent)的語言設置。
let p = document.createElement('p');
const words = document.querySelector('.words');
words.appendChild(p);
最後,新增一個<p>,並將它貼在.words裡,第一步就結束了
接下來要開始處理語音辨識回傳的結果
recognition.addEventListener('result', e => {
console.log(e);
});
recognition.start();
今天要監聽的事件是result,觸發事件後可以得到以下結果
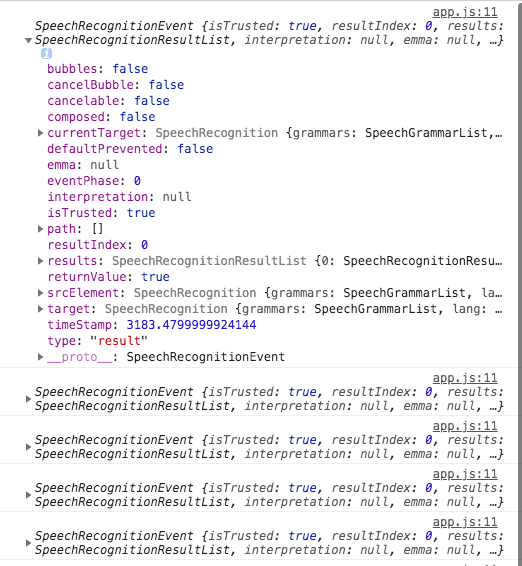
這些資料當然是要再做進一步的處理
recognition.addEventListener('result', e => {
console.log(e.results);
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('')
console.log(transcript)
p.textContent = transcript;
});
recognition.start();
這邊只需要results裡面的資料,這邊results還是一個個分散的資料,所以這邊用Array.from()將它們整併成一個陣列
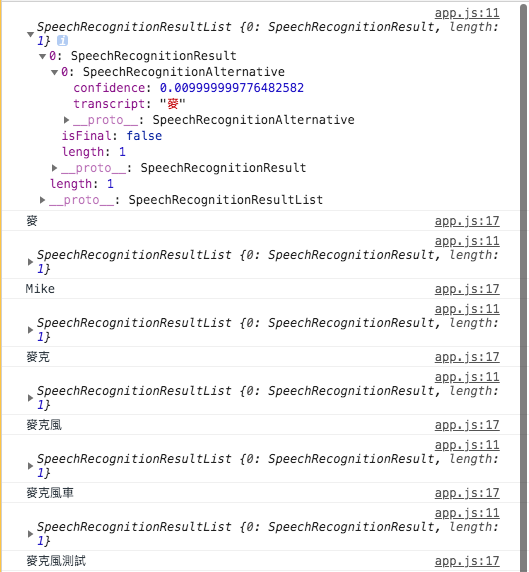
接下來,把前面設置的段落內容設為語音辨識的結果字串,就可以在前端畫面看到輸出的結果了
做完上面的步驟後,結果是得到了,但是有沒有發現它輸出完一次,之後語音辨識就停止了
那是因為我們只有在頁面讀取的時候啟動語音辨識,當它辨識完也沒有再被啟動
recognition.addEventListener('end', recognition.start);
所以我們要加入一個事件監聽器,當事件結束(end),要再重啟語音辨識
語音辨識重啟了,但它怎麼就把之前的結果覆寫了呢?
recognition.addEventListener('result', e => {
// console.log(e.results);
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('')
p.textContent = transcript;
if(e.results[0].isFinal) {
p = document.createElement('p');
words.appendChild(p)
}
console.log(transcript)
});
這邊我們需要在一段話辨識完之後,新增一個新的段落,然後貼上新的內容
isFinal屬性正是用於紀錄使用者是否停止輸入
最後,我們可以做一些應用
if(transcript.includes('天氣')) {
console.log('查詢天氣')
}
這邊可以設定關鍵字,每當使用者提到關鍵字就觸發一個function,例如,我在這邊設關鍵字為天氣,當使用者提到天氣,就可以觸發一個查詢天氣的function,這樣就可以實現語音控制的功能
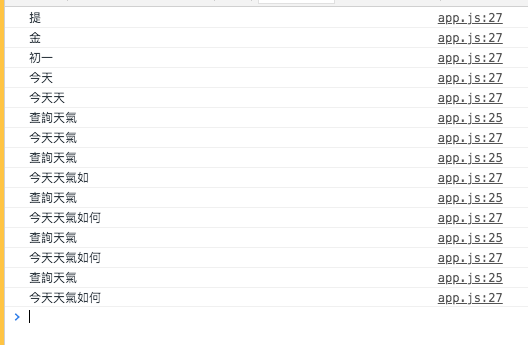
是不是很有趣呢
不過這邊可能還需要加入之前在slide in on scroll提過的debounce,來減少function觸發的次數

