上面兩章節簡單的介紹了一下什麼是JS與特性,而本章節開始會正式進入到JS中,而一開始我們先從作用域開始介紹,什麼是作用域?作用域就是一個變數的生存範圍,一旦超出了這麼範圍就無法存取到這個變數,定義了變量在哪裡存活與我們能在哪裡找到他,這就是作用域。
作用域主要是在編譯的時候定義的,所以需要了解JS編譯與執行之間的關係。
在一般的編譯器中,編譯一般分為三個階段 :
1.Tokenizing/Lexing : 將程式碼分解為對JS有意義的token,舉個例子,若有一段程式碼var a = 2;那們它將會被分解為var、a、=、2和;,至於空格則取決於是否有意義而選擇性的轉換。
2.Parsing : 獲取所有的token並將他們轉換為AST(Avstract Syntax Tree)。舉例來若將var a = 2;轉換為AST,可以從最頂端的節點VariableDeclaration開始,它底下有兩個子節點,一個是代表著變量a的identifier與代表擁有數值的AssignmentExpression,而代表有數值節點下有一個NumericLiteral的子節點代表數值(2)。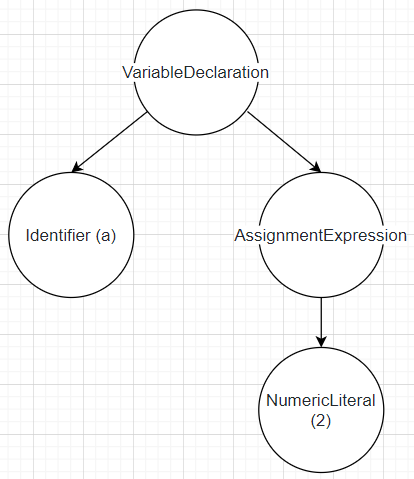
3.Code Generation : 執行AST並將它轉換為可以執行得代碼,這個轉換會因為不同語言而有不同的結果,以JS來說它會對var a = 2;這個程式碼轉換成一組機械指令,將創建一個稱為a的變量並將2賦予給這個變量。
由於JS與大部分語言一樣它不會再build的時期就提前編譯,而這個動作必須發收生在執行代碼前幾ms的時間,為了確保擁有最快的性能,JS引擎就使用了各種技巧(JIT,lazy compile...)這些就不再此處進行討論。
為了簡單的描述JS對於程式的處理,可以簡單的分為解析/編譯然後是執行,雖然JS沒有明確的要求進行編譯,但是它對於程式實質上的行為卻是需要編譯後才能執行的。
我們以下面三個例子來證明這點 :
var greeting = 'Hello';
console.log(greeting);
greeting = .'Hi'; //SyntaxError: unexpected token .
上面的程式中"Hello"並不會被輸出,它擲出了一個SymtaxError,因為在Hi前面有一個非預期的token,以上面的例子中,若JS是由上而下一行一行的編譯的話,那麼應該會先輸出"Hello"後才發生錯誤才對,但事實上JS引擎能夠知道在第三行中有一個syntaxError,所以JS引擎會在執行前先解析整個程式。
console.log("Howdy");
saySomething("Hello","Hi");
// Uncaught SyntaxError: Duplicate parameter name not
// allowed in this context
function saySomething(greeting,greeting) {
"use strict";
console.log(greeting);
}
上面的例子中也會擲出一個SyntaxError,因為我們在saySomething這個函數中使用了嚴格模式,而嚴格模式禁止function的參數使用一樣的名子,雖然拋出的錯誤並不是語法錯誤,但是在嚴格模式下這個錯誤會在執行前被擲出並被當成early error。
而這個例子再次證明了JS會在執行代碼前對程式完全的解析,因為不這麼做的話它就不會知道function中有兩個一樣名子的參數與funciton中使用的是嚴格模式。
function saySomething() {
var greeting = "Hello";
{
greeting = "Howdy"; // error comes from here
let greeting = "Hi";
console.log(greeting);
}
}
saySomething();
// ReferenceError: Cannot access 'greeting' before
// initialization
上面了例子中,因為在let宣告greeting之前就使用了這個變量(let不會hoasting)所以導致了ReferenceError,這個例子也證明了JS是需要先將全部程式編譯後才會執行。
在了解了JS引擎處理程式的兩個階段後,我們再回到JS引擎是如何識別便量並確定它在程式中的使用範圍。
為了更深入地理解需要了解更多的編譯器術語,這邊會介紹LHS查詢(Left-hand Side)和RHS查詢(Right-hand Side),簡單來說當一個變量出現在賦值的左邊時會進行LHS查詢,當一個變量出現在賦值操作的右手邊會進行RHS查詢,說得更準確一點:
var students = [
{ id: 14, name: "Kyle" },
{ id: 73, name: "Suzy" },
{ id: 112, name: "Frank" },
{ id: 6, name: "Sarah" }
];
function getStudentName(studentID) {
for (let student of students) {
if (student.id == studentID) {
return student.name;
}
}
}
var nextStudent = getStudentName(73);
console.log(nextStudent); //Suzy
我們先找到上面例子中的Targets。
students = [...]
這個很顯然是一個Target,因為students被賦予了一個陣列的值,它與nextStudent = getStudentName(73)一樣都是賦值操作。
for(let student of students)
這裡是一個比較難發現的Target,這句程式的意思是將students這個陣列迭代給student這個變數,所以也是一個賦值(只是不太明顯)。
getStudentName(73);
這裡也是一個隱性的Target,因為它將73這個數值賦予給getStudentName這個function的參數。
for(let student of students)
上面提到student是屬於被賦值的target,那麼students這個陣列便是給予數值的source
if(student.id == studentID)
在這邊的student與studentID都是屬於source reference。
return student.name
這邊的student也是屬於source,因為它提供了可以retuen的值。
在舉個簡單的例子:
function foo(a){
console.log(a);
}
foo(2);
上面的例子既有LHS也有RHS,我們仔細地對它進行分析 :
foo的RHS,它代表著去查詢foo的值並將結果交給引擎。console.log(...)時,它會對console這個物件進行一個RHS查詢,查詢是否有一個log的mathod。log(...)時,因為2被賦予給了log的參數,所以也進行了一次LHS。作用域是通過標示福明成查詢變量的規則,但是通常會有多餘一個作用域的問題需要考慮,就像一個程式嵌套在另一個程式碼區域或函數中,作用域也會被嵌套在其他作用域中,所以如果再直接作用域找不到需要的變量,則會往外層作用域尋找,如此繼續找到最外層作用域(全域作用域)。
舉個例子 :
function foo(a){
console.log(a + b);
}
var b = 2;
foo(2); //4
以上面的例子來說,當JS引擎在直接作用域(函式foo中)找不到b這個變量,那麼它就會訪問外層的作用域(全域作用域)看是否有b這個變數可以讓它進行RHS。
遍歷嵌套作用域的規則很簡單,JS引擎從當前執行的作用域開始查找變量,如果沒有找到就向上走一級繼續查找,如此類推。如果到了最外層(全局作用域),那麼查找就會停止無論它是否找到了變量。
為什麼需要了解LHS與RHS?
因為在一個變量還沒被宣告的情況下,這兩種類型的查詢做了完全不同的行為。
function foo(a){
console.log(a + b);
b = a;
}
foo(2);
ReferenceError。而若一個RHS查詢到了需要的變量,但是卻對這個變量做這個值不可能做到的事,比如將這個非函數的值當作函數執行,或是引用null或undefined,那們JS引擎就會拋出種類錯誤TypeError。
所以ReferenceError是對於作用域解析失敗,而TypeError則是作用域解析成功了但是對對這個解析成功的變量做非法/不可能的操作。
參考文獻 :
You Don'y Know JavaScript
You Don'y Know JavaScript 2nd
 Fandix
Fandix
