Motivation:
蒐集相關工具: 視覺化 PCAP By matplotlib
大致步驟
Scapy Output -> Pandas DataFrame --> Visualizations
程式原始碼可參考以下連結:
Learning Packet Analysis with Data Science
No Jupyter But Only Terminal env. Version:
PS 1: 自己改寫版,有刪除部份程式碼,只留下輸出圖片的部份
PS 2: suspicious.pcap 可在 這裡 取得
$ sudo python3 packetAnalytics.py
from scapy.all import * # Packet manipulation
import pandas as pd # Pandas - Create and Manipulate DataFrames
import numpy as np # Math Stuff (don't worry only used for one line :] )
import binascii # Binary to Ascii
import seaborn as sns
sns.set(color_codes=True)
'''Use common fields in IP Packet to perform exploratory analysis on PCAP'''
num_of_packets_to_sniff = 100
pcap = sniff(count=num_of_packets_to_sniff)
pcap = pcap+rdpcap("suspicious.pcap")
# Scapy provides this via import statements
from scapy.layers.l2 import Ether
from scapy.layers.inet import IP
from scapy.layers.inet import TCP, UDP
# Collect field names from IP/TCP/UDP (These will be columns in DF)
ip_fields = [field.name for field in IP().fields_desc]
tcp_fields = [field.name for field in TCP().fields_desc]
udp_fields = [field.name for field in UDP().fields_desc]
dataframe_fields = ip_fields + ['time'] + tcp_fields + ['payload','payload_raw','payload_hex']
# Create blank DataFrame
df = pd.DataFrame(columns=dataframe_fields)
for packet in pcap[IP]:
# Field array for each row of DataFrame
field_values = []
# Add all IP fields to dataframe
for field in ip_fields:
if field == 'options':
# Retrieving number of options defined in IP Header
field_values.append(len(packet[IP].fields[field]))
else:
field_values.append(packet[IP].fields[field])
field_values.append(packet.time)
layer_type = type(packet[IP].payload)
for field in tcp_fields:
try:
if field == 'options':
field_values.append(len(packet[layer_type].fields[field]))
else:
field_values.append(packet[layer_type].fields[field])
except:
field_values.append(None)
# Append payload
field_values.append(len(packet[layer_type].payload))
field_values.append(packet[layer_type].payload.original)
field_values.append(binascii.hexlify(packet[layer_type].payload.original))
# Add row to DF
df_append = pd.DataFrame([field_values], columns=dataframe_fields)
df = pd.concat([df, df_append], axis=0)
# Reset Index
df = df.reset_index()
# Drop old index column
df = df.drop(columns="index")
frequent_address = df['src'].describe()['top']
import matplotlib.pyplot as plt
# Group by Source Address and Payload Sum
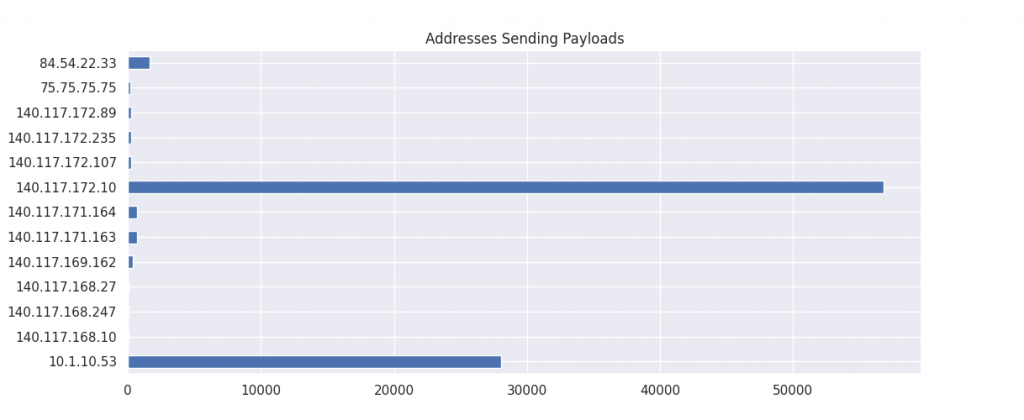
source_addresses = df.groupby("src")['payload'].sum()
source_addresses.plot(kind='barh',title="Addresses Sending Payloads",figsize=(8,5))
plt.show()
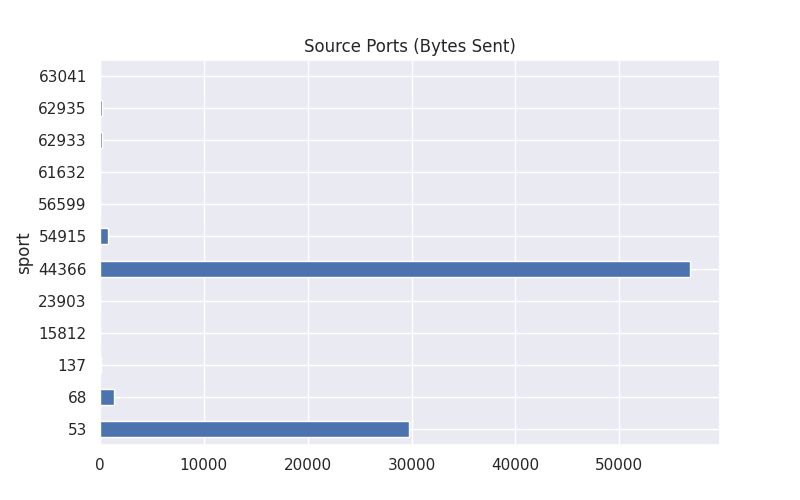
# Group by Source Port and Payload Sum
source_payloads = df.groupby("sport")['payload'].sum()
source_payloads.plot(kind='barh',title="Source Ports (Bytes Sent)",figsize=(8,5))
plt.show()
frequent_address_df = df[df['src'] == frequent_address]
x = frequent_address_df['payload'].tolist()
sns.barplot(x="time", y="payload", data=frequent_address_df[['payload','time']],
label="Total", color="b").set_title("History of bytes sent by most frequent address")
plt.show()
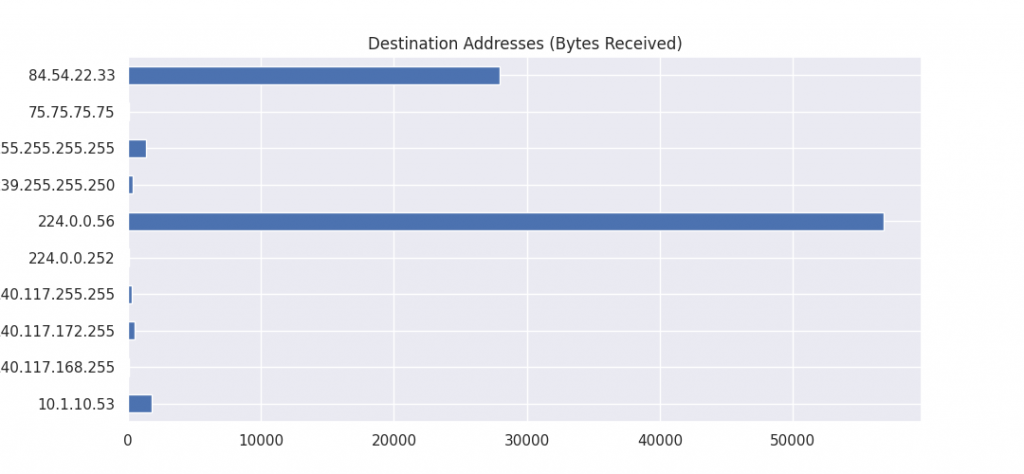
destination_addresses = df.groupby("dst")['payload'].sum()
destination_addresses.plot(kind='barh', title="Destination Addresses (Bytes Received)",figsize=(8,5))
plt.show()
source_payloads = df.groupby("sport")['payload'].sum()
source_payloads.plot(kind='barh',title="Source Ports (Bytes Sent)",figsize=(8,5))
plt.show()
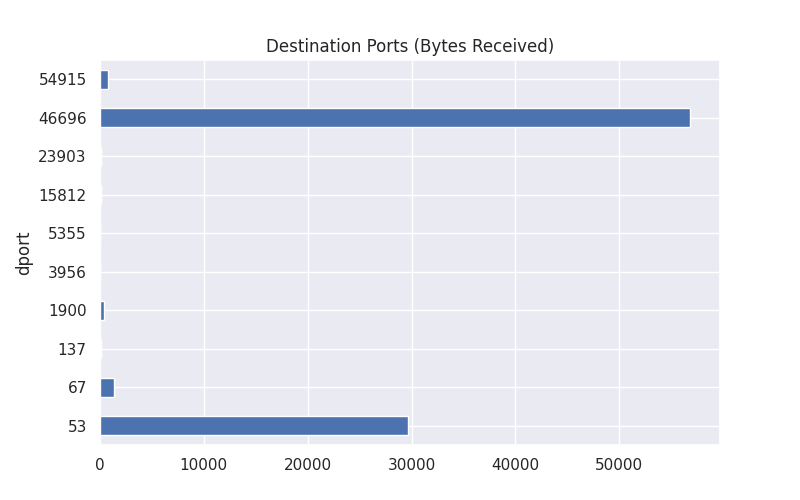
destination_payloads = df.groupby("dport")['payload'].sum()
destination_payloads.plot(kind='barh',title="Destination Ports (Bytes Received)",figsize=(8,5))
plt.show()
# Payload Investigation
# Create dataframe with only converation from most frequent address
frequent_address_df = df[df['src']==frequent_address]
# Only display Src Address, Dst Address, and group by Payload
frequent_address_groupby = frequent_address_df[['src','dst','payload']].groupby("dst")['payload'].sum()
# Plot the Frequent address is speaking to (By Payload)
frequent_address_groupby.plot(kind='barh',title="Most Frequent Address is Speaking To (Bytes)",figsize=(8,5))
plt.show()
'''
# Which address has excahnged the most amount of bytes with most frequent address
suspicious_ip = frequent_address_groupby.sort_values(ascending=False).index[0]
print(suspicious_ip, "May be a suspicious address")
# Create dataframe with only conversation from most frequent address and suspicious address
suspicious_df = frequent_address_df[frequent_address_df['dst']==suspicious_ip]
print(suspicious_df)
'''

