人物介紹: 綠豆伯
曾在科技產業待了大半輩子,知曉許多機器學習的分類方式,但不知何故,突然被公司辭退,一夕之間從有到無,只好轉行賣起以前國中下課時記憶中的味道,綠豆湯。經過多年,依然記得機器學習領域的知識,還將各種演算法應用到甜湯事業上面,但如何應用至今仍是個謎。
3-5 綠豆阿伯的過去
「嚇著你們了吧,你們一定在想一個賣甜湯的阿伯怎麼會這些東西,對吧?」阿伯悠悠地說出。
「倒是還好,不過感覺您老人家確實有些心事呢!」飛哥接下話。
阿伯笑了下說道:「倒也不是甚麼心事,只是還能偶爾接觸以前工作的事情也就滿意了。」眉間的皺紋看得出稍微舒緩了許多。
「不提那些了。我剛說 k-近鄰分類演算法 ,有個簡稱叫 KNN(k-nearest neighbor) algorithm ,用白話點的方式說就是 根據點跟點之間的距離與各點的類別,對新的點進行分類的一種方法 ,而k就是設定要納入後續分類的參考點的數量,實際意義為 該新的點跟其k個距離最近的點 。
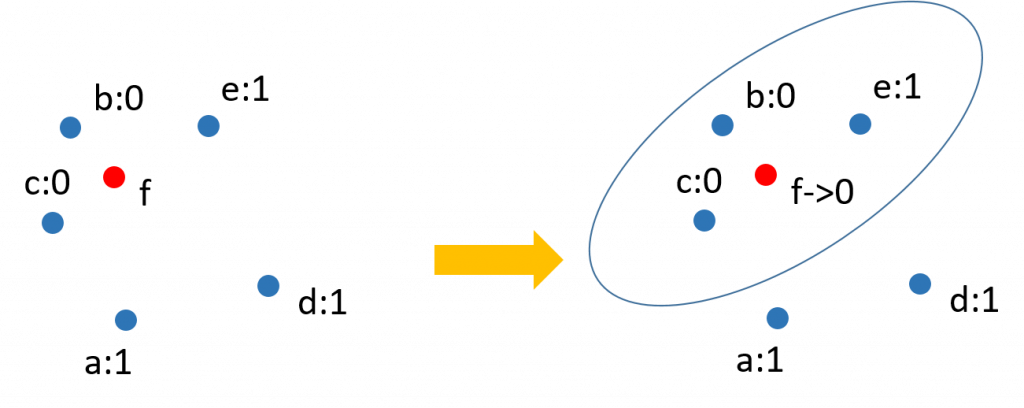
假設現在有五個點a、b、c、d、e(類別為1、0、0、1、1),設定k=3,現在有個新資料點f,對f最近的點是b、c、e,現在要判定f屬於哪一類時,就會統計b、c、e各個類別的數量,你可以想像是這三個點投票給f,結果0有兩票、1有一票,因此新資料點f就會被判定為類別0。
k-近鄰分類就會變成下面這個樣子,來,我擺綠豆給你看。」阿伯用甜湯勺將例子圈了起來。
小博看了有些傻眼,心中暗想:「可以不要玩食物嗎......?」又突然說起:「如果k的數量上升的話,是不是分類的會更準確啊?因為用來判定的點變多啦!。」
阿伯笑著說道:「對對對,頭腦真靈活,但是啊,k不能設定太大,不然用全部的點投票來判斷每個新的點就不準啦,如果1特別多的話,那每次新的點都會被判定為1的,我個人建議k要是奇數,而且資料不多的話,k設定3~9就蠻夠用的啦!」
「對耶,投票的時候如果出現偶數的話就不好判斷新的點是哪一類了。」小博想了想說了出來。
「先把綠豆湯喝掉吧,等下不冰就不好喝啦!晚點再聊。」阿伯說罷就回到攤前繼續幫其他客人弄甜湯。
小博邊望著地上的圖形,邊喝著綠豆湯,兀自出神。
資料參考:
https://www.itread01.com/content/1546211528.html

