select count(*) from top5 計算資料的總筆數,計算出來的筆數是 329999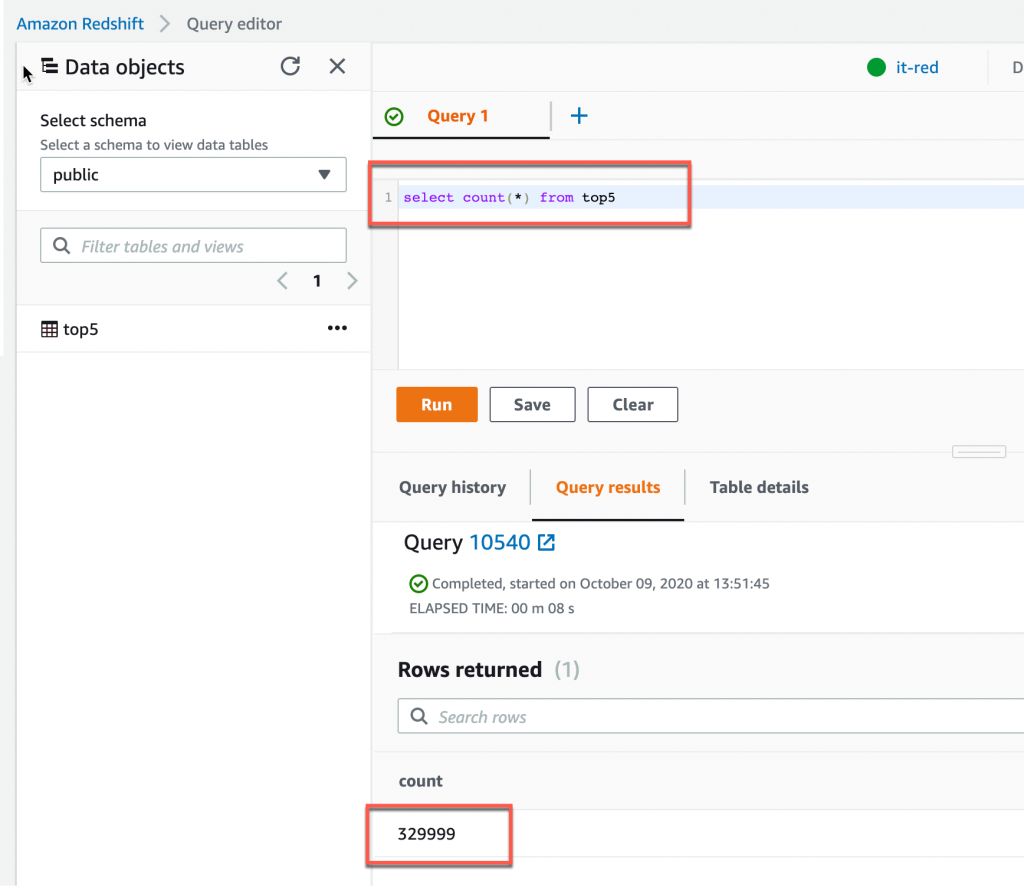
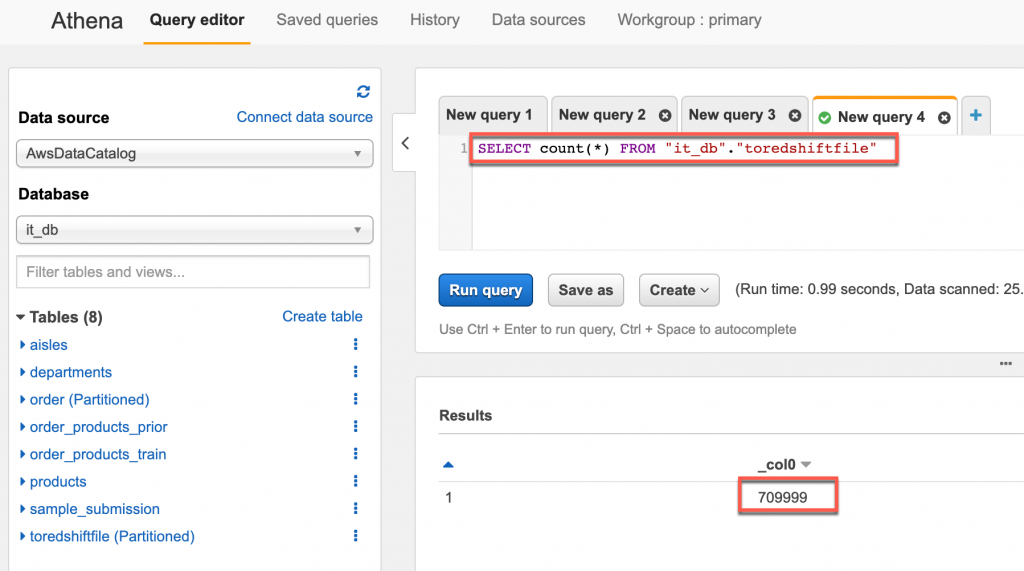
SELECT count(*) FROM "it_db"."toredshiftfile" 進行查詢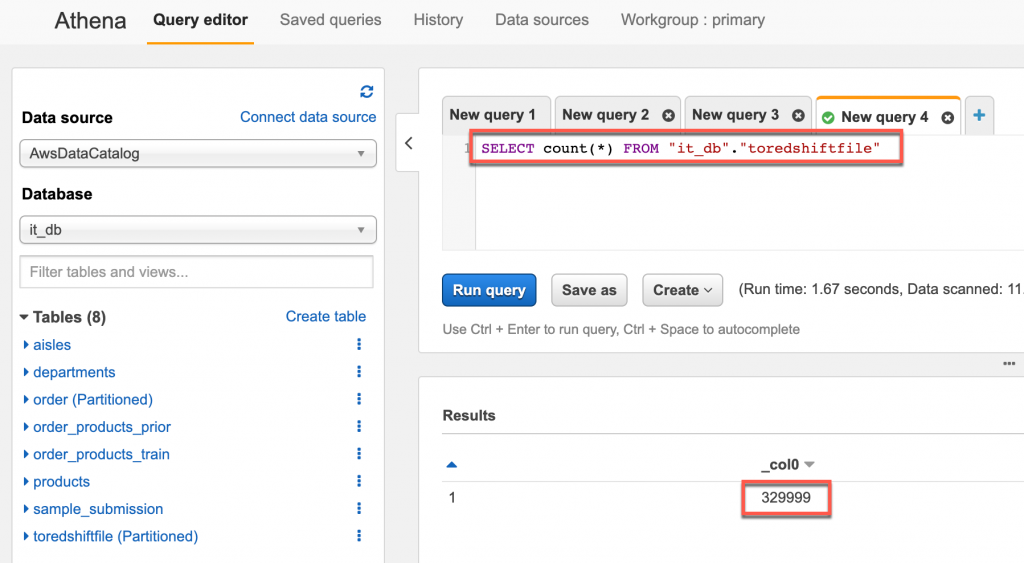
在來我們要驗證如果是第二天的資料同步到 Redshift 後是否會產生重複的資料,將第二天的資料放入 s3://it.sample.s3/toRedshiftFile/20201002/top5-2.csv 代表第二天的資料,接著運行 Crawler(top5-crawler),Crawler 運行成功後直接運行 ETL Job(it-to-redshift)
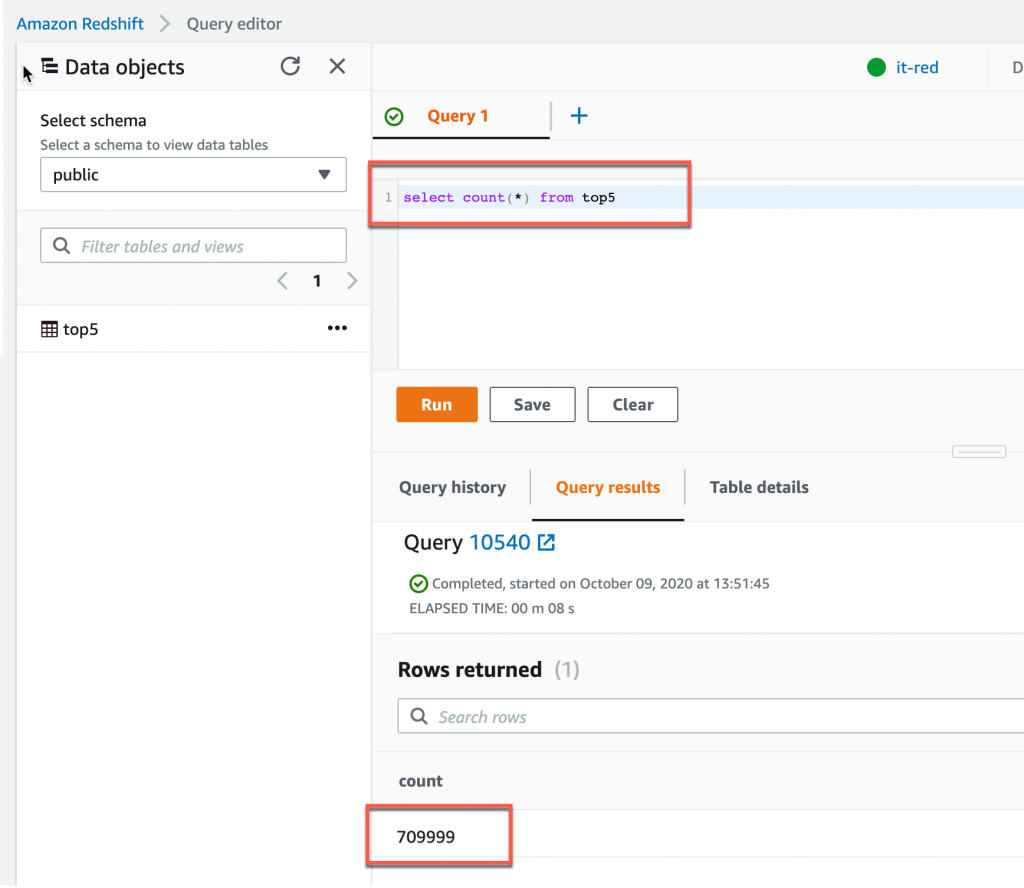
ETL Job(it-to-redshift) 運行完成後我們一樣到 Redshift 計算資料筆數,總筆數為 709999,如果總筆數為 1039998 那表示 ETL Job 的 Job bookmark 沒有設為 Enable,可以參考 Day 26 的教學


 iThome鐵人賽
iThome鐵人賽